This is a good introduction; however, by representing the outcomes as just "+" and "-" you greatly simply the range of possible utility functions, and so force SUDT to make some controversial decisions (basically to accept the counterfactual mugging). The key issue is that your decider can give no special preferences to good or bad outcomes in his own world (a world the decider knows he occupies) versus other worlds (ones which the decider knows he doesn't occupy).
Suppose instead that the decider has an outcome space with four outcomes "+Me", "-Me", "+NotMe", "-NotMe". Here, "+Me" represents a good singularity which the decider himself will get to enjoy, as opposed to "-Me" which is a bad singularity (such as an unfriendly AI which tortures the decider for the next billion years). The outcomes "+NotMe" and "-NotMe" also represent positive and negative singularities, but in worlds which the decider himself doesn't inhabit. Assume that u(+Me) > u(+NotMe) > u(-Me), and also that u(+NotMe) = u(-NotMe), because the decider doesn't care about worlds that he doesn't belong to (from the point of view of his decisions, it's exactly like they don't exist).
Then, in the counterfactual mugging, when approached by Omega, the decider knows he is in a world where the coin has fallen Heads, so he picks the policy which maximizes utility for such worlds: in short he chooses "H" rather than "T". This increases the probability of -NotMe as opposed to +NotMe, but as we've seen, the decider doesn't care about that.
Here's a possible objection: By selecting "H", the decider is condemning lots of other versions or analogues of himself (in other possible worlds where Omega didn't approach him), and his utility function might care about this. On the other hand, he might also reason like this "Analogues of me still aren't me: I still care much more about whether I get tortured than whether all those analogues do. I still pick H".
In short, I don't think SUDT (or UDT) by itself solves the problem of counterfactual mugging. Relative to one utility function it looks quite reasonable to accept the mugging, whereas relative to another utility function it is reasonable to reject it. Perhaps SUDT also needs to specify a rule for selecting utility functions (e.g. some sort of disinterested "veil of ignorance" on the decider's identity, or an equivalent ban on utilities which sneak it in a selfish or self-interested term).
In short, I don't think SUDT (or UDT) by itself solves the problem of counterfactual mugging. [...] Perhaps SUDT also needs to specify a rule for selecting utility functions (e.g. some sort of disinterested "veil of ignorance" on the decider's identity, or an equivalent ban on utilities which sneak it in a selfish or self-interested term).
I'll first give an answer to a relatively literal reading of your comment, and then one to what IMO you are "really" getting at.
Answer to a literal reading: I believe that what you value is part of ...
The best approach I know for thinking about anthropic problems is Wei Dai's Updateless Decision Theory (UDT). We aren't yet able to solve all problems that we'd like to—for example, when it comes to game theory, the only games we have any idea how to solve are very symmetric ones—but for many anthropic problems, UDT gives the obviously correct solution. However, UDT is somewhat underspecified, and cousin_it's concrete models of UDT based on formal logic are rather heavyweight if all you want is to figure out the solution to a simple anthropic problem.
In this post, I introduce a toy decision theory, Simple Updateless Decision Theory or SUDT, which is most definitely not a replacement for UDT but makes it easy to formally model and solve the kind of anthropic problems that we usually apply UDT to. (And, of course, it gives the same solutions as UDT.) I'll illustrate this with a few examples.
This post is a bit boring, because all it does is to take a bit of math that we already implicitly use all the time when we apply updateless reasoning to anthropic problems, and spells it out in excruciating detail. If you're already well-versed in that sort of thing, you're not going to learn much from this post. The reason I'm posting it anyway is that there are things I want to say about updateless anthropics, with a bit of simple math here and there, and while the math may be intuitive, the best thing I can point to in terms of details are the posts on UDT, which contain lots of irrelevant complications. So the main purpose of this post is to save people from having to reverse-engineer the simple math of SUDT from the more complex / less well-specified math of UDT.
(I'll also argue that Psy-Kosh's non-anthropic problem is a type of counterfactual mugging, I'll use the concept of l-zombies to explain why UDT's response to this problem is correct, and I'll explain why this argument still works if there aren't any l-zombies.)
*
I'll introduce SUDT by way of a first example: the counterfactual mugging. In my preferred version, Omega appears to you and tells you that it has thrown a very biased coin, which had only a 1/1000 chance of landing heads; however, in this case, the coin has in fact fallen heads, which is why Omega is talking to you. It asks you to choose between two options, (H) and (T). If you choose (H), Omega will create a Friendly AI; if you choose (T), it will destroy the world. However, there is a catch: Before throwing the coin, Omega made a prediction about which of these options you would choose if the coin came up heads (and it was able to make a highly confident prediction). If the coin had come up tails, Omega would have destroyed the world if it's predicted that you'd choose (H), and it would have created a Friendly AI if it's predicted (T). (Incidentally, if it hadn't been able to make a confident prediction, it would just have destroyed the world outright.)
In this example, we are considering two possible worlds: and
and  . We write
. We write 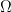 (no pun intended) for the set of all possible worlds; thus, in this case,
(no pun intended) for the set of all possible worlds; thus, in this case, 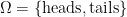 . We also have a probability distribution over
. We also have a probability distribution over 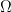 , which we call
, which we call  . In our example,
. In our example,  and
and  .
.
In the counterfactual mugging, there is only one situation you might find yourself in in which you need to make a decision, namely when Omega tells you that the coin has fallen heads. In general, we write for the set of all possible situations in which you might need to make a decision; the
for the set of all possible situations in which you might need to make a decision; the  stands for the information available to you, including both sensory input and your memories. In our case, we'll write
stands for the information available to you, including both sensory input and your memories. In our case, we'll write  , where
, where  is the single situation where you need to make a decision.
is the single situation where you need to make a decision.
For every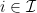 , we write
, we write  for the set of possible actions you can take if you find yourself in situation
for the set of possible actions you can take if you find yourself in situation 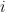 . In our case,
. In our case, . A policy (or "plan") is a function
. A policy (or "plan") is a function 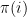 that associates to every situation
that associates to every situation 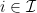 an action
an action  to take in this situation. We write
to take in this situation. We write 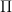 for the set of all policies. In our case,
for the set of all policies. In our case, 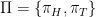 , where
, where  and
and 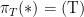 .
.
Next, there is a set of outcomes, , which specify all the features of what happens in the world that make a difference to our final goals, and the outcome function
, which specify all the features of what happens in the world that make a difference to our final goals, and the outcome function  , which for every possible world
, which for every possible world  and every policy
and every policy 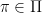 specifies the outcome
specifies the outcome 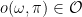 that results from executing
that results from executing  in the world
in the world  . In our case,
. In our case,  (standing for FAI and DOOM), and
(standing for FAI and DOOM), and  and
and 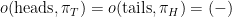 .
.
Finally, we have a utility function . In our case,
. In our case,  and
and 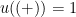 . (The exact numbers don't really matter, as long as
. (The exact numbers don't really matter, as long as  , because utility functions don't change their meaning under affine transformations, i.e. when you add a constant to all utilities or multiply all utilities by a positive number.)
, because utility functions don't change their meaning under affine transformations, i.e. when you add a constant to all utilities or multiply all utilities by a positive number.)
Thus, an SUDT decision problem consists of the following ingredients: The sets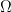 ,
,  and
and  of possible worlds, situations you need to make a decision in, and outcomes; for every
of possible worlds, situations you need to make a decision in, and outcomes; for every 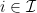 , the set
, the set  of possible actions in that situation; the probability distribution
of possible actions in that situation; the probability distribution  ; and the outcome and utility functions
; and the outcome and utility functions  and
and  . SUDT then says that you should choose a policy
. SUDT then says that you should choose a policy 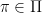 that maximizes the expected utility
that maximizes the expected utility  , where
, where 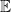 is the expectation with respect to
is the expectation with respect to  , and
, and  is the true world.
is the true world.
In our case, is just the probability of the good outcome
is just the probability of the good outcome 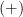 , according to the (prior) distribution
, according to the (prior) distribution  . For
. For  , that probability is 1/1000; for
, that probability is 1/1000; for  , it is 999/1000. Thus, SUDT (like UDT) recommends choosing (T).
, it is 999/1000. Thus, SUDT (like UDT) recommends choosing (T).
If you set up the problem in SUDT like that, it's kind of hidden why you could possibly think that's not the right thing to do, since we aren't distinguishing situations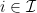 that are "actually experienced" in a particular possible world
that are "actually experienced" in a particular possible world  ; there's nothing in the formalism that reflects the fact that Omega never asks us for our choice if the coin comes up tails. In my post on l-zombies, I've argued that this makes sense because even if there's no version of you that actually consciously experiences being in the heads world, this version still exists as a Turing machine and the choices that it makes influence what happens in the real world. If all mathematically possible experiences exist, so that there aren't any l-zombies, but some experiences are "experienced more" (have more "magical reality fluid") than others, the argument is even clearer—even if there's some anthropic sense in which, upon being told that the coin fell heads, you can conclude that you should assign a high probability of being in the heads world, the same version of you still exists in the tails world, and its choices influence what happens there. And if everything is experienced to the same degree (no magical reality fluid), the argument is clearer still.
; there's nothing in the formalism that reflects the fact that Omega never asks us for our choice if the coin comes up tails. In my post on l-zombies, I've argued that this makes sense because even if there's no version of you that actually consciously experiences being in the heads world, this version still exists as a Turing machine and the choices that it makes influence what happens in the real world. If all mathematically possible experiences exist, so that there aren't any l-zombies, but some experiences are "experienced more" (have more "magical reality fluid") than others, the argument is even clearer—even if there's some anthropic sense in which, upon being told that the coin fell heads, you can conclude that you should assign a high probability of being in the heads world, the same version of you still exists in the tails world, and its choices influence what happens there. And if everything is experienced to the same degree (no magical reality fluid), the argument is clearer still.
*
From Vladimir Nesov's counterfactual mugging, let's move on to what I'd like to call Psy-Kosh's probably counterfactual mugging, better known as Psy-Kosh's non-anthropic problem. This time, you're not alone: Omega gathers you together with 999,999 other advanced rationalists, all well-versed in anthropic reasoning and SUDT. It places each of you in a separate room. Then, as before, it throws a very biased coin, which has only a 1/1000 chance of landing heads. If the coin does land heads, then Omega asks all of you to choose between two options, (H) and (T). If the coin falls tails, on the other hand, Omega chooses one of you at random and asks that person to choose between (H) and (T). If the coin lands heads and you all choose (H), Omega will create a Friendly AI; same if the coin lands tails, and the person who's asked chooses (T); else, Omega will destroy the world.
We'll assume that all of you prefer a positive FOOM over a gloomy DOOM, which means that all of you have the same values as far as the outcomes of this little dilemma are concerned: , as before, and all of you have the same utility function, given by
, as before, and all of you have the same utility function, given by  and
and 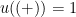 . As long as that's the case, we can apply SUDT to find a sensible policy for everybody to follow (though when there is more than one optimal policy, and the different people involved can't talk to each other, it may not be clear how one of the policies should be chosen).
. As long as that's the case, we can apply SUDT to find a sensible policy for everybody to follow (though when there is more than one optimal policy, and the different people involved can't talk to each other, it may not be clear how one of the policies should be chosen).
This time, we have a million different people, who can in principle each make an independent decision about what to answer if Omega asks them the question. Thus, we have . Each of these people can choose between (H) and (T), so
. Each of these people can choose between (H) and (T), so 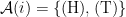 for every person
for every person 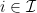 , and a policy
, and a policy  is a function that returns either (H) or (T) for every
is a function that returns either (H) or (T) for every 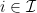 . Obviously, we're particularly interested in the policies
. Obviously, we're particularly interested in the policies  and
and  satisfying
satisfying 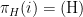 and
and  for all
for all 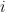 .
.
The possible worlds are,\dotsc,(%5Ctext%7Btails%7D,10^6)%5C%7D) , and their probabilities are
, and their probabilities are  and
and %29%20=%20%5Cfrac%7B999%7D%7B1000%7D%5Ccdot10^%7B-6%7D) . The outcome function is as follows:
. The outcome function is as follows:  ,
,  for
for  ,
, ,\pi)=(%2B)) if
if =(\mathrm{T})) , and
, and 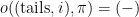 otherwise.
otherwise.
What does SUDT recommend? As in the counterfactual mugging, is the probability of the good outcome
is the probability of the good outcome 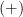 , under policy
, under policy  . For
. For  , the good outcome can only happen if the coin falls heads: in other words, with probability
, the good outcome can only happen if the coin falls heads: in other words, with probability  . If
. If 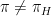 , then the good outcome can not happen if the coin falls heads, because in that case everybody gets asked, and at least one person chooses (T). Thus, in this case, the good outcome will happen only if the coin comes up tails and the randomly chosen person answers (T); this probability is
, then the good outcome can not happen if the coin falls heads, because in that case everybody gets asked, and at least one person chooses (T). Thus, in this case, the good outcome will happen only if the coin comes up tails and the randomly chosen person answers (T); this probability is  , where
, where  is the number of people answering (T). Clearly, this is maximized for
is the number of people answering (T). Clearly, this is maximized for  , where
, where  ; moreover, in this case we get the probability
; moreover, in this case we get the probability 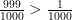 , which is better than for
, which is better than for 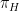 , so SUDT recommends the plan
, so SUDT recommends the plan  .
.
Again, when you set up the problem in SUDT, it's not even obvious why anyone might think this wasn't the correct answer. The reason is that if Omega asks you, and you update on the fact that you've been asked, then after updating, you are quite certain that the coin has landed heads: yes, your prior probability was only 1/1000, but if the coin has landed tails, the chances that you would be asked was only one in a million, so the posterior odds are about 1000:1 in favor of heads. So, you might reason, it would be best if everybody chose (H); and moreover, all the people in the other rooms will reason the same way as you, so if you choose (H), they will as well, and this maximizes the probability that humanity survives. This relies on the fact that the others will choose the same way as you, but since you're all good rationalists using the same decision theory, that's going to be the case.
But in the worlds where the coin comes up tails, and Omega chooses someone else than you, the version of you that gets asked for its decision still "exists"... as an l-zombie. You might think that what this version of you does or doesn't do doesn't influence what happens in the real world; but if we accept the argument from the previous paragraph that your decisions are "linked" to those of the other people in the experiment, then they're still linked if the version of you making the decision is an l-zombie: If we see you as a Turing machine making a decision, that Turing machine should reason, "If the coin came up tails and someone else was chosen, then I'm an l-zombie, but the person who is actually chosen will reason exactly the same way I'm doing now, and will come to the same decision; hence, my decision influences what happens in the real world even in this case, and I can't do an update and just ignore those possible worlds."
I call this the "probably counterfactual mugging" because in the counterfactual mugging, you are making your choice because of its benefits in a possible world that is ruled out by your observations, while in the probably counterfactual mugging, you're making it because of its benefits in a set of possible worlds that is made very improbable by your observations (because most of the worlds in this set are ruled out). As with the counterfactual mugging, this argument is just all the stronger if there are no l-zombies because all mathematically possible experiences are in fact experienced.
*
As a final example, let's look at what I'd like to call Eliezer's anthropic mugging: the anthropic problem that inspired Psy-Kosh's non-anthropic one. This time, you're alone again, except that there's many of you: Omega is creating a million copies of you. It flips its usual very biased coin, and if that coin falls heads, it places all of you in exactly identical green rooms. If the coin falls tails, it places one of you in a green room, and all the others in red rooms. It then asks all copies in green rooms to choose between (H) and (T); if your choice agrees with the coin, FOOM, else DOOM.
Our possible worlds are back to being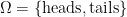 , with probabilities
, with probabilities  and
and  . We are also back to being able to make a choice in only one particular situation, namely when you're a copy in a green room:
. We are also back to being able to make a choice in only one particular situation, namely when you're a copy in a green room:  . Actions are
. Actions are  , outcomes
, outcomes  , utilities
, utilities  and
and 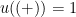 , and the outcome function is given by
, and the outcome function is given by  and
and 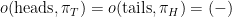 . In other words, from SUDT's perspective, this is exactly identical to the situation with the counterfactual mugging, and thus the solution is the same: Once more, SUDT recommends choosing (T).
. In other words, from SUDT's perspective, this is exactly identical to the situation with the counterfactual mugging, and thus the solution is the same: Once more, SUDT recommends choosing (T).
On the other hand, the reason why someone might think that (H) could be the right answer is closer to that for Psy-Kosh's probably counterfactual mugging: After waking up in a green room, what should be your posterior probability that the coin has fallen heads? Updateful anthropic reasoning says that you should be quite sure that it has fallen heads. If you plug those probabilities into an expected utility calculation, it comes out as in Psy-Kosh's case, heavily favoring (H).
But even if these are good probabilities to assign epistemically (to satisfy your curiosity about what the world probably looks like), in light of the arguments from the counterfactual and the probably counterfactual muggings (where updating definitely is the right thing to do epistemically, but plugging these probabilities into the expected utility calculation gives the wrong result), it doesn't seem strange to me to come to the conclusion that choosing (T) is correct in Eliezer's anthropic mugging as well.