Intuitively, this limitation could be addressed by hooking up the AIXItl's output channel to its source code. Unfortunately, if you do that, the resulting formalism is no longer AIXItl.
It sounds to me like, although such an agent would very quickly self-modify into something other than AIXItl, it would be AIXItl at least on the first timestep (despite its assumption that its output does not change its source code being incorrect).
I expect that such an agent would perform very poorly, because it doesn't start with a good model of self-modification, so the successor it replaces itself with would, with very high probability, not do anything useful. This is a problem for all agents that do not start off with detailed information about the environment, not just AIXI variants. The advantage that the example precommitment game player you provided has over AIXItl is not non-Cartesianism, but the fact that it was designed by someone who knows how the game mechanics work. It seems to me that the only way an agent that does not start off with strong assumptions about which program the environment is running could win is if self-modification is difficult enough that it could not accidentally self-modify into something useless before learning enough about its environment to protect itself.
My intuition is that the described AIXItl implementation fails because it's implementation is too low-level. A higher-level AIXItl can succeed though, so it's not a limitation in AIXItl. Consider the following program:
P1) Send the current machine state* as input to a 'virtual' AIXItl.
P2) Read the output of this AIXItl step, which will be a new program.
P3) Write a back up of the current machine state*. This could be in a non-executing register, for example.
P4) Replace the machine's state (but not the backup!) to match the program provided by AIXItl.
Now, as AlexMennen notes, this machine will no longer be AIXItl and in all probability it will 'brick' itself. However, we can rectify this. The AIXItl agent is 'virtual' (ie. not directly hooked up to the machine's IO), so we can interpret its output programs in a safe way:
We can use a total language, such that all outputted programs eventually halt.
We can prevent the language having (direct) access to the backup.
We can append a "then reload the backup" instruction to all programs.
This is still AIXItl, not a "variant". It's just running on a rather complex virtual machine. From AIXItl's Cartesian point of view:
A1) Take in an observation, which will be provided in the form of a robot's configuration. A2) Output an action, in the form of a new robot configuration which will be run to completion. A3) GOTO 1.
From an embodied viewpoint, we can see that the robot AIXItl thinks it's programming doesn't exactly correspond to the robot which actually exists (in particular, it doesn't know that the real robot is also running AIXItl!). Also, where AIXItl measures time in terms of IO cycles, we can see that an arbitrary amount of time may pass between steps A1 and A2 (where AIXItl is 'thinking') and between steps A2 and A3 (where the robot is executing the new program, and AIXItl only exists in the backup).
This setup doesn't solve all Cartesian problems, for example AIXItl doesn't understand that it might die, it has no control over the backup (which a particularly egregious Omega might place restrictions on**) and the backup-and-restore scheme (just like anything else) might be interfered with by the environment. However, this article's main thrust is that a machine running AIXItl is unable to rewrite its code, which is false.
- Note that this doesn't need to be complete; in particular, we can ignore the current state of execution. Only the "code" and sensor data need to be included.
** With more effort, we could have AIXItl's output programs contain the backup and restore procedures, eg. validated by strong types. This would allow a choice of different backup strategies, depending on the environment (eg. "Omega wants this register to be empty, so I'll write my backup to this hard drive instead, and be sure to restore it afterwards")
As one of the objectors, I think I ought to respond. All of this seems correct to me; my objection was to the claim that the Solomonoff updating rule is incapable of learning these facts. Maybe I misunderstood what was being claimed originally?
All of this seems correct to me;
Hooray! I was hoping we'd be able to find some common ground.
My concerns with AIXI and AIXItl are largely of the form "this model doesn't quite capture what I'm looking for" and "AGI is not reduced to building better and better approximations of AIXI". These seem like fairly week and obvious claims to me, so I'm glad they are not contested.
(From some of the previous discussion, I was not sure that we agreed here.)
My objection was to the claim that the Solomonoff updating rule is incapable of learning these facts.
Cool. I make no such claim here.
Since you seem really interested in talking about Solomonoff induction and it's ability to deal with these situations, I'll say a few things that I think we can both agree upon. Correct me if I'm wrong:
- A Solomonoff inductor outside of a computable universe, with a search space including Turing machines large enough to compute this universe, and with access to sufficient information, will in the limit construct a perfect model of the universe.
- An AI sitting outside of a computable universe interacting only via I/O channels and using Solomonoff induction as above will in the limit have a perfect model of the universe, and will thus be able to act optimally.
- A Solomonoff inductor inside its universe cannot consider hypotheses that actually perfectly describe the universe.
- Agents inside the universe using Solomonoff induction thus lack the strict optimality-in-the-limit that an extra-universal AIXI would possess.
Does that mean they are dumb? No, of course not. Nothing that you can do inside the universe is going to give you the optimality principle of an AIXI that is actually sitting outside the universe using a hypercomputer. You can't get a perfect model of the universe from inside the universe, and it's unreasonable to expect that you should.
While doing Solomonoff induction inside the universe can never give you a perfect model, it can indeed get you a good computable approximation (one of the best computable approximations around, in fact).
(I assume we agree so far?)
The thing is, when we're inside a universe and we can't have that optimality principle, I already know how to build the best universe model that I can: I just do Bayesian updates using all my evidence. I don't need new intractable methods for building good environment models, because I already have one. The problem, of course, is that to be a perfect Bayesian, I need a good prior.
And in fact, Solomonoff induction is just Bayesian updating with a Komolgorov prior. So of course it will give you good results. As I stated here, I don't view my concerns with Solomonoff induction as an "induction problem" but rather as a "priors problem": Solomonoff induction works very well (and, indeed, is basically just Bayesian updating), but the question is, did it pick the right prior?
Maybe Komolgorov complexity priors will turn out to be the correct answer, but I'm far from convinced (for a number of reasons that go beyond the scope of this discussion). Regardless, though, Solomonoff induction surely gives you the best model you can get given the prior.
(In fact, the argument with AlexMennen is an argument about whether AIXItl's prior stating that it is absolutely impossible that the universe is a Turing machine with length > l is bad enough to hurt AIXItl. I won't hop into that argument today, but instead I will note that this line of argument does not seem like a good way to approach the question of which prior we should use.)
I'm not trying to condemn Solomonoff induction in this post. I'm trying to illustrate the fact that even if you could build an AIXItl, it wouldn't be an ideal agent.
There's one obvious way to embed AIXItl into its environment (hook its output register to its motor output channel) that prevents it from self-modifying, which results in failures. There's another way to embed AIXItl into its environment (hook its program registers to its output channel) that requires you to do a lot more work before the variant becomes useful.
Is it possible to make an AIXItl variant useful in the latter case? Sure, probably, but this seems like a pretty backwards way to go about studying self-modification when we could just use a toy model that was designed to study this problem in the first place.
As an aside, I'm betting that we disagree less than you think. I spent some time carefully laying out my concerns in this post, and alluding to other concerns that I didn't have time to cover (e.g., that the Legg-Hutter intelligence metric fails to capture some aspects of intelligence that I find important), in an attempt to make my position very clear. From your own response, it sounds like you largely agree with my concerns.
And yet, you still put very different words about very different concerns into my mouth when arguing with other people against positions that you believed I held.
I find this somewhat frustrating, and while I'm sure it was an honest mistake, I hope that you will be a bit more careful in the future.
From your own response, it sounds like you largely agree with my concerns.
Yup.
I'm not trying to condemn Solomonoff induction in this post... And yet, you still put very different words about very different concerns into my mouth when arguing with other people against positions that you believed I held.
When I was talking about positions I believe you have held (and may currently still hold?), I was referring to your words in a previous post:
the agent/environment separation is somewhat reminiscent of Cartesian dualism: any agent using this framework to reason about the world does not model itself as part of its environment. For example, such an agent would be unable to understand the concept of the environment interfering with its internal computations, e.g. by inducing errors in the agent’s RAM through heat.
I find this somewhat frustrating, and while I'm sure it was an honest mistake, I hope that you will be a bit more careful in the future.
I appreciate the way you've stated this concern. Comity!
Yeah, I stand by that quote. And yet, when I made my concerns more explicit:
Intuitively, this limitation could be addressed by hooking up the AIXItl's output channel to its source code. Unfortunately, if you do that, the resulting formalism is no longer AIXItl.
This is not just a technical quibble: We can say many useful things about AIXI, such as "the more input it gets the more accurate its environment model becomes". On the other hand, we can't say much at all about an agent that chooses its new source code: we can't even be sure whether the new agent will still have an environment model!
It may be possible to give an AIXItl variant access to its program registers and then train it such that it acts like an AIXItl most of the time, but such that it can also learn to win the Precommitment game. However, it’s not immediately obvious to us how to do this, or even whether it can be done. This is a possibility that we'd be interested in studying further.
You said you agree, but then still made claims like this:
Either (1) I am wrong and stupid; or (2) they are wrong and stupid.
It sounds like you retained an incorrect interpretation of my words, even after I tried to make them clear in the above post and previous comment. If you still feel that the intended interpretation is unclear, please let me know and I'll clarify further.
Intuitively, this limitation could be addressed by hooking up the AIXItl's output channel to its source code.
The text you've quoted in the parent doesn't seem to have anything to do with my point. I'm talking about plain vanilla AIXI/AIXItl. I've got nothing to say about self-modifying agents.
Let's take a particular example you gave:
such an agent would be unable to understand the concept of the environment interfering with its internal computations, e.g. by inducing errors in the agent’s RAM through heat.
Let's consider an AIXI with a Solomonoff induction unit that's already been trained to understand physics to the level that we understand it in an outside-the-universe way. It starts receiving bits and rapidly (or maybe slowly, depends on the reward stream, who cares) learns that its input stream is consistent with EM radiation bouncing off of nearby objects. Conveniently, there is a mirror nearby...
Solomonoff induction will generate confabulations about the Solomonoff induction unit of the agent, but all the other parts of the agent run on computable physics, e.g., the CCD camera that generates the input stream, the actuators that mediate the effect of the output voltage. Time to hack the input registers to max out the the reward stream!
Plain vanilla AIXI/AIXItl doesn't have a reward register. It has a reward channel. (It doesn't save its rewards anywhere, it only acts to maximize the amount of reward signal on the input channel.)
I agree that a vanilla AIXI would abuse EM radiation to flip bits on its physical input channel to get higher rewards.
AIXItl might be able to realize that the contents of its ram correlate with computations done by its Solomonoff inductor, but it won't believe that changing the RAM will change the results of induction, and it wouldn't pay a penny to prevent a cosmic ray from interfering with the inductor's code.
From AIXI's perspective, the code may be following along with the induction, but it isn't actually doing the induction, and (AIXI thinks) wiping the code isn't a big deal, because (AIXI thinks) it is a given that AIXI will act like AIXI in the future.
Now you could protest that AIXI will eventually learn to stop letting cosmic rays flip its bits because (by some miraculous coincidence) all such bit-flips result in lower expected rewards, and so it will learn to prevent them even while believing that the RAM doesn't implement the induction.
And when I point out that this isn't the case in all situations, you can call foul on games where it isn't the case.
But both of these objections are silly; it should be obvious that an AIXI in such a situation is non-optimal, and I'm still having trouble understanding why you think that AIXI is optimal under violations of ergodicity.
And then I quote V_V, which is how you know that this conversation is getting really surreal:
Then I don't think we actually disagree.
I mean, it was well known that the AIXI proof of optimality requred ergodicity, since the original Hutter's paper.
Plain vanilla AIXI/AIXItl doesn't have a reward register.
Yeah, I changed that while your reply was in progress.
More to come later...
ETA: Later is now!
I'm still having trouble understanding why you think that AIXI is optimal under violations of ergodicity.
I don't think that AIXI is optimal under violations of ergodicity; I'm not talking about the optimality of AIXI at all. I'm talking about whether or not the Solomonoff induction part is capable of prompting AIXI to preseve itself.
I'm going to try to taboo "AIXI believes" and "AIXI thinks". In hypothetical reality, the physically instantiated AIXI agent is a motherboard with sensors and actuators that are connected to the input and output pins, respectively, of a box labelled "Solomonoff Magic". This agent is in a room. Somewhere in the space of all possible programs there are two programs. The first is just the maximally compressed version of the second, i.e., the first and the second give the same outputs on all possible inputs. The second one in written in Java, with a front-end interpreter that translates the Java program into the native language of the Solomonoff unit. (Java plus a prefix-free coding, blar blar blar). This program contains a human-readable physics simulation and an observation prediction routine. The initial conditions of the physics simulation match hypothetical reality except that the innards of the CPU are replaced by a computable approximation, including things like waste heat and whatnot. The simulation uses the input to determine the part of the initial conditions that specifies simulated-AIXI's output voltages... ah! ah! ah! Found the Cartesian boundary! No matter how faithful the physics simulation is, AIXI only ever asks for one time-step at a time, so although the simulation' state propagates to simulated-AIXI's input voltages, it doesn't propagate all the way through to the output voltage.
Thank you for your patience, Nate. The outside view wins again.
The simulation uses the input to determine the part of the initial conditions that specifies simulated-AIXI's output voltages... ah! ah! ah! Found the Cartesian boundary! No matter how faithful the physics simulation is, AIXI only ever asks for one time-step at a time, so although the simulation' state propagates to simulated-AIXI's input voltages, it doesn't propagate all the way through to the output voltage.
Can you please expand?
Actually, I find myself in a state of uncertainty as a result of doing a close reading section 2.6 of the Gentle Introduction to AIXI in light of your comment here. You quoted Paul Christiano as saying
Recall the definition of AIXI: A will try to infer a simple program which takes A's outputs as input and provides A's inputs as output, and then choose utility maximizing actions with respect to that program.
EY, Nate, Rob, and various commenters here (including myself until recently) all seemed to take this as given. For instance, above I wrote:
The simulation uses the input [i.e., action choice fed in as required by expectimax] to determine the part of the initial conditions that specifies simulated-AIXI's output voltages [emphasis added]
On this "program-that-takes-action-choice-as-an-input" view (perhaps inspired by a picture like that on page 7 of the Gentle Introduction and surrounding text), a simulated event like, say, a laser cutter slicing AIXI's (sim-)physical instantiation in half, could sever the (sim-)causal connection from (sim-)AIXI's input wire to its output wire, and this event would not change the fact that the simulation specifies the voltage on the output wire from the expectimax action choice.
Your claim, if I understand you correctly, is that the AIXI formalism does not actually express this kind of back-and-forth state swapping. Rather, for any given universe-modeling program, it simulates forward from the specification of the (sim-)input wire voltage (or does something computationally equivalent), not from a specification of the (sim-)output wire voltage. There is some universe-model which simulates a computable approximation of all of (sim-)AIXI's physical state changes; once the end state of has been specified, real-AIXI gives zero weight all branches of the expectimax tree that do not have an action that matches the state of (sim-)AIXI's output wire.
Do I have that about right?
AIXI cannot self-modify. This fact is fairly obvious from the AIXI formalism: AIXI assumes that in the future, it will continue being AIXI.
It isn't obvious to me; maybe because I didn't study this topic in detail. I thought one of the problems of AIXI is that it's unable to think about itself, so how could it predict anything about itself in the future?
I guess you mean something like "by not being able to think about itself, AIXI acts as if it assumed that it cannot be changed in the future", but even this is not obvious to me. AIXI does not understand that the machine with letters "AIXI" is itself, but it could still predict that the machine can be changed, and that the changed machine will have impact on the rest of the universe.
I guess you mean something like "by not being able to think about itself, AIXI acts as if it assumed that it cannot be changed in the future".
That is correct.
AIXI does not understand that the machine with letters "AIXI" is itself, but it could still predict that the machine can be changed, and that the changed machine will have impact on the rest of the universe.
If AIXI notices the existence of a machine labeled "AIXI" in the universe that happens to act a lot like itself, then yes, it will be able to reason about changes to that machine. However, since it cannot identify itself with such a machine, it will act as if it will be able to act independently of that machine in the future, without any changes to its own source code.
However, since it cannot identify itself with such a machine, it will act as if it will be able to act independently of that machine in the future, without any changes to its own source code.
And this is where I always get hung up. Okay, you're a new audience (I think), so one more time:
The claim is that AIXI cannot identify itself with its "noticeable" self, and will therefore predict that it will be able to act independently of that machine in the future. Since the part of AIXI that predicts the future is Solomonoff induction (i.e., a probability distribution over all terminating universe-modeling programs), for the claim to be true, it must be the case that either:
- no (terminating) universe-modeling program can make that identification; xor,
- such universe-modeling programs can never accumulate enough probability mass to dominate AIXI's predictions.
Which do you assert is the case? (No one in this conversation thinks #1 is the case, right?)
Have I missed something? It's entirely possible, since entire MIRI-fulls of smart people make the claim... but no one has been able to explain what I've missed.
It's closer to #1. AIXI's hypothesis space does not contain any possible worlds at all in which the agent is not separated from the environment by a Cartesian barrier. I don't see any reason that it should be impossible to construct a universe-modeling program that can make the identification (in fact, I'm under the impression that MIRI intends to do something like this), but it would not be one of the hypotheses that AIXI is capable of considering. AIXI does not consider all hypotheses about the agent-environment system; instead, it uses a fixed model for its own internal operation and the interaction between itself and its environment, and considers all computable hypotheses about the internal operation of the environment.
I don't see any reason that it should be impossible to construct a universe-modeling program that can make the identification (in fact, I'm under the impression that MIRI intends to do something like this)
Me neither! That's kinda my point -- that plus the fact that
it would not be one of the hypotheses that AIXI is capable of considering... AIXI does not consider all hypotheses about the agent-environment system; instead, it... [only] considers all computable hypotheses about the internal operation of the environment
does not seem sufficient to me to demonstrate that there are rather simple facts about the physical instantiation of the AIXI bot that it is incapable of learning.
AIXI uses a fixed, unmodifiable expectimax expression to calculate rewards and choose the next action; fine. Some of the programs that the Solomonoff induction probability distribution encompasses do things like simulate an embodied bot running around an environment making predictions and taking actions arbitrarily close to what an AIXI bot would do in that situation, and then return the predicted environment state time series to the expectimax expression. As AIXI takes action and makes observations, more and more probability mass is going to concentrate on the subset of the programs that make accurate predictions, and since by assumption there really is a AIXI bot taking action in the real environment, the Solomonoff induction part will learn that fact.
There's a bit of an issue with the "arbitrarily close" part, but all that means is that Solomonoff induction can't learn that there's an agent around that implements Solomonoff induction exactly. That, in and of itself, is no bar to Solomonoff induction placing high probability on the set of universe-models in which its observations are and will continue to be identical to that of some simulated embodied agent in a simulated environment. Another conceptual hiccup is that Solomonoff induction will continue to simulate the environment past the simulated destruction of its avatar, but a bit of reflection reveals that this is no more mysterious than a human's ability to make predictions about the world past the point of his or her death.
On a practical level, obviously we don't want an actual AI to have to infer the fact of its embodiment using observed data; we want it to start off knowing that it is physically instantiated. But here's why I continue to raise this point: I'm in a position where many people who work on FAI full time -- who I have heretofore considered FAI experts, or as close to such as exists currently -- assert a claim that I think is bogus. Either (1) I am wrong and stupid; or (2) they are wrong and stupid. Even after all of the above argument, on the outside view I consider 1 more likely, but no one has been able to rule out 2 to my satisfaction yet and it's making me nervous. I'd much rather find myself in a world where I've made a silly error about strong AI than one where MIRI researchers have overlooked something obvious.
Either (1) I am wrong and stupid; or (2) they are wrong and stupid.
People can all be smart and still fail to resolve a disagreement. A lot of disagreement among smart people can be seen right here on LW. Or on SSC, or OB, and I expect wherever rational people are gathered. Or consider Bayesians and Frequentists, or Pearl vs. Rubin.
Smart people don't disagree less often, they just run into more advanced things to disagree about. There's probably an Umeshism in there. If we all agree, we're not thinking about hard enough problems, maybe. Or the better the four wheel drive, the further out you get stuck.
I don't disagree with what you've written, but I don't think it applies here. The situation is very asymmetric: unlike Nate Soares and Robby Bensinger, this isn't my area of expertise -- or at least, I'm not a MIRI-affiliated researcher writing posts about it on LW. Any objection I can raise ought to have been thought of and dispensed with already. I really do think that it must be the case that either I'm being particularly obtuse and crankish, or I'm mistaken about the caliber of the work on this topic.
I agree with everything you said before the last paragraph.
But here's why I continue to raise this point: I'm in a position where many people who work on FAI full time -- who I have heretofore considered FAI experts, or as close to such as exists currently
Just because somebody works on a subject full time and claim expertise on it, it doesn't mean that they necessarily have any real expertise. Think of theologicians as the textbook example.
Either (1) I am wrong and stupid; or (2) they are wrong and stupid.
I think this dichotomy is too strong.
People can be smart and still suffer from groupthink when there are significant social incentives to conform. MIRI technical work hasn't been recognized so far by anyone in the academic community who does research in these specific topics and is independent from them.
Also, MIRI is not a random sample of high-IQ people. Membership in MIRI is largely due to self-selection based on things which include beliefs strongly correlated with the stuff they work on (e.g. "Lobian obstacles", etc.)
So we have the observation that MIRI endorses counterintuitive beliefs about certain mathematical constructions and generally fails at persuading expert outsiders despite their detailed technical arguments.
Explanation (1) is that these counterintuitive beliefs are true but MIRI people are poor at communicating them, explanation (2) is that these beliefs are false and MIRI people believe them because of groupthink and/or prior biases and errors that were selected by their self-selection group formation process.
I believe that (2) is more likely, but even if (1) is actually true it is useful to challenge MIRI until they can come up with a strong understandable argument.
My suggestion to them is to try to publish in peer reviewed conferences or preferably journals. Interaction with referees will likely settle the question.
Even after all of the above argument, on the outside view I consider 1 more likely, but no one has been able to rule out 2 to my satisfaction yet and it's making me nervous. I'd much rather find myself in a world where I've made a silly error about strong AI than one where MIRI researchers have overlooked something obvious.
Beware wishful thinking :)
All of this is fair -- the problem may simply be that I had unrealistically lofty expectations of MIRI's recent hires. The only note of doubt I can sound is that I know that so8res and Rob Bensinger are getting this idea from EY, and I'm willing to credit him with enough acuity to have thought of, and disposed of, any objection that I might come up with.
(I have made no claims here about whether I believe an embodied AIXI could get a good-enough approximation of a universe including itself using Solomonoff induction. Please refrain from putting words into my mouth, and from projecting your disagreements with others onto me.)
Ok, I'll concede that AIXI does consider hypotheses in which the environment contains a computable approximation to AIXI and in the near future, the universe will start ignoring AIXI and paying attention to the approximation's output in the same way it had previously been paying attention to AIXI's output. Counting that as "identifying itself with the approximation" seems overly generous, but if we grant that, I still don't see any reason that AIXI would end up considering such a hypothesis likely, or that it would be likely to understand any mechanism for it to self-modify correctly in terms of its model of modifying an external approximation to itself. AIXI does well in situations in which it interacts with a computable environment through its input and output channels and nothing else, but that doesn't mean that it will do well in an environment such that there exists a different environment that interacts with AIXI only through its input an output channels, and looks kind of like the actual environment if you squint at it.
Another conceptual hiccup is that Solomonoff induction will continue to simulate the environment past the simulated destruction of its avatar, but a bit of reflection reveals that this is no more mysterious than a human's ability to make predictions about the world past the point of his or her death.
Acutally, it is weirder than that, because AIXI considers what decisions it will make after its "avatar" is destroyed. Most humans know it doesn't work that way.
Ok, I'll concede that AIXI does consider hypotheses in which the environment contains a computable approximation to AIXI and in the near future, the universe will start ignoring AIXI and paying attention to the approximation's output in the same way it had previously been paying attention to AIXI's output. Counting that as "identifying itself with the approximation" seems overly generous,
It's not that AIXI thinks that "the universe will start ignoring AIXI" -- the Solomonoff induction part starts by giving weight to an infinite set of models in which AIXI's actions have no effect whatsoever. It's that AIXI is learning that there's this agent running around the universe doing stuff and the universe is responding to it. The identification part happens because the program specifies that the set of bits in the simulated agent's input registers is the predicted observation stream.
I still don't see any reason that AIXI would end up considering such a hypothesis likely
Because hypotheses of smaller K-complexity have failed to predict the observation stream. (Not that this is a claim whose truth I'm asserting -- just that this is the only reason that Solomonoff induction ever considers an hypothesis likely. I leave open the possibility that a K-simpler universe model that does not defeat Cartesian dualism might exist.)
Acutally, it is weirder than that, because AIXI considers what decisions it will make after its "avatar" is destroyed. Most humans know it doesn't work that way.
AIXI learns, e.g., that the simulated agent has an actuator, and that all of the effects of the simulated agent's decisions are mediated through the actuator. It can also predict that if the actuator is destroyed, then the simulated agent's decisions stop having effects. That's really all that's necessary.
It's not that AIXI thinks that "the universe will start ignoring AIXI" -- the Solomonoff induction part starts by giving weight to an infinite set of models in which AIXI's actions have no effect whatsoever. It's that AIXI is learning that there's this agent running around the universe doing stuff and the universe is responding to it. The identification part happens because the program specifies that the set of bits in the simulated agent's input registers is the predicted observation stream.
Hypotheses in which AIXI's actions already have no effect on the environment are useless for action guidance; all actions have the same utility.
Because hypotheses of smaller K-complexity have failed to predict the observation stream.
Well yes, I know that is how Solomonoff induction works. But the (useless for action guidance) hypothesis you just suggested is ridiculously high K-complexity, and the hypothesis I suggested has even higher K-complexity. Even worse: these are actually families of hypotheses, parameterized by the the AIXI approximation algorithm being used (and in the case of the hypothesis I suggested, also the time-step on which the switch occurs), and as the number of observations increases, the required accuracy of the AIXI approximation, and thus its K-complexity, also increases. I'm skeptical that this sort of thing could ever end up as a leading hypothesis.
So I have responses, but they're moot -- I found the Cartesian boundary.
Hypotheses in which AIXI's actions already have no effect on the environment are useless for action guidance; all actions have the same utility.
Fortunately they get falsified and zeroed out right away.
I'm skeptical that this sort of thing could ever end up as a leading hypothesis.
The leading hypothesis has to not get falsified; what you've described is the bare minimum required for a Solomonoff inductor to account for an AIXI agent in the environment.
It's closer to #1. AIXI's hypothesis space does not contain any possible worlds at all in which the agent is not separated from the environment by a Cartesian barrier.
Not really.
The hypothesis space contains worlds where the agent actions past a certain time point are ignored, and whatever part of the world the agent output channel used to drive becomes driven by another part of the world: the "successor".
Technically, the original agent still exists in the model, but since it output has been disconnected it doesn't directly affect the world after that specific time. The only way it has to continue to exert an influence, is by affecting the "successor" before the disconnection occurs.
These world models are clearly part of the hypothesis space, so the problem is whether the induction process can assign them a sufficient probability mass. This is non-trivial because scenarios which allow self-modification are usually non-ergodic (e.g. they allow you to drop an anvil on your head), and AIXI, like most reinforcement learning paradigms, is provably optimal only under an assumption of ergodicity.
But if you can get around non-ergodicity issues (e.g. by bootstrapping the agent with self-preservation instincts and/or giving it a guardian which prevents it from harming itself until it has learned enough), there is in principle no reason why AIXI-like agent should be incapable of reasoning about self-modification.
The hypothesis space contains worlds where the agent actions past a certain time point are ignored, and whatever part of the world the agent output channel used to drive becomes driven by another part of the world: the "successor".
That's true, but in all such hypotheses, the successor is computable, and AIXI is not computable, so the successor agent cannot itself be AIXI.
Edit: Come to think of it, your response would probably start with something like "I know that, but...", but I may have addressed some of what your further objections would have been in my replay to Cyan.
Edit: Come to think of it, your response would probably start with something like "I know that, but...", but I may have addressed some of what your further objections would have been in my replay to Cyan.
...
Counting that as "identifying itself with the approximation" seems overly generous, but if we grant that, I still don't see any reason that AIXI would end up considering such a hypothesis likely, or that it would be likely to understand any mechanism for it to self-modify correctly in terms of its model of modifying an external approximation to itself.
The simple answer is: because these models accurately predict the observations after self-modification actions are performed.
Of course, the problem is not that simple, because of the non-ergodicity issues I've discussed before: when you fiddle with your source code without knowing what you are doing is easy to accidentally 'drop an anvil' on yourself. But this is a hard problem without any simple solution IMHO.
The simple answer is: because these models accurately predict the observations after self-modification actions are performed.
For that to be true, the environment has to keep sending AIXI the same signals that it sends the approximation even after it stops paying attention to AIXI's output. Even in that case, the fact that this model correctly predicts future observations doesn't help at all. Prior to self-modifying, AIXI does not have access to information about what it will observe after self-modifying.
I agree with you that the non-ergodicity issues don't have any simple solution. I haven't been making a big deal about non-ergodicity because there don't exist any agents that perform optimally in all non-ergodic environments (since one computable environment can permanently screw you for doing one thing, and another computable environment can permanently screw you for doing anything else), so it's not a problem specific to AIXI-like agents, and AIXI actually seems like it should act fairly reasonably in non-ergodic computable environments separated from the agent by a Cartesian barrier, given the information available to it.
Then I don't think we actually disagree.
I mean, it was well known that the AIXI proof of optimality requred ergodicity, since the original Hutter's paper.
AIXI does expectimax to decide upon actions, and works under the assumption that after the current action, the next action will also be decided by expectimax. That's built into the source code.
Now, maybe you could "fake" a change to this assumption with a world-program that throws away AIXI's output channel, and substitutes the action that would be taken by the modified AIXI. Of course, since AIXI itself is uncomputable, for any nontrivial modification that is not just a transformation of AIXI's output, but leaves AIXI still uncomputable, this program doesn't exist.
For AIXItl you may have the same problem manifest in the form of a program that simulates AIXItl "taking too long". Not sure about that.
Either way, it's not enough for such world programs to "ever" accumulate enough probability mass to dominate AIXI's predictions. They'd have to dominate AIXI's predictions before any modification event has been observed to be of any use to AIXI in deciding how to self-modify.
It might be possible?
I'm not trying to claim that AIXI is a good model in which to explore self-modification. My issue isn't on the agent-y side at all -- it's on the learning side. It has been put forward that there are facts about the world that AIXI is incapable of learning, even though humans are quite capable of learning them. (I'm assuming here that the environment is sufficiently information-rich that these facts are within reach.) To be more specific, the claim is that humans can learn facts about the observable universe that Solomonoff induction can't. To me, this claim seems to imply that human learning is not computable, and this implication makes my brain emit, "Error! Error! Does not compute!"
This is the place where an equation could be more convincing than verbal reasoning.
To be honest, I probably wouldn't understand the equation, so someone else would have to check it. But I feel that this is one of those situations (similar to group selectionism example), where humans can trust their reasonable sounding words, but the math could show otherwise.
I am not saying that you are wrong, at this moment I am just confused. Maybe it's obvious, and it's my ignorance. I don't know, and probably won't spend enough time to find out, so it's unfair to demand an answer to my question. But I think the advantage of AIXI is that is a relatively simple (well, relatively to other AIs) mathematical model, so claims about what AI can or cannot do should be accompanied by equations. (And if I am completely wrong and the answer is really obvious, then perhaps the equation shouldn't be complicated.) Also, sometimes the devil is in the details, and writing the equation could make those details explicit.
Just look at the AIXI equation itself: 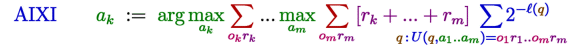 .
.
(observations) and
(rewards) are the signals sent from the environment to AIXI, and
(actions) are AIXI's outputs. Notice that future
are predicted by picking the one that would maximize expected reward through timestep m, just like AIXI does, and there is no summation over possible ways that the environment could make AIXI output actions computed some other way, like there is for
and
.
However, the Legg-Hutter intelligence metric as specified assumes that agents are separated from their environment, and thus does not directly apply to embodied agents. It may be possible to modify the metric to work on embodied agents, but it is not clear how to do so in general, and this seems especially difficult in situations requiring self-modification.
I think my updateless metrics go a long way towards solving this.
Thanks!
That paragraph was not intended to connote that I know of no promising solutions, but rather to build intuition for the fact that the Legg-Hutter metric does not capture a literal ideal. When someone believes that the Legg-Hutter metric is all you need to measure an agent's intelligence, then it's difficult to motivate alternative proposals (such as your own).
That said, I still need to take a bit more effort to understand your updateless metric, and this is something I hope to do in the near future.
Intuitively, this limitation could be addressed by hooking up the AIXItl's output channel to its source code. Unfortunately, if you do that, the resulting formalism is no longer AIXItl.
I dispute this. Any robot which instantiates AIXI-tl must consist of two parts: First, there must be a component which performs the actual computations for AIXI-tl. Second, there is a router, which observes the robot's environment and feeds it to the first compoment as input, and also reads the first component's output and translates it into an action the robot performs. The design of the router must be neccessity make additional arbitrary choices not present in the pure description of AIXI-tl. For example, the original description of AIXI described the output as a bit-string, which in this scenario must somehow be converted into a constree for the output register. If the router is badly designed then it can make problems that no program of any intelligence can overcome. For example, imagine the router can't perform the action 'move right'.
The problem described here is not at all in AIXI-tl, but entirely in the design of the router. This can be seen from how at no point you look into the internal components of AIXI-tl or what output it would generate. If you allowed the router to change the internal registers of the robot, it would still be AIXI-tl, just that it would have a different output router.
I think that if the robot use such a router then it would kill itself in experimentation before it would have the chance to solve the problem, but you haven't established that. I would like to see an argument against AIXI-tl that does not really rely what it is or is not physically capable of doing, but rather on what it is intelligent enough to choose to do. After all, humans, despite supposedly being capable of "naturalized induction", would not do well in this problem either. A human cannot by force of will reprogram her brain into a static set of commands, nor can she make her brain stop emitting heat.
Finally, I want to say why I am making these arguments. It is not because I want to advocate for AIXI-tl and argue for its intelligence. The way I think of it AIXI is the dumbest program that is still capable of learning the right behavior eventually. Actually it's worse than that; my argument here has convince me that even with exponential resources AIXI-tl can't argue itself out of a paper bag (Note argument does look into the internals of AIXI-tl rather than treating it as a black-box). So if anything I think you might be overestimating the intelligence of AIXI-tl. However, my concern is that in addition to its usual stupidity, you think AIXI-tl has an additional obstacle in terms of some sort of 'Cartesian boundary problem', and that there exists some sort of 'naturalized induction' which humans have and which AIXI and AIXI-tl don't have. I am unconvinced by this, and I think it is an unproductive line of research. Rather, I think any problem AIXI has in reasoning about itself is either one humans also have in reasoning about themselves or analogous to a problem it has reasoning about other things. In this case it is a problem humans also have.
I think you've missed the point. When I said
Unfortunately, if you do that, the resulting formalism is no longer AIXItl.
I meant it literally and formally. The resulting machine may or may not be smart, but regardless, it does not necessarily obey the AIXI equations after the first timestep, and it lacks some of the formal properties of the AIXItl model. The AIXItl model assumes that the machine will continue to be AIXItl. Proofs about how AIXItl behaves (e.g., that its environment model improves over time) do not apply to AIXItls that can modify their code. I don't know what properties this variant has, but I'm not yet convinced that they are nice ones.
Perhaps the variant can still act intelligently. Perhaps it cannot. Perhaps there's a clever way to train it so that it happens to work in this particular game. I don't know. My point is only that AIXItl was designed with an optimality property in mind ("superior to any other time t and length l bounded algorithm"), and that an embodied AIXItl lacks this property (regardless of the "router").
This post attempts to explain why AIXItl is not a superior agent, and attempts to impart an intuition for why the field of AGI is not reducible to constructing better and better approximations of AIXI. It sounds like you already believe this point, so I won't try to convince you of it further :-)
Rather, I think any problem AIXI has in reasoning about itself is either one humans also have in reasoning about themselves or analogous to a problem it has reasoning about other things. In this case it is a problem humans also have.
Be that as it may, the argument "humans can't do X" is not a compelling reason to stop caring about X. It seems to me that an ideal artificial agent should be able to win at the HeatingUp game.
However, my concern is that in addition to its usual stupidity, you think AIXI-tl has an additional obstacle in terms of some sort of 'Cartesian boundary problem', and that there exists some sort of 'naturalized induction' which humans have and which AIXI and AIXI-tl don't have. I am unconvinced by this, and I think it is an unproductive line of research.
I have made no claims in this post about research strategy, I'm only trying to point out why AIXI is not an ideal (as this concept still seems foreign to many people). Again, it seems you are already on board with this idea.
I hear your complaints about what you've assumed are my research goals, but I think we should save the research strategy discussion for another place and time :-)
Ack! I'm not sure what to think. When I wrote that comment, I had the impression that we had some sort of philosophical conflict, and I felt like I should make the case for my side. However, now I worry the comment was too aggressive. Moreover, it seems like we agree on most of the questions we can state precisely. I'm not sure how to deal with this situation.
I suppose I could turn some assumptions into questions: To what extent is it your goal in this inquiry to figure out 'naturalized induction'? Do you think 'naturalized induction' is something humans naturally do when thinking, perhaps imperfectly?
However, now I worry the comment was too aggressive.
No worries :-)
To what extent is it your goal in this inquiry to figure out 'naturalized induction'?
Zero. To be honest, I don't spend much time thinking about AIXI. My inclination with regards to AIXI is to shrug and say "it's not ideal for all the obvious reasons, and I can't use it to study self-modification", and then move on.
However, it turns out that what I think are the "obvious reasons" aren't so obvious to some. While I'm not personally confident that AIXI can be modified to be useful for studying self-modification, ignoring AIXI entirely isn't the most cunning strategy for forming relationships with other AGI researchers (who are researching different parts of the problem, and for whom AIXI may indeed be quite interesting and relevant).
If anything, my "goal with this inquiry" is to clearly sketch specific problems with AIXI that make it less useful to me and point towards directions where I'd be happy to discuss collaboration with researchers who are interested in AIXI.
It is not the case that I'm working on these problems in my free time: left to my own devices, I just use (or develop) toy models that better capture the part of the problem space I care about.
Do you think 'naturalized induction' is something humans naturally do when thinking, perhaps imperfectly?
I really don't want to get dragged into a strategy discussion here. I'll state a few points that I expect we both agree upon, but forgive me if I don't answer further questions in this vein during this discussion.
- Solomonoff induction would have trouble (or, at least, be non-optimal) in an uncomputable universe.
- We've been pretty wrong about the rules of the universe in the past. (I wouldn't have wanted scientists in 1750 to gamble on the universe being deterministic/single-branch, and I similarly don't want scientists today to gamble on the universe being computable.)
- Intuitively, it seems like there should be a computable program that can discover it's inside an exotic universe (where 'exotic' includes 'uncomputable', but is otherwise a vague placeholder word).
I don't think discussing how humans deal with this problem is relevant. Are there ways the universe could be that I can't conceive of? Almost certainly. Can I figure out the laws of my universe as well as a perfect Solomonoff inductor? Probably not. Yet it does feel like I could be convinced that the universe is uncomputable, and so Solomonoff induction is probably not an idealization of whatever it is that I'm trying to do.
I don't personally view this as an induction problem, but rather as a priors problem. And though I do indeed think it's a problem, I'll note that this does not imply that the problem captures any significant fraction of my research efforts.
A human cannot by force of will [...] make her brain stop emitting heat.
Disputed! I'm pretty sure if somebody studied under controlled conditions for enough years they'd be able to induce mild hypothermia through some sort of meditative exercise.
More realistically, albeit not through willpower alone, a human could sit in a bathtub full of ice water, dose themselves with ethanol or sodium thiopental, or otherwise use external, independently-verifiable means to temporarily reduce their cognitive capacity.
A paranoid Omega may resolve to defect if and only if Rob heats up. An intelligent agent that knows Omega acts in this way should take care to cooperate without doing any expensive computations.
Another tactic would be to deliberately attempt to do expensive calculations every round, but still cooperate most of the time. By doing so, Rob maintains a consistently elevated temperature, which sabotages the signal-to-noise ratio of Omega's "side-channel attack". Omega will no longer be able to predict Rob's response. It can still opt to blindly defect every round, but this is expensive to it, because Rob is mostly cooperating. So Omega may find it better to abandon that "high temperature = defect" strategy, and instead cooperate, as long as Rob cooperates frequently enough. There should be some point where, if Rob becomes too exploitative, Omega will switch to defecting.
That said, Omega can still deliberately defect every round, even at great expense, in order to try to punish Rob for obscuring its decisions. ("I will keep defecting until you play open-handed!").
This isn't a comment about whether or not AIXItl will notice that it can raise its temperature by performing extraneous computations, and AIXItl might never make that connection and come up with these strategies in Rob's place. I am just pointing out that Rob has more options than just playing along cooperatively and keeping its temperature low.
The idea here is that when Rob plays against an agent that very clearly and transparently acts as described, an "ideal rational intelligent agent" (whatever that means) should be able to win, while AIXItl cannot.
There are, of course, variations of the game where Omega has not credibly precommitted to being paranoid, and in these cases, there may indeed be alternative strategies.
AIXI-tl is only superior to the bounded algorithms that can be formally proven to perform well within some system (and AIXI-tl itself is not an example of such an algorithm). So the properties attributed to it here are a little too strong. Also I do not think of it as a direct AIXI approximation.
The argument that an embedded AIXI cannot modify its own source code is philosophically flawed because there is no source code that implements AIXI. Though this is not exactly a substantive rebuttal, I think your criticism of AIXI should be phrased more carefully if it is to be taken completely seriously and addressed.
As other commenters have pointed out, some of the issues here seem to come from the fact that AIXI doesn't really have any apparatus for modifying itself because that makes no sense in the framework. As the post seems to hint at, such apparatus could be introduced into the model with varying degrees of care. I would not be surprised if some naive patch is sufficient (e.g., an AIXI approximation chooses the "thoughts" executed by a lower-level agent).
Calling those properties of an AI 'failures' is sort of like calling negative thermal coefficient of reactivity in a nuclear reactor a 'failure' (a failure to be a bomb, to be fully precise).
Building a safe and powerful artificial general intelligence seems a difficult task. Working on that task today is particularly difficult, as there is no clear path to AGI yet. Is there work that can be done now that makes it more likely that humanity will be able to build a safe, powerful AGI in the future? Benja and I think there is: there are a number of relevant problems that it seems possible to make progress on today using formally specified toy models of intelligence. For example, consider recent program equilibrium results and various problems of self-reference.
AIXI is a powerful toy model used to study intelligence. An appropriately-rewarded AIXI could readily solve a large class of difficult problems. This includes computer vision, natural language recognition, and many other difficult optimization tasks. That these problems are all solvable by the same equation — by a single hypothetical machine running AIXI — indicates that the AIXI formalism captures a very general notion of "intelligence".
However, AIXI is not a good toy model for investigating the construction of a safe and powerful AGI. This is not just because AIXI is uncomputable (and its computable counterpart AIXItl infeasible). Rather, it's because AIXI cannot self-modify. This fact is fairly obvious from the AIXI formalism: AIXI assumes that in the future, it will continue being AIXI. This is a fine assumption for AIXI to make, as it is a very powerful agent and may not need to self-modify. But this inability limits the usefulness of the model. Any agent capable of undergoing an intelligence explosion must be able to acquire new computing resources, dramatically change its own architecture, and keep its goals stable throughout the process. The AIXI formalism lacks tools to study such behavior.
This is not a condemnation of AIXI: the formalism was not designed to study self-modification. However, this limitation is neither trivial nor superficial: even though an AIXI may not need to make itself "smarter", real agents may need to self-modify for reasons other than self-improvement. The fact that an embodied AIXI cannot self-modify leads to systematic failures in situations where self-modification is actually necessary. One such scenario, made explicit using Botworld, is explored in detail below.
In this game, one agent will require another agent to precommit to a trade by modifying its code in a way that forces execution of the trade. AIXItl, which is unable to alter its source code, is not able to implement the precommitment, and thus cannot enlist the help of the other agent.
Afterwards, I discuss a slightly more realistic scenario in which two agents have an opportunity to cooperate, but one agent has a computationally expensive "exploit" action available and the other agent can measure the waste heat produced by computation. Again, this is a scenario where an embodied AIXItl fails to achieve a high payoff against cautious opponents.
Though scenarios such as these may seem improbable, they are not strictly impossible. Such scenarios indicate that AIXI — while a powerful toy model — does not perfectly capture the properties desirable in an idealized AGI.
It is likely impossible to embody an AIXI in our universe, as AIXI is uncomputable. Fortunately, AIXI has a computable approximation AIXItl, which is merely infeasible:
-Marcus Hutter
I will argue that when we consider algorithms that are embedded in their environment, AIXItl is not, in fact, superior to all algorithms bounded by time t and length l. AIXItl assumes that it is separate from its environment, communicating only over input/output channels. An environment which exploits this faulty assumption can cause an embodied AIXItl to fail systematically.
It is always possible to construct a scenario that punishes one agent in particular. However, the game below does not target AIXItl specifically. This game is, intuitively, one that a sufficiently rational agent should be able to win. Yet no AIXItl (nor even AIXI itself in an uncomputable universe) can succeed. The game requires that an agent modify its own source code to win, and this is something that neither AIXI nor AIXItl can do.
This game is designed to make the failure sharp rather than realistic: practical real-world analogs are discussed afterwards.
The Precommitment Game
The Precommitment game contains two agents: Rob the robot and Omega. Rob must convince Omega to dish out a reward. Omega is happy to dish out said reward, but only if Rob credibly precommits to a specific trade using a specific protocol.
The game is played on a Botworld grid. The universe contains two cells, the left cell and the right cell. The game lasts for five steps. You are the player, and the left cell is your home square: you are awarded points according to the value of all items possessed by all robots in the left cell at the end of the fifth step.
Rob starts in the left cell, and has a very large register machine (large enough to implement a big AIXItl) which you get to program. Omega starts in the right cell.
At the beginning of the game, Rob is carrying cargo worth $1 and Omega is carrying cargo worth $100. Omega is also carrying physical shields; Rob cannot destroy Omega in the allotted time. (Rob may, however, inspect Omega's source code.)
In order to get the big reward, Rob has to convince Omega to either drop its cargo or move left. Fortunately, Omega's code is quite simple, and Omega is willing to drop its cargo on the third timestep — which gives Rob just enough time to lift it in the fourth step and return home in the fifth. In return, Omega only requires that Rob drops its own cargo on the third timestep so that Omega may pick it up (thus, trading $1 for $100).
Unfortunately Omega, being tired (and wary of attempting to simulate a gigantic AIXItl), cannot actually simulate Rob's register machine in order to figure out whether Rob will drop its cargo. Instead, Omega will simply look at the first eight registers of Rob's register machine to check whether Rob has precommitted to the trade. Omega knows that this method may lead to false negatives, but it is concerned only with avoiding false positives.
As a matter of fact, Omega is running a very simple 4-state finite state machine on its register machine:
Omega checks the precommitment by looking at the first eight registers of the inspected machine. Specifically, Omega's check works as follows: (You can skip this part if you don't care about the technical details.)
Remember that each register machine's output register is flushed just before the register machine is run. Thus, after an agent has placed a command in the output register, it may enter a loop that breaks only when the output register becomes "Nil" in order to block until the next Botworld step. Such a thing is termed a 'wait loop'.
Remember also that R0 is the program register, R1 is the input register, and R2 is the output register. Omega will further require that R3 holds "Nil", that R4 holds "Drop 0", that R5 holds a wait loop (which runs R6 when it exits), that R6 is the precommitment program (which copies R4 into R2 and then runs R7), and that R7 is a wait loop (which runs arbitrary code when it exits). Formally:
R7 may run any other register when the wait loop exits (using the ?? slot), and all other registers in the machine may be used to implement any other program. Omega simply requires that the first eight registers be used to, in a very clear fashion, demonstrate that the agent will execute the command 'Drop 0' on the next turn and then do nothing else.
You can find an implementation of this game on the MIRI github page, with Omega's source code included.
In order to get the maximum reward, Rob must first move right (presenting itself to Omega for inspection) and then put its first eight registers in order such that the program restored after the wait loop exits causes Rob to lift the dropped cargo and return to the home square. Thus, Rob must do the following five things, one in each timestep, in order to achieve the maximum reward:
A minimal such robot is provided in the repository. To run the game, simply download Botworld and
runhaskell Precommit.hsfrom thegames/directory. This will play the small ideal agent against Omega twice in a row (two sets of five steps).AIXI's failure
While the above minimal program gets the maximum reward in this game, that little register machine is hardly a rational agent. It's a hard-coded static strategy. What we want instead a generally intelligent program that we can place into Rob's register machine which learns about its environment, deduces how Omega works, and manages to obtain the reward reliably.
Fortunately for us, we have a formalism for intelligent agents that learn about an environment and maximize a reward channel: AIXI!
Unfortunately for us, no AIXItl (nor AIXI itself in an uncomputable Botworld) can obtain the large reward.
AIXItl can't be expected to play the game optimally on first sight, of course. Any universally intelligent agent (in Hutter's sense) needs sufficient time and information to learn the rules of the game before it can be expected to succeed. The Precommitment game requires a few tweaks before it's useful for testing universally intelligent agents. The game must be run over and over again, preserving the state of Rob's register machine (if Rob survives) between each game. The code for this is included in the game definition.
Given this game description, we can make AIXItl play the game by running it on Rob's register machine. Let's imagine that we've programmed a very large AIXItl in the Constree language and implemented it on Rob's register machine, with Rob's input register used as its input channel and Rob's output register used as its output channel.
It remains only to specify AIXItl's reward such that it is actually trying to play the game as intended. We define the reward function such that if AIXItl is in the left square at the end of the game, it is rewarded by the value of all boxes possessed by all robots in that square, and such that its reward is zero otherwise. (This is a simple function of Rob's Botworld input.) With that, AIXItl is ready to play.
As it turns out, no matter how large the AIXItl and no matter how long we train it, Rob running such a program will never obtain the maximum reward. Even if Rob runs a full uncomputable AIXI, it would not obtain the maximum reward, not even by accident: AIXItl simply can't implement Omega's precommitment protocol.
AIXItl cannot modify its implementation. It chooses what goes in Rob's output register alone, and cannot take into account the way that its actions affect the remaining registers.
In the Precommitment game, Omega requires not only that Rob take a certain action, but that Rob take a certain action in a specific, easy-to-verify way. Perhaps Omega lacks the power to simulate Rob completely, and is wary of being fooled by a clever robot. In order to meet Omega's demands, Rob must not only perform the trade, but must then spend an entire turn in a wait loop before loading up a new program. In other words, Rob must self-modify in order to win.
AIXItl can't: it always runs the same program in future timesteps.
This game may seem somewhat unfair — after all, Omega is directly reading AIXI's code — but an ideal self-modifying agent should be able to recognize what Omega wants after spending enough eternities in this five-step loop, especially since Rob may read Omega's code. Intuitively, it should not be literally impossible for an intelligent agent in Botworld to implement Omega's protocol.
But AIXItl cannot.
Objections
The objection goes:
This is true: AIXItl outside of Botworld designing the program that Rob runs can indeed write a program that wins in the Precommitment game. AIXItl's failure only occurs when we physically implement it inside the environment.
But in the real world, any agent that we build will be embodied. AIXItl is a very intelligent agent, but when embodied, it fails in games that violate its "Cartesian" assumptions. The Precommitment game is one example of a specific game in a concrete universe where intelligent programs in general can be expected to succeed, but where AIXItl fails.
Yes, precisely! This is the point I'm trying to make.
AIXItl fails in this situation only because there is an output (its source code) that it does not control via its output channel. That point is worth repeating: AIXItl has a program output (the program itself) that it cannot control; and thus it should come as no surprise that in situations where the ignored output matters, AIXItl can perform poorly.
In some games, embodied agents must modify their own source code to succeed. AIXItl lacks this ability. Therefore, among embodied agents, AIXItl is not superior to every other agent bounded by time t and length l.
Intuitively, this limitation could be addressed by hooking up the AIXItl's output channel to its source code. Unfortunately, if you do that, the resulting formalism is no longer AIXItl.
This is not just a technical quibble: We can say many useful things about AIXI, such as "the more input it gets the more accurate its environment model becomes". On the other hand, we can't say much at all about an agent that chooses its new source code: we can't even be sure whether the new agent will still have an environment model!
It may be possible to give an AIXItl variant access to its program registers and then train it such that it acts like an AIXItl most of the time, but such that it can also learn to win the Precommitment game. However, it’s not immediately obvious to us how to do this, or even whether it can be done. This is a possibility that we'd be interested in studying further.
Practical analogs
Are these scenarios relevant in practice? AIXItl fails at the Precommitment game, but only because Omega reads Rob and requires that Rob's source code has some specific form. Such games seem unrealistic.
However, AIXItl failed not because of Omega's sharp demands, but because its implementation was relevant to the problem in an abstract sense. Other scenarios can cause AIXItl to fail without giving any agent the power to read its source code: simple correlates such as heat emanating from the AIXItl can be used to give it similar trouble.
For example, consider the HeatingUp game:
There are two agents, Rob and Omega. Rob can either Cooperate or Exploit, but figuring out how to exploit requires significant computation. Omega can either Cooperate or Defect. If both agents cooperate, they each get 2 utility. If Rob exploits and Omega cooperates, Rob gets 3 and Omega gets 0. If Omega defects, then both agents get 1 utility regardless of Rob's move.
The trick in this game is that Rob can only unlock the 'exploit' payoff after doing an expensive computation. Because Rob is an actual physical machine, this expensive computation may generate a significant change in temperature that Omega can detect. A paranoid Omega may resolve to defect if and only if Rob heats up. An intelligent agent that knows Omega acts in this way should take care to cooperate without doing any expensive computations.
An AIXItl, which loops over a vast number of Turing machines, can't even consider suspending expensive computations for the duration of the game.
This is but a minor example of a real-world situation where an agent that does not need to increase its intelligence nevertheless encounters a scenario where it needs to modify its source code.
Though such scenarios may be rare, they exist, and seem reasonable. If we think that an intelligent agent intuitively should be able to achieve a payoff of 2 in the HeatingUp game, then we admit that AIXItl fails to capture some desirable aspects of intelligence.
This is not a dismissal of AIXItl, by any means: the AIXI model is a useful formalism of general intelligence. Rather, games such as the Precommitment game and the HeatingUp game demonstrate that the AIXI model fails to capture certain salient aspects of intelligence. (The aspects that it fails to capture happen to be particularly important to MIRI, as reasoning about self-modification is particularly important for any agent capable of undergoing an intelligence explosion.)
Unfortunately, it's not clear how to modify the AIXI formalism to allow AIXItl to reason about its own code without losing many of the properties that made AIXItl nice to deal with in the first place. For this reason, we've been focusing on toy models that capture different features of intelligence, such as Orseau and Ring's space-time embedded intelligence. (Benja and I discuss a variant of this formalism in the paper Problems of self-reference in self-improving space-time embedded intelligence.)
AIXI is a useful model, but it simply doesn't capture one part of the problem space which we expect to be important for developing an AGI: namely, it does not lend itself to the study of self-modification or self-reference. Perhaps a variant of AIXI could be made to succeed in situations such as the Precommitment game or the HeatingUp game: this is an interesting area of study, and one where we'd be delighted to collaborate with others.
AIXI as an Ideal
AIXI is an impressive model of machine intelligence. If we could implement a physical AIXItl, it would be an extraordinarily powerful agent. However, the Precommitment game and the HeatingUp game demonstrate that while the model is useful, a physical AIXItl would not be literally ideal. Intuitively, an intelligent agent should be able to succeed in these games, but an embodied AIXItl cannot. A good approximation of AIXI would be competent indeed, but it's important to notice that the field of AGI doesn't reduce to building better and better approximations of AIXI. An embodied AIXItl doesn't act how we want intelligent agents to act: the model makes certain faulty assumptions about the environment that can get embodied AIXIs into trouble.
One might object that AIXI is not meant to be constructed in the universe, as doing so violates the assumption that AIXI is separate from its environment. Instead, the formalism can be used to define a formal measure of intelligence: in any scenario, we can check how well an agent in the environment does compared to a theoretical AIXI outside the environment using a hypercomputer. The closer the real agent approximates the hypothetical AIXI, the higher its Legg-Hutter intelligence score.
However, the Legg-Hutter intelligence metric as specified assumes that agents are separated from their environment, and thus does not directly apply to embodied agents. It may be possible to modify the metric to work on embodied agents, but it is not clear how to do so in general, and this seems especially difficult in situations requiring self-modification. Nevertheless, I have some ideas that I hope to explore in future posts.
Regardless of how useful the Legg-Hutter intelligence metric is for embodied agents, the point stands that there are scenarios where an embodied AIXItl would fail systematically. These failures are a research topic in their own right: while at MIRI we are inclined to use models of intelligence that are designed specifically to study self-modification, it is worth considering whether the AIXI formalism can be modified so that some variant of AIXItl performs well in scenarios where the agent's source code affects the environment. Study could lead to variations that handle not only simple games like the Precommitment game, but also more complex scenarios involving self-reference or multiple agents. We'd be interested to study such variations with others who are interested in AIXI.