I don't think there's anything that says a maximum entropy prior is what you get if you construct a maximum entropy prior for a weaker subset of assumptions, and then update based on the complement.
EDIT: Jaynes elaborates on the relationship between Bayes and maximum entropy priors here (warning, pdf).
Followup To: Foundations of Probability
In the previous post, we reviewed reasons why having probabilities is a good idea. These foundations defined probabilities as numbers following certain rules, like the product rule and the rule that mutually exclusive probabilities sum to 1 at most. These probabilities have to hang together as a coherent whole. But just because probabilities hang together a certain way, doesn't actually tell us what numbers to assign.
I can say a coin flip has P(heads)=0.5, or I can say it has P(heads)=0.999; both are perfectly valid probabilities, as long as P(tails) is consistent. This post will be about how to actually get to the numbers.
If the probabilities aren't fully determined by our desiderata, what do we need to determine the probabilities? More desiderata!
Our final desideratum is motivated by the perspective that our probability is based on some state of information. This is acknowledged explicitly in Cox's scheme, but is also just a physical necessity for any robot we build. Thus we add our new desideratum: Assign probabilities that are consistent with the information you have, but don't make up any extra information. It turns out this is enough to let us put numbers to the probabilities.
In its simplest form, this desideratum is a symmetry principle. If you have the exact same information about two events, you should assign them the same probability - giving them different probabilities would be making up extra information. So if your background information is "Flip a coin, the mutually exclusive and exhaustive probabilities are heads and tails," there is a symmetry between the labels "heads" and "tails," which given our new desideratum lets us assign each P=0.5.
Sometimes, though, we need to pull out the information theory. Using the fact that it doesn't produce information to split the probabilities up differently, we can specify something called "information entropy" (For more thoroughness, see chapter 11 of Jaynes). The entropy of a probability distribution is a function that measures how uncertain you are. If I flip a coin and don't know about the outcome, I have one bit of entropy. If I flip two coins, I have two bits of entropy. In this way, the entropy is like the amount of information you're "missing" about the coin flips.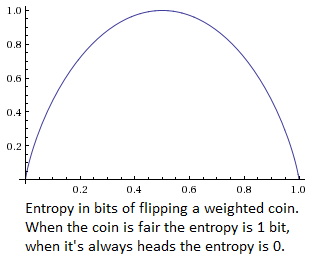
The mathematical expression for information entropy is that it's the sum of each probability multiplied by its log. Entropy = -Sum( P(x)·Log(P(x)) ), where the events x are mutually exclusive. Assigning probabilities is all about maximizing the entropy while obeying the constraints of our prior information.
Suppose we roll a 4-sided die. Our starting information consists of our knowledge that there are sides numbered 1 to 4 (events 1, 2, 3, and 4 are exhaustive), and the die will land on just one of these sides (they're mutually exclusive). This let's us write our information entropy as -P(1)·Log(P(1)) - P(2)·Log(P(2)) - P(3)·Log(P(3)) - P(4)·Log(P(4)).
Finding the probabilities is a maximization problem, subject to the constraints of our prior information. For the simple 4-sided die, our information just says that the probabilities have to add to 1. Simply knowing the fact that the entropy is concave down tells us that to maximize entropy we should split it up as evenly as possible - each side has a 1/4 chance of showing.
That was pretty commonsensical. To showcase the power of maximizing information entropy, we can add an extra constraint.
If we have additional knowledge that the average roll of our die is 3, then we want to maximize -P(1)·Log(P(1)) - P(2)·Log(P(2)) - P(3)·Log(P(3)) - P(4)·Log(P(4)), given that the sum is 1 and the average is 3. We can either plug in the constraints and set partial derivatives to zero, or we can use a maximization technique like Lagrange multipliers.
When we do this (again, more details in Jaynes ch. 11), it turns out the the probability distribution is shaped like an exponential curve. Which was unintuitive to me - my intuition likes straight lines. But it makes sense if you think about the partial derivative of the information entropy: 1+Log(P) = [some Lagrange multiplier constraints]. The steepness of the exponential controls how shifted the average roll is.
The need for this extra desideratum has not always been obvious. People are able to intuitively figure out that a fair coin lands heads with probability 0.5. Seeing that their intuition is so useful, some people include that intuition as a fundamental part of their method of probability. The counter to this is to focus on constructing a robot, which only has those intuitions we can specify unambiguously.
Another alternative to assigning probabilities based on maximum entropy is to pick a standard prior and use that. Sometimes this works wonderfully - it would be silly to rederive the binomial distribution every time you run into a coin-flipping problem. But sometimes people will use a well-known prior even if it doesn't match the information they have, just because their procedure is "use a well-known prior." The only way to be safe from that mistake and from interminable disputes over "which prior is right" is to remember that a prior is only correct insofar as it captures some state of information.
Next post, we will finally get to the problem of logical uncertainty, which will shake our foundations a bit. But I really like the principle of not making up information - even a robot that can't do hard math problems can aspire to not make up information.
Part of the sequence Logical Uncertainty
Previous Post: Foundations of Probability
Next post: Logic as Probability