Edit: conclusion here. I misinterpreted axiom 2 as weaker than it is; I now agree that the axioms imply the result (though I interpret the result somewhat differently).
I don't think you can make the broad analogy between what you're doing and what Harsanyi did that you're trying to make.
Harsanyi's postulate D is doing most of the work. Let's replace it with postulate D': if at least two individuals prefer situation X to situation Y, and none of the other individuals prefer Y to X, then X is preferred to Y from a social standpoint.
D' is weaker; the weighted sum of utilities satisfies it. But is it possible for another social welfare function to satisfy it? We'll need our new method to satisfy postulates A, B, and C.
Consider three individuals; Alice, Bob, and Charlie. There are four possible outcomes; W, X, Y, and Z. Alice's utilities are (0,0,1,1). Bob's utilities are (0,1,0,1). Charlie's utilities are (0,1,1,1). We notice that the social welfare function U=(0,1,1,1) satisfies D' but not D, and satisfies A, B, and C. If we construct a linear combination of Alice's, Bob's, and Charlie's utility functions, say by an equal weighting, we get V=(0,2,2,3), which satisfies D (and D'). Note the difference is that U does not respect Bob's preference for Z over Y, when Alice and Charlie are indifferent, or Alice's preference for Z over X, when Bob and Charlie are indifferent, whereas V does respect those preferences.
I haven't done any exploration yet on if we can construct social welfare functions that satisfy D' and seem reasonable in uncertain situations, but that example should be enough to demonstrate that a slight weakening of D destroys the result for certain situations.
I should also note that Harsanyi's E is narrowly written, which makes sense given the strong D. If you weaken D to D', you could smuggle the full strength of D back in by strengthening E to some E*, but if you leave it as covering the narrow situation that it currently does, or correspondingly weaken it to some E', or leave it out entirely, then there's nothing to worry about. (U trivially satisfies E because there's only one disagreement.)
Your Axiom 2 is much, much weaker than my D'; if D' is enough to remove the justification for a linear weighting, then I don't believe that your Axiom 2 is enough to justify the linear weighting. To be clearer: yes, linear combinations satisfy weaker versions of the axioms, but the power of Harsanyi is the claim that only linear combinations satisfy the axioms. When you weaken the axioms, you allow other functions that also do the job. (Note that T=(0,0,0,1) satisfies Axiom 2, but not D', at least for certainty.)
Now that I've started thinking about probability, note that Axiom 1 only constrains probabilistic behavior for each agent separately. You need postulates like he introduces in section III to make them agree on gambles, and I don't think weak postulates there will get very far, but I'll have to spend more time thinking about that.
(Hopefully that's the last of my edits, for now at least.)
You were looking at Harsanyi's explanation of a previous, similar theorem by Fleming, in section II of his paper. He proves the theorem I explained in the post in section III.
My axiom 2 was meant to include decisions involving uncertainty, like Harsanyi's postulates but unlike Fleming's postulates. Sorry if I did not make that clear.
A Friendly AI would have to be able to aggregate each person's preferences into one utility function. The most straightforward and obvious way to do this is to agree on some way to normalize each individual's utility function, and then add them up. But many people don't like this, usually for reasons involving utility monsters. If you are one of these people, then you better learn to like it, because according to Harsanyi's Social Aggregation Theorem, any alternative can result in the supposedly Friendly AI making a choice that is bad for every member of the population. More formally,
Axiom 1: Every person, and the FAI, are VNM-rational agents.
Axiom 2: Given any two choices A and B such that every person prefers A over B, then the FAI prefers A over B.
Axiom 3: There exist two choices A and B such that every person prefers A over B.
(Edit: Note that I'm assuming a fixed population with fixed preferences. This still seems reasonable, because we wouldn't want the FAI to be dynamically inconsistent, so it would have to draw its values from a fixed population, such as the people alive now. Alternatively, even if you want the FAI to aggregate the preferences of a changing population, the theorem still applies, but this comes with it's own problems, such as giving people (possibly including the FAI) incentives to create, destroy, and modify other people to make the aggregated utility function more favorable to them.)
Give each person a unique integer label from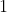 to
to  , where
, where  is the number of people. For each person
is the number of people. For each person 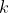 , let
, let 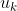 be some function that, interpreted as a utility function, accurately describes
be some function that, interpreted as a utility function, accurately describes 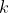 's preferences (there exists such a function by the VNM utility theorem). Note that I want
's preferences (there exists such a function by the VNM utility theorem). Note that I want 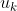 to be some particular function, distinct from, for instance,
to be some particular function, distinct from, for instance, 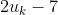 , even though
, even though 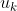 and
and 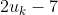 represent the same utility function. This is so it makes sense to add them.
represent the same utility function. This is so it makes sense to add them.
Theorem: The FAI maximizes the expected value of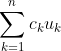 , for some set of scalars
, for some set of scalars 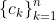 .
.
Actually, I changed the axioms a little bit. Harsanyi originally used “Given any two choices A and B such that every person is indifferent between A and B, the FAI is indifferent between A and B” in place of my axioms 2 and 3 (also he didn't call it an FAI, of course). For the proof (from Harsanyi's axioms), see section III of Harsanyi (1955), or section 2 of Hammond (1992). Hammond claims that his proof is simpler, but he uses jargon that scared me, and I found Harsanyi's proof to be fairly straightforward.
Harsanyi's axioms seem fairly reasonable to me, but I can imagine someone objecting, “But if no one else cares, what's wrong with the FAI having a preference anyway. It's not like that would harm us.” I will concede that there is no harm in allowing the FAI to have a weak preference one way or another, but if the FAI has a strong preference, that being the only thing that is reflected in the utility function, and if axiom 3 is true, then axiom 2 is violated.
proof that my axioms imply Harsanyi's: Let A and B be any two choices such that every person is indifferent between A and B. By axiom 3, there exists choices C and D such that every person prefers C over D. Now consider the lotteries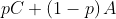 and
and 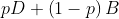 , for
, for 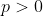 . Notice that every person prefers the first lottery to the second, so by axiom 2, the FAI prefers the first lottery. This remains true for arbitrarily small
. Notice that every person prefers the first lottery to the second, so by axiom 2, the FAI prefers the first lottery. This remains true for arbitrarily small 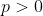 , so by continuity, the FAI must not prefer the second lottery for
, so by continuity, the FAI must not prefer the second lottery for 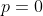 ; that is, the FAI must not prefer B over A. We can “sweeten the pot” in favor of B the same way, so by the same reasoning, the FAI must not prefer A over B.
; that is, the FAI must not prefer B over A. We can “sweeten the pot” in favor of B the same way, so by the same reasoning, the FAI must not prefer A over B.
So why should you accept my axioms?
Axiom 1: The VNM utility axioms are widely agreed to be necessary for any rational agent.
Axiom 2: There's something a little rediculous about claiming that every member of a group prefers A to B, but that the group in aggregate does not prefer A to B.
Axiom 3: This axiom is just to establish that it is even possible to aggregate the utility functions in a way that violates axiom 2. So essentially, the theorem is “If it is possible for anything to go horribly wrong, and the FAI does not maximize a linear combination of the people's utility functions, then something will go horribly wrong.” Also, axiom 3 will almost always be true, because it is true when the utility functions are linearly independent, and almost all finite sets of functions are linearly independent. There are terrorists who hate your freedom, but even they care at least a little bit about something other than the opposite of what you care about.
At this point, you might be protesting, “But what about equality? That's definitely a good thing, right? I want something in the FAI's utility function that accounts for equality.” Equality is a good thing, but only because we are risk averse, and risk aversion is already accounted for in the individual utility functions. People often talk about equality being valuable even after accounting for risk aversion, but as Harsanyi's theorem shows, if you do add an extra term in the FAI's utility function to account for equality, then you risk designing an FAI that makes a choice that humanity unanimously disagrees with. Is this extra equality term so important to you that you would be willing to accept that?
Remember that VNM utility has a precise decision-theoretic meaning. Twice as much utility does not correspond to your intuitions about what “twice as much goodness” means. Your intuitions about the best way to distribute goodness to people will not necessarily be good ways to distribute utility. The axioms I used were extremely rudimentary, whereas the intuition that generated "there should be a term for equality or something" is untrustworthy. If they come into conflict, you can't keep all of them. I don't see any way to justify giving up axioms 1 or 2, and axiom 3 will likely remain true whether you want it to or not, so you should probably give up whatever else you wanted to add to the FAI's utility function.
Citations:
Harsanyi, John C. "Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility." The Journal of Political Economy (1955): 309-321.
Hammond, Peter J. "Harsanyi’s utilitarian theorem: A simpler proof and some ethical connotations." IN R. SELTEN (ED.) RATIONAL INTERACTION: ESSAYS IN HONOR OF JOHN HARSANYI. 1992.