I disagree. It can be rational to shift subjective probabilities by many orders of magnitude in response to very little new information.
What your example looks like is a nearly uniform prior over a very large space- nothing's wrong when we quickly update to believe that yesterday's lottery numbers are 04-15-21-31-36.
But the point where you need to halt, melt, and catch fire is if your prior assigns the vast majority of the probability mass to a small compact region, and then the evidence comes along and lands outside that region. That's the equivalent of starting out 99.99% confident that you know tomorrow's lottery numbers will begin with 01-02-03, and being proven wrong.
Yes, you're right, I wasn't thinking clearly, thanks for catching me. I think there's something to what I was trying to say, but I need to think about it through more carefully. I find the explanation that you give in your other comment convincing (that the point of the graphs is to clearly illustrate the principle).
Note: I am cross-posting this GiveWell Blog post, after consulting a couple of community members, because it is relevant to many topics discussed on Less Wrong, particularly efficient charity/optimal philanthropy and Pascal's Mugging. The post includes a proposed "solution" to the dilemma posed by Pascal's Mugging that has not been proposed before as far as I know. It is longer than usual for a Less Wrong post, so I have put everything but the summary below the fold. Also, note that I use the term "expected value" because it is more generic than "expected utility"; the arguments here pertain to estimating the expected value of any quantity, not just utility.
While some people feel that GiveWell puts too much emphasis on the measurable and quantifiable, there are others who go further than we do in quantification, and justify their giving (or other) decisions based on fully explicit expected-value formulas. The latter group tends to critique us - or at least disagree with us - based on our preference for strong evidence over high apparent "expected value," and based on the heavy role of non-formalized intuition in our decisionmaking. This post is directed at the latter group.
We believe that people in this group are often making a fundamental mistake, one that we have long had intuitive objections to but have recently developed a more formal (though still fairly rough) critique of. The mistake (we believe) is estimating the "expected value" of a donation (or other action) based solely on a fully explicit, quantified formula, many of whose inputs are guesses or very rough estimates. We believe that any estimate along these lines needs to be adjusted using a "Bayesian prior"; that this adjustment can rarely be made (reasonably) using an explicit, formal calculation; and that most attempts to do the latter, even when they seem to be making very conservative downward adjustments to the expected value of an opportunity, are not making nearly large enough downward adjustments to be consistent with the proper Bayesian approach.
This view of ours illustrates why - while we seek to ground our recommendations in relevant facts, calculations and quantifications to the extent possible - every recommendation we make incorporates many different forms of evidence and involves a strong dose of intuition. And we generally prefer to give where we have strong evidence that donations can do a lot of good rather than where we have weak evidence that donations can do far more good - a preference that I believe is inconsistent with the approach of giving based on explicit expected-value formulas (at least those that (a) have significant room for error (b) do not incorporate Bayesian adjustments, which are very rare in these analyses and very difficult to do both formally and reasonably).
The rest of this post will:
The approach we oppose: "explicit expected-value" (EEV) decisionmaking
We term the approach this post argues against the "explicit expected-value" (EEV) approach to decisionmaking. It generally involves an argument of the form:
Examples of the EEV approach to decisionmaking:
The crucial characteristic of the EEV approach is that it does not incorporate a systematic preference for better-grounded estimates over rougher estimates. It ranks charities/actions based simply on their estimated value, ignoring differences in the reliability and robustness of the estimates. Informal objections to EEV decisionmaking There are many ways in which the sort of reasoning laid out above seems (to us) to fail a common sense test.
In the remainder of this post, I present what I believe is the right formal framework for my objections to EEV. However, I have more confidence in my intuitions - which are related to the above observations - than in the framework itself. I believe I have formalized my thoughts correctly, but if the remainder of this post turned out to be flawed, I would likely remain in objection to EEV until and unless one could address my less formal misgivings.
Simple example of a Bayesian approach vs. an EEV approach
It seems fairly clear that a restaurant with 200 Yelp reviews, averaging 4.75 stars, ought to outrank a restaurant with 3 Yelp reviews, averaging 5 stars. Yet this ranking can't be justified in an EEV-style framework, in which options are ranked by their estimated average/expected value. How, in fact, does Yelp handle this situation?
Unfortunately, the answer appears to be undisclosed in Yelp's case, but we can get a hint from a similar site: BeerAdvocate, a site that ranks beers using submitted reviews. It states:
In other words, BeerAdvocate does the equivalent of giving each beer a set number (currently 10) of "average" reviews (i.e., reviews with a score of 3.66, which is the average for all beers on the site). Thus, a beer with zero reviews is assumed to be exactly as good as the average beer on the site; a beer with one review will still be assumed to be close to average, no matter what rating the one review gives; as the number of reviews grows, the beer's rating is able to deviate more from the average.
To illustrate this, the following chart shows how BeerAdvocate's formula would rate a beer that has 0-100 five-star reviews. As the number of five-star reviews grows, the formula's "confidence" in the five-star rating grows, and the beer's overall rating gets further from "average" and closer to (though never fully reaching) 5 stars.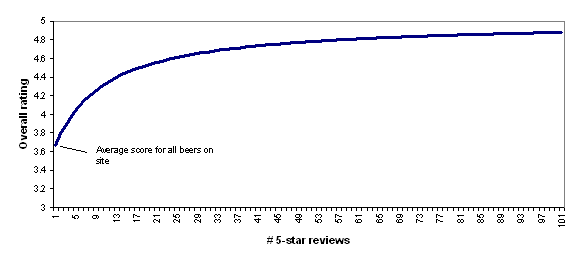
I find BeerAdvocate's approach to be quite reasonable and I find the chart above to accord quite well with intuition: a beer with a small handful of five-star reviews should be considered pretty close to average, while a beer with a hundred five-star reviews should be considered to be nearly a five-star beer.
However, there are a couple of complications that make it difficult to apply this approach broadly.
Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc.
As discussed above, we believe that both Giving What We Can and Back of the Envelope Guide to Philanthropy use forms of EEV analysis in arguing for their charity recommendations. However, when it comes to analyzing the cost-effectiveness estimates they invoke, the BeerAdvocate formula doesn't seem applicable: there is no "number of reviews" figure that can be used to determine the relative weights of the prior and the estimate.
Instead, we propose a model in which there is a normally (or log-normally) distributed "estimate error" around the cost-effectiveness estimate (with a mean of "no error," i.e., 0 for normally distributed error and 1 for lognormally distributed error), and in which the prior distribution for cost-effectiveness is normally (or log-normally) distributed as well. (I won't discuss log-normal distributions in this post, but the analysis I give can be extended by applying it to the log of the variables in question.) The more one feels confident in one's pre-existing view of how cost-effective an donation or action should be, the smaller the variance of the "prior"; the more one feels confident in the cost-effectiveness estimate itself, the smaller the variance of the "estimate error."
Following up on our 2010 exchange with Giving What We Can, we asked Dario Amodei to write up the implications of the above model and the form of the proper Bayesian adjustment. You can see his analysis here. The bottom line is that when one applies Bayes's rule to obtain a distribution for cost-effectiveness based on (a) a normally distributed prior distribution (b) a normally distributed "estimate error," one obtains a distribution with
The following charts show what this formula implies in a variety of different simple hypotheticals. In all of these, the prior distribution has mean = 0 and standard deviation = 1, and the estimate has mean = 10, but the "estimate error" varies, with important effects: an estimate with little enough estimate error can almost be taken literally, while an estimate with large enough estimate error ends ought to be almost ignored.
In each of these charts, the black line represents a probability density function for one's "prior," the red line for an estimate (with the variance coming from "estimate error"), and the blue line for the final probability distribution, taking both the prior and the estimate into account. Taller, narrower distributions represent cases where probability is concentrated around the midpoint; shorter, wider distributions represent cases where the possibilities/probabilities are more spread out among many values. First, the case where the cost-effectiveness estimate has the same confidence interval around it as the prior: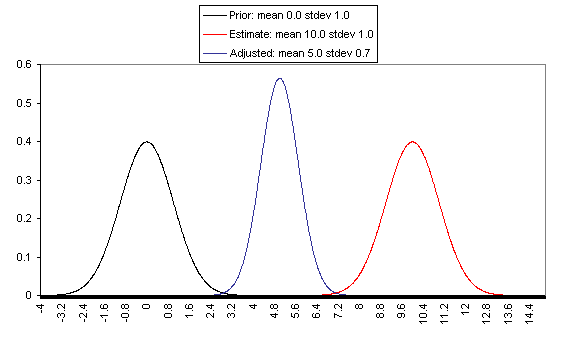
If one has a relatively reliable estimate (i.e., one with a narrow confidence interval / small variance of "estimate error,") then the Bayesian-adjusted conclusion ends up very close to the estimate. When we estimate quantities using highly precise and well-understood methods, we can use them (almost) literally.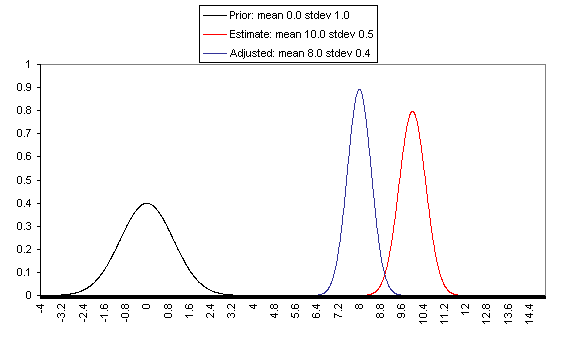
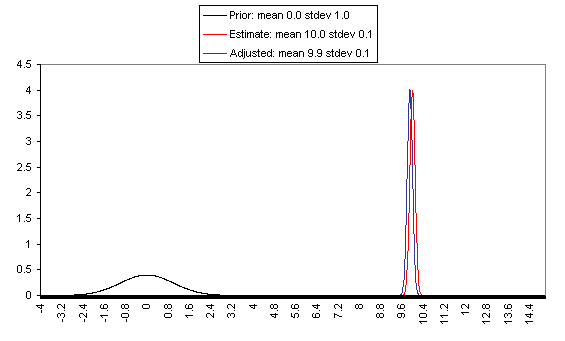
On the flip side, when the estimate is relatively unreliable (wide confidence interval / large variance of "estimate error"), it has little effect on the final expectation of cost-effectiveness (or whatever is being estimated). And at the point where the one-standard-deviation bands include zero cost-effectiveness (i.e., where there's a pretty strong probability that the whole cost-effectiveness estimate is worthless), the estimate ends up having practically no effect on one's final view.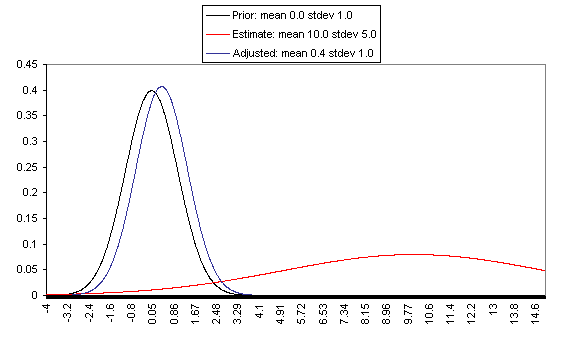
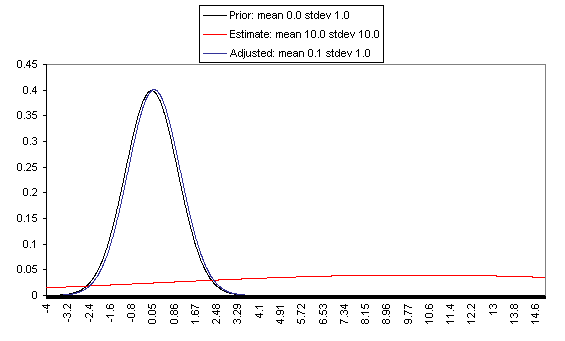
The details of how to apply this sort of analysis to cost-effectiveness estimates for charitable interventions are outside the scope of this post, which focuses on our belief in the importance of the concept of Bayesian adjustments. The big-picture takeaway is that just having the midpoint of a cost-effectiveness estimate is not worth very much in itself; it is important to understand the sources of estimate error, and the degree of estimate error relative to the degree of variation in estimated cost-effectiveness for different interventions.
Pascal's Mugging
Pascal's Mugging refers to a case where a claim of extravagant impact is made for a particular action, with little to no evidence:
Non-Bayesian approaches to evaluating these proposals often take the following form: "Even if we assume that this analysis is 99.99% likely to be wrong, the expected value is still high - and are you willing to bet that this analysis is wrong at 99.99% odds?"
However, this is a case where "estimate error" is probably accounting for the lion's share of variance in estimated expected value, and therefore I believe that a proper Bayesian adjustment would correctly assign little value where there is little basis for the estimate, no matter how high the midpoint of the estimate.
Say that you've come to believe - based on life experience - in a "prior distribution" for the value of your actions, with a mean of zero and a standard deviation of 1. (The unit type you use to value your actions is irrelevant to the point I'm making; so in this case the units I'm using are simply standard deviations based on your prior distribution for the value of your actions). Now say that someone estimates that action A (e.g., giving in to the mugger's demands) has an expected value of X (same units) - but that the estimate itself is so rough that the right expected value could easily be 0 or 2X. More specifically, say that the error in the expected value estimate has a standard deviation of X.
An EEV approach to this situation might say, "Even if there's a 99.99% chance that the estimate is completely wrong and that the value of Action A is 0, there's still an 0.01% probability that Action A has a value of X. Thus, overall Action A has an expected value of at least 0.0001X; the greater X is, the greater this value is, and if X is great enough then, then you should take Action A unless you're willing to bet at enormous odds that the framework is wrong."
However, the same formula discussed above indicates that Action X actually has an expected value - after the Bayesian adjustment - of X/(X^2+1), or just under 1/X. In this framework, the greater X is, the lower the expected value of Action A. This syncs well with my intuitions: if someone threatened to harm one person unless you gave them $10, this ought to carry more weight (because it is more plausible in the face of the "prior" of life experience) than if they threatened to harm 100 people, which in turn ought to carry more weight than if they threatened to harm 3^^^3 people (I'm using 3^^^3 here as a representation of an unimaginably huge number).
The point at which a threat or proposal starts to be called "Pascal's Mugging" can be thought of as the point at which the claimed value of Action A is wildly outside the prior set by life experience (which may cause the feeling that common sense is being violated). If someone claims that giving him/her $10 will accomplish 3^^^3 times as much as a 1-standard-deviation life action from the appropriate reference class, then the actual post-adjustment expected value of Action A will be just under (1/3^^^3) (in standard deviation terms) - only trivially higher than the value of an average action, and likely lower than other actions one could take with the same resources. This is true without applying any particular probability that the person's framework is wrong - it is simply a function of the fact that their estimate has such enormous possible error. An ungrounded estimate making an extravagant claim ought to be more or less discarded in the face of the "prior distribution" of life experience.
Generalizing the Bayesian approach
In the above cases, I've given quantifications of (a) the appropriate prior for cost-effectiveness; (b) the strength/confidence of a given cost-effectiveness estimate. One needs to quantify both (a) and (b) - not just quantify estimated cost-effectiveness - in order to formally make the needed Bayesian adjustment to the initial estimate.
But when it comes to giving, and many other decisions, reasonable quantification of these things usually isn't possible. To have a prior, you need a reference class, and reference classes are debatable.
It's my view that my brain instinctively processes huge amounts of information, coming from many different reference classes, and arrives at a prior; if I attempt to formalize my prior, counting only what I can name and justify, I can worsen the accuracy a lot relative to going with my gut. Of course there is a problem here: going with one's gut can be an excuse for going with what one wants to believe, and a lot of what enters into my gut belief could be irrelevant to proper Bayesian analysis. There is an appeal to formulas, which is that they seem to be susceptible to outsiders' checking them for fairness and consistency.
But when the formulas are too rough, I think the loss of accuracy outweighs the gains to transparency. Rather than using a formula that is checkable but omits a huge amount of information, I'd prefer to state my intuition - without pretense that it is anything but an intuition - and hope that the ensuing discussion provides the needed check on my intuitions.
I can't, therefore, usefully say what I think the appropriate prior estimate of charity cost-effectiveness is. I can, however, describe a couple of approaches to Bayesian adjustments that I oppose, and can describe a few heuristics that I use to determine whether I'm making an appropriate Bayesian adjustment.
Approaches to Bayesian adjustment that I oppose
I have seen some argue along the lines of "I have a very weak (or uninformative) prior, which means I can more or less take rough estimates literally." I think this is a mistake. We do have a lot of information by which to judge what to expect from an action (including a donation), and failure to use all the information we have is a failure to make the appropriate Bayesian adjustment. Even just a sense for the values of the small set of actions you've taken in your life, and observed the consequences of, gives you something to work with as far as an "outside view" and a starting probability distribution for the value of your actions; this distribution probably ought to have high variance, but when dealing with a rough estimate that has very high variance of its own, it may still be quite a meaningful prior.
I have seen some using the EEV framework who can tell that their estimates seem too optimistic, so they make various "downward adjustments," multiplying their EEV by apparently ad hoc figures (1%, 10%, 20%). What isn't clear is whether the size of the adjustment they're making has the correct relationship to (a) the weakness of the estimate itself (b) the strength of the prior (c) distance of the estimate from the prior. An example of how this approach can go astray can be seen in the "Pascal's Mugging" analysis above: assigning one's framework a 99.99% chance of being totally wrong may seem to be amply conservative, but in fact the proper Bayesian adjustment is much larger and leads to a completely different conclusion.
Heuristics I use to address whether I'm making an appropriate prior-based adjustment
Conclusion