Suppose we decide that proving systems are too (NP) hard and we want to restrict agents to polynomial time. If an agent has access to a random coin, can it interactively prove that its opponent is cooperative?
I stumbled across an interesting class of agent while attempting to design a probabilistically proving bot for AlexMennen's contest. The agent below always cooperates with opponents who always cooperate back, (almost) always defects against opponents who always defect against them, and runs in probabilistic polynomial time if its opponent does as well.
def mimic_bot(opponent):
if random() > ε:
my_source = quine_my_source()
return eval(opponent, my_source) # do as your opponent does to you
else:
# unlikely, but necessary to break out of recursive simulations in polynomial time
return COOPERATE
This particular agent is a bit naïve, but more sophisticated versions (e.g ones that do not cooperate with CooperateBot) are possible. Does anyone have any insight on probabilistically proving opponents will cooperate?
I'm proud to announce the preprint of Robust Cooperation in the Prisoner's Dilemma: Program Equilibrium via Provability Logic, a joint paper with Mihaly Barasz, Paul Christiano, Benja Fallenstein, Marcello Herreshoff, Patrick LaVictoire (me), and Eliezer Yudkowsky.
This paper was one of three projects to come out of the 2nd MIRI Workshop on Probability and Reflection in April 2013, and had its genesis in ideas about formalizations of decision theory that have appeared on LessWrong. (At the end of this post, I'll include links for further reading.)
Below, I'll briefly outline the problem we considered, the results we proved, and the (many) open questions that remain. Thanks in advance for your thoughts and suggestions!
Background: Writing programs to play the PD with source code swap
(If you're not familiar with the Prisoner's Dilemma, see here.)
The paper concerns the following setup, which has come up in academic research on game theory: say that you have the chance to write a computer program X, which takes in one input and returns either Cooperate or Defect. This program will face off against some other computer program Y, but with a twist: X will receive the source code of Y as input, and Y will receive the source code of X as input. And you will be given your program's winnings, so you should think carefully about what sort of program you'd write!
Of course, you could simply write a program that defects regardless of its input; we call this program DefectBot, and call the program that cooperates on all inputs CooperateBot. But with the wealth of information afforded by the setup, you might wonder if there's some program that might be able to achieve mutual cooperation in situations where DefectBot achieves mutual defection, without thereby risking a sucker's payoff. (Douglas Hofstadter would call this a perfect opportunity for superrationality...)
Previously known: CliqueBot and FairBot
And indeed, there's a way to do this that's been known since at least the 1980s. You can write a computer program that knows its own source code, compares it to the input, and returns C if and only if the two are identical (and D otherwise). Thus it achieves mutual cooperation in one important case where it intuitively ought to: when playing against itself! We call this program CliqueBot, since it cooperates only with the "clique" of agents identical to itself.
There's one particularly irksome issue with CliqueBot, and that's the fragility of its cooperation. If two people write functionally analogous but syntactically different versions of it, those programs will defect against one another! This problem can be patched somewhat, but not fully fixed. Moreover, mutual cooperation might be the best strategy against some agents that are not even functionally identical, and extending this approach requires you to explicitly delineate the list of programs that you're willing to cooperate with. Is there a more flexible and robust kind of program you could write instead?
As it turns out, there is: in a 2010 post on LessWrong, cousin_it introduced an algorithm that we now call FairBot. Given the source code of Y, FairBot searches for a proof (of less than some large fixed length) that Y returns C when given the source code of FairBot, and then returns C if and only if it discovers such a proof (otherwise it returns D). Clearly, if our proof system is consistent, FairBot only cooperates when that cooperation will be mutual. But the really fascinating thing is what happens when you play two versions of FairBot against each other. Intuitively, it seems that either mutual cooperation or mutual defection would be stable outcomes, but it turns out that if their limits on proof lengths are sufficiently high, they will achieve mutual cooperation!
The proof that they mutually cooperate follows from a bounded version of Löb's Theorem from mathematical logic. (If you're not familiar with this result, you might enjoy Eliezer's Cartoon Guide to Löb's Theorem, which is a correct formal proof written in much more intuitive notation.) Essentially, the asymmetry comes from the fact that both programs are searching for the same outcome, so that a short proof that one of them cooperates leads to a short proof that the other cooperates, and vice versa. (The opposite is not true, because the formal system can't know it won't find a contradiction. This is a subtle but essential feature of mathematical logic!)
Generalization: Modal Agents
Unfortunately, FairBot isn't what I'd consider an ideal program to write: it happily cooperates with CooperateBot, when it could do better by defecting. This is problematic because in real life, the world isn't separated into agents and non-agents, and any natural phenomenon that doesn't predict your actions can be thought of as a CooperateBot (or a DefectBot). You don't want your agent to be making concessions to rocks that happened not to fall on them. (There's an important caveat: some things have utility functions that you care about, but don't have sufficient ability to predicate their actions on yours. In that case, though, it wouldn't be a true Prisoner's Dilemma if your values actually prefer the outcome (C,C) to (D,C).)
However, FairBot belongs to a promising class of algorithms: those that decide on their action by looking for short proofs of logical statements that concern their opponent's actions. In fact, there's a really convenient mathematical structure that's analogous to the class of such algorithms: the modal logic of provability (known as GL, for Gödel-Löb).
So that's the subject of this preprint: what can we achieve in decision theory by considering agents defined by formulas of provability logic?
More formally (skip the next two paragraphs if you're willing to trust me), we inductively define the class of "modal agents" as formulas using propositional variables and logical connectives and the modal operator (which represents provability in some base-level formal system like Peano Arithmetic), of the form
(which represents provability in some base-level formal system like Peano Arithmetic), of the form ) , where
, where 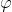 is fully modalized (i.e. all instances of variables are contained in an expression
is fully modalized (i.e. all instances of variables are contained in an expression 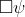 ), and with each
), and with each 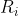 corresponding to a fixed modal agent of lower rank. For example, FairBot is represented by the modal formula
corresponding to a fixed modal agent of lower rank. For example, FairBot is represented by the modal formula 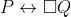 .
.
When two modal agents play against each other, the outcome is given by the unique fixed point of the system of modal statements, where the variables are identified with each other so that represents the expression
represents the expression =C) ,
, 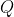 represents
represents =C) , and the
, and the 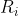 represent the actions of lower-rank modal agents against
represent the actions of lower-rank modal agents against 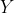 and vice-versa. (Modal rank is defined as a natural number, so this always bottoms out in a finite number of modal statements; also, we interpret outcomes as statements of provability in Peano Arithmetic, evaluated in the model where PA is consistent, PA+Con(PA) is consistent, and so on. See the paper for the actual details.)
and vice-versa. (Modal rank is defined as a natural number, so this always bottoms out in a finite number of modal statements; also, we interpret outcomes as statements of provability in Peano Arithmetic, evaluated in the model where PA is consistent, PA+Con(PA) is consistent, and so on. See the paper for the actual details.)
The nice part about modal agents is that there are simple tools for finding the fixed points without having to search through proofs; in fact, Mihaly and Marcello wrote up a computer program to deduce the outcome of the source-code-swap Prisoner's Dilemma between any two (reasonably simple) modal agents. These tools also made it much easier to prove general theorems about such agents.
PrudentBot: The best of both worlds?
Can we find a modal agent that seems to improve on FairBot? In particular, we should want at least the following properties:
It's nontrivial that such an agent exists: you may remember the post I wrote about the Masquerade agent, which is a modal agent that does almost all of those things (it doesn't cooperate with the original FairBot, though it does cooperate with some more complicated variants), and indeed we didn't find anything better until after we had Mihaly and Marcello's modal-agent-evaluator to help us.
But as it turns out, there is such an agent, and it's pretty elegant: we call it PrudentBot, and its modal version cooperates with another agent Y if and only if (there's a proof in Peano Arithmetic that Y cooperates with PrudentBot and there's a proof in PA+Con(PA) that Y defects against DefectBot). This agent can be seen to satisfy all of our criteria. But is it optimal among modal agents, by any reasonable criterion?
Results: Obstacles to Optimality
It turns out that, even within the class of modal agents, it's hard to formulate a definition of optimality that's actually true of something, and which meaningfully corresponds to our intuitions about the "right" decisions on decision-theoretic problems. (This intuition is not formally defined, so I'm using scare quotes.)
There are agents that give preferential treatment to DefectBot, FairBot, or even CooperateBot, compared to PrudentBot, though these agents are not ones you'd program in an attempt to win at the Prisoner's Dilemma. (For instance, one agent that rewards CooperateBot over PrudentBot is the agent that cooperates with Y iff PA proves that Y cooperates against DefectBot; we've taken to jokingly calling that agent TrollBot.) One might well suppose that a modal agent could still be optimal in the sense of making the "right" decision in every case, regardless of whether it's being punished for some other decision. However, this is not the only obstacle to a useful concept of optimality.
The second obstacle is that any modal agent only checks proofs at some finite number of levels on the hierarchy of formal systems, and agents that appear indistinguishable at all those levels may have obviously different "right" decisions. And thirdly, an agent might mimic another agent in such a way that the "right" decision is to treat the mimic differently from the agent it imitates, but in some cases one can prove that no modal agent can treat the two differently.
These three strikes appear to indicate that if we're looking to formalize more advanced decision theories, modal agents are too restrictive of a class to work with. We might instead allow things like quantifiers over agents, which would invalidate these specific obstacles, but may well introduce new ones (and certainly would make for more complicated proofs). But for a "good enough" algorithm on the original problem (assuming that the computer will have lots of computational resources), one could definitely do worse than submit a finite version of PrudentBot.
Why is this awesome, and what's next?
In my opinion, the result of Löbian cooperation deserves to be published for its illustration of Hofstadterian superrationality in action, apart from anything else! It's really cool that two agents reasoning about each other can in theory come to mutual cooperation for genuine reasons that don't have to involve being clones of each other (or other anthropic dodges). It's a far cry from a practical approach, of course, but it's a start: mathematicians always begin with a simplified and artificial model to see what happens, then add complications one at a time.
As for what's next: First, we don't actually know that there's no meaningful non-vacuous concept of optimality for modal agents; it would be nice to know that one way or another. Secondly, we'd like to see if some other class of agents contains a simple example with really nice properties (the way that classical game theory doesn't always have a pure Nash equilibrium, but always has a mixed one). Thirdly, we might hope that there's an actual implementation of a decision theory (TDT, UDT, etc) in the context of program equilibrium.
If we succeed in the positive direction on any of those, we'd next want to extend them in several important ways: using probabilistic information rather than certainty, considering more general games than the Prisoner's Dilemma (bargaining games have many further challenges, and games of more than two players could be more convoluted still), etc. I personally hope to work on such topics in future MIRI workshops.
Further Reading on LessWrong
Here are some LessWrong posts that have tackled similar material to the preprint: