I'm broadly interested in AI strategy and want to figure out the most effective interventions to get good AI outcomes.
Posts
Wiki Contributions
Comments
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempting: add a multiplier to account for algorithmic progress.
- But doing this multiplications seems importantly quite ambiguous.
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- People often use perplexity, but applying post training enhancements like scaffolding or chain of thought doesn’t improve perplexity but does improve downstream task performance.
- See https://arxiv.org/pdf/2312.07413 for examples of algorithmic changes that cause variable performance gains based on the benchmark.
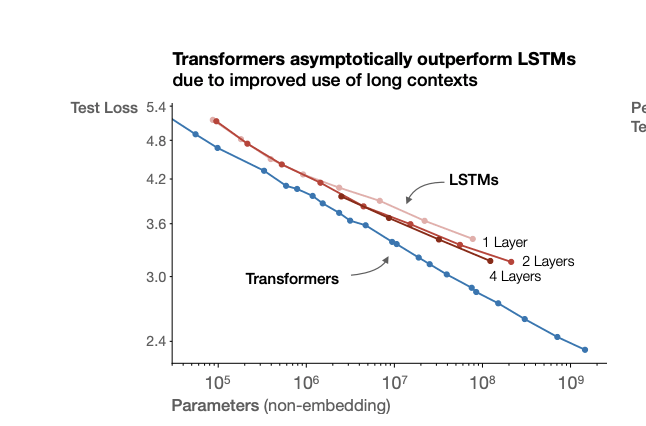
- Effective FLOPs often depend on the scale of the model you are testing. See graph below from: https://arxiv.org/pdf/2001.08361 - the compute efficiency from from LSTMs to transformers is not invariant to scale. This means that you can’t just say that the jump from X to Y is a factor of Z improvement on Capability per FLOP. This leads to all sorts of unintuitive properties of effective FLOPs. For example, if you are using 2016-next-token-validation-E-FLOPs, and LSTM scaling becomes flat on the benchmark, you could easily imagine that at very large scales you could get a 1Mx E-FLOP improvement from switching to transformers, even if the actual capability difference is small.
- If we move away from pretrained LLMs, I think E-FLOPs become even harder to define, e.g., if we’re able to build systems may be better at reasoning but worse at knowledge retrieval. E-FLOPs does not seem very adaptable.
- (these lines would need to parallel for the compute efficiency ratio to be scale invariant on test loss)
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- Users of E-FLOP often don’t specify the time, scale, or benchmark that they are talking about it with respect to, which makes it very confusing. In particular, this concept has picked up lots of steam and is used in the frontier lab scaling policies, but is not clearly defined in any of the documents.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- This specifies the metric, but doesn’t clearly specify any of (a) the techniques that count as the baseline, (b) the scale of the model where one is measuring E-FLOP with respect to, or (c) how they handle post training enhancements that don’t improve log loss but do dramatically improve downstream task capability.
- OpenAI on when they will run their evals: “This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough"
- They don’t define effective compute at all.
- Since there is significant ambiguity in the concept, it seems good to clarify what it even means.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- Basically, I think that E-FLOPs are confusing, and most of the time when we want to use flops, we’re usually just going to be better off talking directly about benchmark scores. For example, instead of saying “every 2x effective FLOP” say “every 5% performance increase on [simple benchmark to run like MMLU, GAIA, GPQA, etc] we’re going to run [more thorough evaluations, e.g. the ASL-3 evaluations]. I think this is much clearer, much less likely to have weird behavior, and is much more robust to changes in model design.
- It’s not very costly to run the simple benchmarks, but there is a small cost here.
- A real concern is that it is easier to game benchmarks than FLOPs. But I’m concerned that you could get benchmark gaming just the same with E-FLOPs because E-FLOPs are benchmark dependent — you could make your model perform poorly on the relevant benchmark and then claim that you didn’t scale E-FLOPs at all, even if you clearly have a broadly more capable model.
A3 in https://blog.heim.xyz/training-compute-thresholds/ also discusses limitations of effective FLOPs.
The fact that AIs will be able to coordinate well with each other, and thereby choose to "merge" into a single agent
My response: I agree AIs will be able to coordinate with each other, but "ability to coordinate" seems like a continuous variable that we will apply pressure to incrementally, not something that we should expect to be roughly infinite right at the start. Current AIs are not able to "merge" with each other.
Ability to coordinate being continuous doesn't preclude sufficiently advanced AIs acting like a single agent. Why would it need to be infinite right at the start?
And of course current AIs being bad at coordination is true, but this doesn't mean that future AIs won't be.
Thanks for the response!
If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures.
I very strongly disagree with this. "Evolution directly selecting over policies" in an ML context would be equivalent to iterated random search, which is essentially a zeroth-order approximation to gradient descent. Under certain simplifying assumptions, they are actually equivalent. It's the loss landscape an parameter-function map that are responsible for most of a learning process's inductive biases (especially for large amounts of data). See: Loss Landscapes are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent.
I think I understand these points, and I don't see how this contradicts what I'm saying. I'll try rewording.
Consider the following gaussian process:
![What is Gaussian Process? [Intuitive Explaination] | by Joanna | Geek Culture | Medium](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/hCy2NFrkedu3GngjZ/r4zixxawmhmz46hyorjb)
Each blue line represents a possible fit of the training data (the red points), and so which one of these is selected by a learning process is a question of inductive bias. I don't have a formalization, but I claim: if your data-distribution is sufficiently complicated, by default, OOD generalization will be poor.
Now, you might ask, how is this consistent with capabilities to generalizing? I note that they haven't generalized all that well so far, but once they do, it will be because the learned algorithm has found exploitable patterns in the world and methods of reasoning that generalize far OOD.
You've argued that there are different parameter-function maps, so evolution and NNs will generalize differently, this is of course true, but I think its besides the point. My claim is that doing selection over a dataset with sufficiently many proxies that fail OOD without a particularly benign inductive bias leads (with high probability) to the selection of function that fails OOD. Since most generalizations are bad, we should expect that we get bad behavior from NN behavior as well as evolution. I continue to think evolution is valid evidence for this claim, and the specific inductive bias isn't load bearing on this point -- the related load bearing assumption is the lack of a an inductive bias that is benign.
If we had reasons to think that NNs were particularly benign and that once NNs became sufficiently capable, their alignment would also generalize correctly, then you could make an argument that we don't have to worry about this, but as yet, I don't see a reason to think that a NN parameter function map is more likely to lead to inductive biases that pick a good generalization by default than any other set of inductive biases.
It feels to me as if your argument is that we understand neither evolution nor NN inductive biases, and so we can't make strong predictions about OOD generalization, so we are left with our high uncertainty prior over all of the possible proxies that we could find. It seems to me that we are far from being able to argue things like "because of inductive bias from the NN architecture, we'll get non-deceptive AIs, even if there is a deceptive basin in the loss landscape that could get higher reward."
I suspect you think bad misgeneralization happens only when you have a two layer selection process (and this is especially sharp when there's a large time disparity between these processes), like evolution setting up the human within lifetime learning. I don't see why you think that these types of functions would be more likely to misgeneralize.
(only responding to the first part of your comment now, may add on additional content later)
We haven't asked specific individuals if they're comfortable being named publicly yet, but if advisors are comfortable being named, I'll announce that soon. We're also in the process of having conversations with academics, AI ethics folks, AI developers at small companies, and other civil society groups to discuss policy ideas with them.
So far, I'm confident that our proposals will not impede the vast majority of AI developers, but if we end up receiving feedback that this isn't true, we'll either rethink our proposals or remove this claim from our advocacy efforts. Also, as stated in a comment below:
I’ve changed the wording to “Only a few technical labs (OpenAI, DeepMind, Meta, etc) and people working with their models would be regulated currently.” The point of this sentence is to emphasize that this definition still wouldn’t apply to the vast majority of AI development -- most AI development uses small systems, e.g. image classifiers, self driving cars, audio models, weather forecasting, the majority of AI used in health care, etc.
I’ve changed the wording to “Only a few technical labs (OpenAI, DeepMind, Meta, etc) and people working with their models would be regulated currently.” The point of this sentence is to emphasize that this definition still wouldn’t apply to the vast majority of AI development -- most AI development uses small systems, e.g. image classifiers, self driving cars, audio models, weather forecasting, the majority of AI used in health care, etc.
(ETA: these are my personal opinions)
Notes:
- We're going to make sure to exempt existing open source models. We're trying to avoid pushing the frontier of open source AI, not trying to put the models that are already out their back in the box, which I agree is intractable.
- These are good points, and I decided to remove the data criteria for now in response to these considerations.
- The definition of frontier AI is wide because it describes the set of models that the administration has legal authority over, not the set of models that would be restricted. The point of this is to make sure that any model that could be dangerous would be included in the definition. Some non-dangerous models will be included, because of the difficulty with predicting the exact capabilities of a model before training.
- We're planning to shift to recommending a tiered system in the future, where the systems in the lower tiers have a reporting requirement but not a licensing requirement.
- In order to mitigate the downside of including too many models, we have a fast track exemption for models that are clearly not dangerous but technically fall within the bounds of the definition.
- I don't expect this to impact the vast majority of AI developers outside the labs. I do think that open sourcing models at the current frontier is dangerous and want to prevent future extensions of the bar. Insofar as that AI development was happening on top of models produced by the labs, it would be affected.
- The threshold is a work in progress. I think it's likely that they'll be revised significantly throughout this process. I appreciate the input and pushback here.
Thanks!
I spoke with a lot of other AI governance folks before launching, in part due to worries about the unilateralists curse. I think that there is a chance this project ends up being damaging, either by being discordant with other actors in the space, committing political blunders, increasing the polarization of AI, etc. We're trying our best to mitigate these risks (and others) and are corresponding with some experienced DC folks who are giving us advice, as well as being generally risk-averse in how we act. That being said, some senior folks I've talked to are bearish on the project for reasons including the above.
DM me if you'd be interested in more details, I can share more offline.
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
This is the threshold for the government has the ability to say no to, and is deliberately set well before catastrophe.
I also think that one route towards AGI in the event that we try to create a global shutdown of AI progress is by building up capabilities on top of whatever the best open source model is, and so I'm hesitant to give up the government's ability to prevent the capabilities of the best open source model from going up.
The cutoffs also don't differentiate between sparse and dense models, so there's a fair bit of non-SOTA-pushing academic / corporate work that would fall under these cutoffs.
Thanks for pointing this out, I'll think about if there's a way to exclude sparse models, though I'm not sure if its worth the added complexity and potential for loopholes. I'm not sure how many models fall into this category -- do you have a sense? This aggregation of models has around 40 models above the 70B threshold.
It's worth noting that this (and the other thresholds) are in place because we need a concrete legal definition for frontier AI, not because they exactly pin down which AI models are capable of catastrophe. It's probable that none of the current models are capable of catastrophe. We want a sufficiently inclusive definition such that the licensing authority has the legal power over any model that could be catastrophically risky.
That being said -- Llama 2 is currently the best open-source model and it gets 68.9% on the MMLU. It seems relatively unimportant to regulate models below Llama 2 because anyone who wanted to use that model could just use Llama 2 instead. Conversely, models that are above Llama 2 capabilities are at the point where it seems plausible that they could be bootstrapped into something dangerous. Thus, our threshold was set just above the limit.
Of course, by the time this regulation would pass, newer open-source models are likely to come out, so we could potentially set the bar higher.
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.