"Surely the cumulative power of natural selection is beyond human intelligence?"
Even if it was, why would you want to use it? Evolution has thoroughly screwed over more human beings than every brutal dictator who ever lived, and that's just humans, never mind the several billion extinct species which litter our planet's history.
So the meaningful DNA specifying a human must fit into at most 25 megabytes.
And that's before compression :-)
"So the meaningful DNA specifying a human must fit into at most 25 megabytes."
These are bits of entropy, not bits on a hard drive. It's mathematically impossible to compress bits of entropy.
Eliezer, your argument seems to confuse two different senses of information. You first define "bit" as "the ability to eliminate half the possibilities" -- in which case, yes, if every organism has O(1) children then the logical "speed limit on evolution" is O(1) bits per generation.
But you then conclude that "the meaningful DNA specifying a human must fit into at most 25 megabytes" -- and more concretely, that "it is an excellent bet that nearly all the DNA which appears to be junk, really is junk." I don't think that follows at all.
The underlying question here seems to be this: suppose you're writing a software application, and as you proceed, many bits of code are generated at random, many bits are logically determined by previous bits (albeit in a more-or-less "mindless" way), and at most K times you have the chance to fix a bit as you wish. (Bits can also be deleted as you go.) Should we then say that whatever application you end up with can have at most K bits of "meaningful information"?
Arguably from some God's-eye view. But any mortal examining the code could see far more than K of the bits fulfillin...
Excluding the complex and subtle regulatory functions that non-coding DNA can possess strikes me as being extremely unwise.
There is no DNA in the maize genome that codes for striped kernels, because that color pattern is the result of transposons modulating gene expression. The behavior of one transposon is intricately linked to the total behavior of all transposons, and the genetic shifts they result in defy the simple mathematical rules of Mendelian inheritance. But more importantly, the behavior of transposons is deeply linked to the physical structure of the encoding regions they're associated with.
Roughly half the genome of corn is made up of transposons. Is this 'junk' or not?
Aaronson, McCabe:
Actually, these mathematician's bits are very close to bits on a hard drive. Genomes, so far as I know, have no ability to determine what the next base ought logically to be; there is no logical processing in a ribosome. Selection pressure has to support each physical DNA base against the degenerative pressure of copying errors. Unless changing the DNA base has no effect on the organism's fitness (a neutral mutation), the "one mutation, one death" rule comes into play.
Now certainly, once the brain is constructed and patterned,...
However, mutation rates vary and can be selected. They aren't simply a constraint.
Also, it's been a long time since I've thought about this and I may be wrong, but aren't you talking about 1 bit per linkage group and not one bit per genome? (And the size of linkage groups also varies and can be selected.)
Some viruse genomes face severe constraints on size -- they have a container they must fit into -- say an icosahedral shape -- and it would be a big step to increase that size. And some of those make proteins off both strands of DNA and sometimes in more t...
Eliezer, so long an organism's fitness depends on interactions between many different base pairs, the effect can be as if some of the base pairs are logically determined by others.
Also, unless I'm mistaken there are some logical operations that the genome can perform: copying, transpositions, reversals...
To illustrate, suppose (as apparently happens) a particular DNA stretch occurs over and over with variations: sometimes forwards and sometimes backwards, sometimes with 10% of the base pairs changed, sometimes chopped in half and sometimes appended to anot...
Tom:These are bits of entropy...mathematically impossible to compress
My bad, was thinking of the meaningful base pairs. Thanks for correcting me.
I interpret Eliezer to be saying that the Kolmogorov complexity of the human genome is roughly 25MB -- the absolute smallest computer program that could output a viable human genome would be about that size. But this minimal program would use a ridiculous number of esoteric tricks to make itself that small. You'd have to multiply that number by a large factor (representing how compressible, in principle, modern applications are) to make a comparison to hard drive bits as they are actually used.
Eek I just noticed an unfortunate way that last comment could be read. I meant I was thinking of material bits of information when I should have thought of information-theoretical bits. I in no way interpret your "bits of entropy" to mean physical, non-meaningful base pairs!
Eliezer, I see two potential flaws in your argument, let me try and explain:
1.) The copy error rate can't directly translate mathematically into how often individuals in a species die out due to the copy error rate. We simply can't know how often a mutation is neutral, good, or detrimental, in part because that depends on the specific genome involved. I imagine some genomes are simply more robust than others. But I believe the prevailing wisdom is that most mutations are neutral, simply because proteins are too physically big to be effected by small change...
Scott, the mechanisms you've described indeed allow us to end up with more meaningful physical DNA than the amount of information in it. To give a concrete example, a protein-coding gene is copied, then mutates, and then there's two highly structured proteins performing different chemical functions, which because of their similarity, evolved faster than counting the bases separately would seem to allow.
So the 1 bit/generation speed limit on evolution is not a speed limit on altered DNA bases - definitely not!
The problem is that these meaningful bases also...
Quite a lot of mutations are so lethal that they abort embryonic development, yes. This is a severe problem with organisms drawn from a narrow gene pool, like humans and corn, and less so with others. It's worth noting that, if we consider these mutations in the argument, we have to consider not only the children who are born and are weeded out, but all of the embryos conceived and lost as well.
Given how few conceptions actually make it to birth, and how many infants died young before the advent of modern medicine, humans didn't lose two out of four, they lost more like two out of eight-to-twelve.
Eliezer, I'm a little skeptical of your statement that sexual reproduction/recombination won't add information...
Can you provide an argument as to why none of this affects the "speed limit" (not even by a constant factor?)
"To sum up: The mathematician's bits here are very close to bits on a hard drive, because every DNA base that matters has to be supported by "one mutation, one death" to overcome per-base copying errors."
There are only twenty amino acids plus a stop code for each codon, so the theoretical information bound is 4.4 bits/codon, not 6 bits, even for coding DNA. A common amino acid, such as leucine, only requires two base pairs to specify; the third base pair can freely mutate without any phenotypic effects at all.
"Can you provide an ar...
Even in the argument, it applies to organisms that lose half of their offspring to selection. It's different for those that lose more, or less.
Among mammals, it's safe to say that the selection pressure per generation is on the rough order of 1 bit. Yes, many mammals give birth to more than 4 children, but neither does selection perfectly eliminate all but the most fit organisms. The speed limit on evolution is an upper bound, not an average.
One bit per generation equates to a selection pressure which kills half of each generation before they reproduce according to the first part of your post. Then you say 1 bit per generation is the most mammalian reproduction can sustain. But, more than hal...
"But, more than half of mammals (in many, perhaps most, species) die without reproducing. Wouldn't this result in a higher rate of selection and, therefore, more functional DNA?"
"Yes, many mammals give birth to more than 4 children, but neither does selection perfectly eliminate all but the most fit organisms. The speed limit on evolution is an upper bound, not an average."
But mammals have many ways of weeding out harmful variations, from antler fights to spermatozoa competition. And that's just if they have the four children. The provided 1 bit/generation figure isn't an upper bound, either.
Life spends a lot of time in non-equilibrium states as well, and those are the states in which evolution can operate most quickly.
"But basically, the 1 bit/generation bound is information-theoretic; it applies, not just to any species, but to any self-reproducing organism, even one based on RNA or silicon. The specifics of how information is utilized, in our case DNA -> mRNA -> protein, don't matter."
OK, and I'm familiar with information theory (less so with evolutionary biology, but I understand the basics) but I'm thinking that the 1 bit/generation bound is -- pardon the pun -- a bit misleading, since:
A lot -- I mean a lot -- of crazy assumptions are made without
"But basically, the 1 bit/generation bound is information-theoretic; it applies, not just to any species, but to any self-reproducing organism, even one based on RNA or silicon. The specifics of how information is utilized, in our case DNA -> mRNA -> protein, don't matter."
OK, and I'm familiar with information theory (less so with evolutionary biology, but I understand the basics) but I'm thinking that the 1 bit/generation bound is -- pardon the pun -- a bit misleading, since:
A lot -- I mean a lot -- of crazy assumptions are made without
David MacKay did a paper on this. Here's a quote from the abstract:
If variation is produced by mutation alone, then the entire population gains up to roughly 1 bit per generation. If variation is created by recombination, the population can gain O(G^0.5) bits per generation.
G is the size of the genome in bits.
I've been enjoying your evolution posts and wanted to toss in my own thoughts and see what I can learn.
"Our first lemma is a rule sometimes paraphrased as "one mutation, one death"."
Imagine that having a working copy of gene "E" is essential. Now suppose a mutation creates a broken gene "Ex". Animals that are heterozygous with "E" and "Ex" are fine and pass on their genes. Only homozygous "Ex" "Ex" result in a "death" that removes 2 mutations.
Now imagine that a duplic...
"But mammals have many ways of weeding out harmful variations, from antler fights to spermatozoa competition. And that's just if they have the four children. The provided 1 bit/generation figure isn't an upper bound, either."
Read a biology textbook, darn it. The DNA contents of a sperm have negligible impact on the sperm's ability to penetrate the egg. As for antler fights, it doesn't matter how individuals are removed from the gene pool. They can only be removed at a certain rate or else the species population goes to zero. Note than nonreproduc...
OK, I posted the following update to my blog entry:
Rereading the last few paragraphs of Eliezer's post, I see that he actually argues for his central claim -- that the human genome can’t contain more than 25MB of "meaningful DNA" -- on different (and much stronger) grounds than I thought! My apologies for not reading more carefully.
In particular, the argument has nothing to do with the number of generations since the dawn of time, and instead deals with the maximum number of DNA bases that can be simultaneously protected, in steady state, against...
Read a biology textbook, darn it. The DNA contents of a sperm have negligible impact on the sperm's ability to penetrate the egg.
Defective sperm - which are more-than-normally likely to be carry screwed-up DNA - is far less likely to reach the egg, and far less likely to penetrate it before a fully functional spermatozoan does. It's a weeding-out process.
As for antler fights, it doesn't matter how individuals are removed from the gene pool.Of course it does! Just not to the maximum-bit-rate argument.
Yes, but they must be balanced by states where i...
Eliezer, sorry for spamming, but I think I finally understand what you were getting at.
Von Neumann showed in the 50's that there's no in-principle limit to how big a computer one can build: even if some fraction p of the bits get corrupted at every time step, as long as p is smaller than some threshold one can use a hierarchical error-correcting code to correct the errors faster than they happen. Today we know that the same is true even for quantum computers.
What you're saying -- correct me if I'm wrong -- is that biological evolution never discovered thi...
Scott said: "25MB is enough for pretty much anything!"
Have people tried to measure the complexity of the 'interpreter' for the 25MB of 'tape' of DNA? Replication machinery is pretty complicated, possibly much more so than any genome.
Actually, Scott Aaronson, something you said in your second to last post made me think of another reason why the axiom "one mutation, one death" may not be true. Actually, it's just an elaberation of the point I made earlier but I thought I'd flesh it out a bit more.
The idea is that the more physically and mentally complex, and physically larger, a species gets, the more capable is it is of coping with detrimental genes and still surviving to reproduce. When you're physically bigger, and smarter, there's more 'surplus' resources to draw upon to h...
"Defective sperm - which are more-than-normally likely to be carry screwed-up DNA - is far less likely to reach the egg,"
Then the DNA never gets collected by researchers and included in the 10^-8 mutations/generation/base pair figure. If the actual rate of mutations are higher, but the non-detected mutations are weeded out, you still get the exact same result as if the rate of mutations is lower with no weeding-out.
"Of course it does! Just not to the maximum-bit-rate argument."
True.
"No, they mustn't. They can theoretically be kept ...
A mammalian gene pool can acquire at most 1 bit of information per generation.
Eliezer,
That's a very provocative, interestingly empirical, yet troublingly ambiguous statement. :)
I think it's important to note that evolution is very effective (within certain constraints) in figuring out ways to optimize not only genes but also genomes-- it seems probable that a large amount of said "bits" have been on the level of structural or mechanical optimizations.
These structural/mechanical optimizations might in turn involve mechanisms by which to use existi...
Wiseman, if it's true that (1) copying DNA inherently incurs a 10^-8 probability of error per base pair, and that (2) evolution hasn't invented any von-Neumann-type error-correction mechanism, then all the objections raised by you and others (and by me, earlier!) are irrelevant.
In particular, it doesn't matter how capable a species is of coping with a few detrimental mutations. For if the mutation rate is higher than what natural selection can correct, the species will just keep on mutating, from one generation to the next, until the mutations finally do ...
Aaronson: What you're saying -- correct me if I'm wrong -- is that biological evolution never discovered this fact [error-correcting codes].
You're not wrong. As you point out, it would halt all beneficial mutations as well. Plus there'd be some difficulty in crossover. Can evolution ever invent something like this? Maybe, or maybe it could just invent more efficient copying methods with 10^-10 error rate. And then a billion years later, much more complex organisms would abound. All of this is irrelevant, given that DNA is on the way out in much less...
I think that a subset of Fly's objections may be valid, especially the ones about sexual selection concentrating harmful mutations in a small subset of the population. This could plausibly increase the number of bits by a significant factor. OTOH, 25M is an upper bound, so the actual number of bits could easily still be less.
Great point about evolution not discovering hierarchical error-correcting code Scott A. Chris Phoenix frequently makes similar points about molecular nanotechnology in response to its critics.
Regarding the earlier posts point about ...
Scott A. I wasn't suggesting DNA would magically not mutate after it had evolved towards sophistication, only that the system of genes/DNA that govern a system would become robust enough so it would be immune to the effects of the mutations.
Anway, evolution does not have to "correct" these mutations, as long as the organism can survive with them, they have as much a chance of mutating to a neutral, positive, or other equally detremental state as it has of becoming worse. As a genome becomes larger and larger, it can cope with the same ratio of mu...
Wiseman, let M be the number of "functional" base pairs that get mutated per generation, and let C be the number of those base pairs that natural selection can affect per generation. Then if M>>C, the problem is that the base pairs will become mostly (though not entirely) random junk, regardless of what natural selection does. This is a point about random walks that has nothing to do with biology.
To illustrate, suppose we have an n-bit string. At every time step, we can change one of the bits to anything we want, but then two bits get ch...
"'Life spends a lot of time in non-equilibrium states as well, and those are the states in which evolution can operate most quickly.'
Yes, but they must be balanced by states where it operates more slowly. You can certainly have a situation where 1.5 bits are added in odd years and .5 bits in even years, but it's a wash: you still get 1 bit/year long term."
This seems to contradict your earlier assertion that the 1 bit/generation rate is "an upper bound, not an average." It seems to me to be more analogous to a roulette wheel or the Secon...
With sufficiently large selection populations, it's not clear to me how anything could be better than natural selection, since natural selection is what the system is trying to beat. Any model of natural selection will necessarily contain inaccuracies.
So here's my question: Can you actually do asymptotically better than natural natural selection by applying an error-correcting code that doesn't hamper beneficial mutations?
In principle, yes. In a given generation, all we want is a mutation rate that's nonzero, but below the rate that natural selection can correct. That way we can maintain a steady state indefinitely (if we're indeed at a local optimum), but still give beneficial mutations a chance to take over.
Now with DNA, the mutation rate is fixed at ~10^-8. Since we need to be able to weed out bad...
Fly: Imagine that having a working copy of gene "E" is essential. Now suppose a mutation creates a broken gene "Ex". Animals that are heterozygous with "E" and "Ex" are fine and pass on their genes. Only homozygous "Ex" "Ex" result in a "death" that removes 2 mutations.
Now imagine that a duplication event gives four copies of "E". In this example an animal would only need one working gene out of the four possible copies. When the rare "Ex" "Ex" "Ex&quo...
Eliezer, could you provide a link to this result? Something looks wrong about it.
Fisher's fundamental theorem of natural selection says the rate of natural selection is directly proportional to the variance in additive fitness in the population. At first sight that looks incompatible with your result.
You mention a site with selection at 0.01%. This would take a very long time for selection to act, and it would require that there not be stronger selection on any nearby linked site. It seems implausible that this site would have been selected before, with th...
"Now with DNA, the mutation rate is fixed at ~10^-8."
Well no, it isn't. Not to get too complicated, usually the mutation rate is lower than that, but occasionally things happen that bring the mutation rate rather higher. We have things like DNA repair mechanisms that are mutagenic and others that are less so, and when the former get turned on we get a burst of mutations.
"Since we need to be able to weed out bad mutations, this imposes an upper bound of ~10^8 on the number of functional base pairs."
Definitely no more than 10^8 sites that...
If a species can deal with detrimental mutations for several generations, then that simply means that the species has more time to weed out those really bad mutations, making the "one mutation, one death" equation inadequate to describe the die off rate based purely on the mutation rate. Yes, new mutations pop up all the time, but unless those mutations directly add on to the detrimental effects of previous mutations, the species still will survive another generation.
To add on to my other argument that we "know too little" to make hard ...
A comment from Shtetl-Optimized discussion:
It’s actually a common misconception that biological systems should have mechanisms that allow a certain number of mutations for the purpose of accruing beneficial adaptations. From an evolutionary perspective, all genes should favor the highest possible fidelity copies. Any genes that have any lower copying fidelity will necessarily have fewer copies in future generations and thus lose the evolutionary game to a gene with higher copying fidelity.
Remember, folks, evolution doesn't work for the good of the species,...
From an evolutionary perspective, all genes should favor the highest possible fidelity copies.
Hmm... Suppose there are two separated populations, identical except that one has a gene that makes the mutation rate negligibly low. Naturally the mutating population will acquire greater variation over time. If the environment shifts, the homogeneous population may be wiped out but part of the diverse population may survive. So in this case, lower-fidelity copying is more fit in the long run. This is highly contrived, of course.
Disagree. Any genome that has lower copy fidelity will only be removed from the gene pool if the errors in copy actually make the resultant organism unable to survive and reproduce, otherwise it's irrelevant how similar the copied genese are to the original. If the copy error rate produces detrimental genes at a rate that will not cause the species to go extinct, it will allow for any benificial mutations to arise and spread themselves throughout the gene pool at 'leisure'. As long as those positive genese are attached to a genome structure which produces ...
Remember, folks, evolution doesn't work for the good of the species, and there's no Evolution Fairy who tries to ensure its own continued freedom of action. It's just a statistical property of some genes winning out over others.
Right, but if the mutation rate for a given biochemistry is itself relatively immutable, then this might be a case where group selection actually works. In other words, one can imagine RNA, DNA, and other replicators fighting it out in the primordial soup, with the winning replicator being the one with the best mutation properties.
Eliezer: "Fly, you've just postulated four copies of the same gene, so that one death will remove four mutations. But these four copies will suffer mutations four times as often. Unless I'm missing something, this doesn't increase the bound on how much non-redundant information can be supported by one death. :)"
Yeah, you are right. You only gain if the redundancy means that the fitness hit is sufficiently minor that more than four errors could be removed with a single death.
The "one death, one mutation" rule applies if the mutation imme...
"On average all but 2 children must either die or fail to reproduce. Otherwise the species population very quickly goes to zero or infinity."
A population of infinity is of course non-existing. An "infinity" population is not just a mathematical impossibility. What you forget to take into account is that a growing population changes the conditions of the population, and changes selection pressure.
Furthermore you consider evolution of just a single species. But all species are considered to be descendants of the same LUCA (Last Universal...
Taka, if you don't draw conclusions from simplified models, then you can't make any decisions ever.
So let me be more concrete. Because every model is a simplification. What I mean to say is that the model used here, is far too simple to draw conclusions.
The central statement of this entry is "There's a limit on how much complexity an evolution can support against the degenerative pressure of copying errors".
In order to check the model, the statement should be quantified, so it can be matched with measurements. Maybe something like "the genome of a species can have maximally 50k genes". That requires that the model should be enhanced....
"This increases the potential number of semi-meaningful bases (bases such that some mutations have no effect but other mutations have detrimental effect) but cancels out the ability to store any increased information in such bases."
If 27% of all mutations have absolutely no effect, the "one mutation = one death" rule is broken, and so more information can be stored because the effective mutation rate is lower (this also means, of course, that the rate of beneficial mutations is lower). So it may be a 40 MB bound instead of a 25 MB bound...
MacKay's paper talks about gaining bits as in bits on a hard drive
I don't think MacKay's paper even has a coherent concept of information at all. As far as I can tell, in MacKay's model, if I give you a completely randomized 100 Mb hard drive, then I've just given you 50 Mb of useful information, because half of the bits are correct (we just don't know which ones.) This is not a useful model.
Rolf,
If you look at equation 3 of MacKay's paper, you'll see that he defines information in terms of frequency of an allele in a population, so you'd have to provide a whole population of randomized hard drives, and if you did so, the population would have zero information.
First, there is the correct point that our mutation rate has been at a steady decline - the first couple of billion years had a much higher rate of data encoding than the last couple of billion years, of which, the former had a much higher.
Second, there is the point that a significant portion of pregnancies are failures - we could possibly double the rate of data encoding from that alone, presuming all of one of those bits is improvement on genetic repair and similar functionality. (Reducing mutation rates of critical genes.)
Third, multiple populations co...
If you look at equation 3 of MacKay's paper, you'll see that he defines information in terms of frequency of an allele in a population
I apologize, my statement was ambiguous. The topic of Eliezer's post is how much information is in an individual organism's genome, since that's what limits the complexity of a single organism, which is what I'm talking about.
Equation 3 addresses the holistic information of the species, which I find irrelevant to the topic at hand. Maybe Alice, Bob, and Charlie's DNA could together have up to 75 MB of data in some holographi...
Humans can do things that evolutions probably can't do period over the expected lifetime of the universe. As the eminent biologist Cynthia Kenyon once put it at a dinner I had the honor of attending, "One grad student can do things in an hour that evolution could not do in a billion years." According to biologists' best current knowledge, evolutions have invented a fully rotating wheel on a grand total of three occasions.
FYI, God did not design humans, we are all naturally evolved. Evolution can and has indeed designed lots of fully rotating ...
OK, Let me make my point clearer, why we can't calculate the actual complexity limit of working DNA:
1.) Not all mutations are bad. Accepted knowledge: most are simply neutral, a few are bad, and even a fewer are good.
2.) If the mutations are good or neutral, they should effectivly be subtracted from the mutation rate, as they do not contribute to the "one mutation, one death" axiom because good/neutral mutations do not increase death probability.
3.) The mutations will not accumulate either, over many generations, if they are good/neutral. If a ...
Anything that a human can do, natural selection can do, by definition.
Ah, yes, the old "Einstein's mother must have been one heck of a physicist" argument, or "Shakespeare only wrote what his parents and teachers taught him to write: Words."
Even in the sense of Kolmogorov complexity / algorithmic information, humans can have complexity exceeding the complexity of natural selection because we are only a single one out of millions of species to have ever evolved.
And the things humans "do" are completely out of character for the...
Rolf,
Would you agree that the information-theoretic increase in the amount of adaptive data in a single organism is still limited by O(1) bits in Mackay's model?
I can't really process this query until you relate the words you've used to the math MacKay uses, i.e., give me some equations. Also, Eliezer is pretty clearly talking about information in populations, not just single genomes. For example, he wrote, "This 1 bit per generation has to be divided up among all the genetic variants being selected on, for the whole population. It's not 1 bit pe...
Even if most mutations is neutral, that just says that most of the genome don't contain any information. If you flip a base and it doesn't make any difference, then you've just proved that it was junk-DNA, right?
Hi Erik,
It's not junk DNA, it merely has usefulness in many different configurations. Perhaps if the mutation would be to skip a base pair entirely, rather than just mis-copy it, it would be more likely to be detrimental.
"If you flip a base and it doesn't make any difference, then you've just proved that it was junk-DNA, right?"
Not quite. Certain bases in the protein-coding sections of genes (i.e., definitely not junk DNA!) can be flipped without changing the resulting proteins. This can happen because there are 64 different codons, but only 20 different amino acids are used to build proteins, so the DNA code is not one-to-one.
It might be safer to say that if you delete the base and it makes no difference, then it was junk, but even this will run into problems...
Here are some mutation strategies that life uses that may be of value in programming towards AI-- (evolving software is part of the program- true?)
1)adaptive mutation (aka directed mutation)--
It has been observed that bacteria will mutate more quickly when under stress.
http://www.ncbi.nlm.nih.gov/sites/entrez?cmd=Retrieve&db=PubMed&list_uids=11433357&dopt=AbstractPlus
http://newsinfo.iu.edu/news/page/normal/1160.html
http://www.iscid.org/boards/ubb-get_topic-f-1-t-000196.html
2)purposeful mutation (How long do you suppose that description will...
I think MacKay's "If variation is created by recombination, the population can gain O(G^0.5) bits per generation." is correct. Here's my way of thinking about it. Suppose we take two random bit strings of length G, each with G/2-G^0.5 zeros and G/2+G^0.5 ones, randomly mix them twice, then throw away the result has fewer ones. What is the expected number of ones in the surviving mixed string? It's G/2+G^0.5+O(G^0.5).
Or here's another way to think about it. Parent A has 100 good (i.e., above average fitness) genes and 100 bad genes. Same with pare...
Wiseman: "It's not junk DNA, it merely has usefulness in many different configurations."
Perhaps it was unfortunate to use the term junk DNA. What I was thinking of was more on the lines of information content. If a given base is useful in several configurations, it contains that much less information.
If base X has to be e.g. guanine to have its effect, that is one out of four possible states, i.e. 2 bits of information. If it could be either guanine or thymine, then it only contains one bit.
It may be that the actual human genome uses more than 5...
How can we define the information content of the mutation responsible for Huntington's Disease? It occurs in a non-coding section, it's technically a collection of similiar mutations, and it seems to have something to do with the physical structure of the chromosome rather than coding in the simple sense.
A point to note is that corrupting pressure to genome through adverse point mutations occurring on protein coding DNA regions are partly counterbalanced by selection happening already before birth, in form of miscarriages (late and early) and cell death or cell inefficiency during earlier stages of the germline development, even before fertilization.
Even if the value of 1 bit per generation holds true for addition of new 'relevant' information, the above acts as additional positive factor that only acts to negate the degrading effects of random mutation...
Wei Dai, being able to send 10 bits each with a 60% probability of being correct, is not the same as being able to transmit 6 bits of mathematical information. It would be if you knew which 6 bits would be correct, but you don't. I'm not sure how to bridge the disconnect between variance going as the square root of a randomized genome, and the obvious argument that eliminating half the population is only going to get you 1 bit of mathematical information. It would probably be obvious if I'd spent more time on maxentropy methods.
Petteri, I hadn't known t...
Petteri, I think I can explain. First throw away the lemma that says one death can't remove more than one gene. That's a red herring.
Imagine a population of asexual bacterial. Imagine that they have a collection of sites that will kill them immediately if any one of those sites mutates. If a cell averages 1 such mutation per generation, it will on average produce one live and one dead daughter cell per generation. It will not survive. This is an absolute limit for the mutation rate, for that kind of mutation.
Now suppose that it has a lot of sites that resu...
Ah, yes, the old "Einstein's mother must have been one heck of a physicist" argument, or "Shakespeare only wrote what his parents and teachers taught him to write: Words."...Even in the sense of Kolmogorov complexity / algorithmic information, humans can have complexity exceeding the complexity of natural selection because we are only a single one out of millions of species to have ever evolved.
And the things humans "do" are completely out of character for the things that natural selection actually does, as opposed to doing &qu
Eliezer, you are mistaken that eliminating half of the population gives only 1 bit of mathematical information. If you have a population of N individuals, there are C(N,N/2) = N!/((N/2)!*(N/2)!) different ways to eliminate half of them. See http://en.wikipedia.org/wiki/Combination. Therefore it takes log_2(C(N,N/2)) (which is O(N)) bits to specify how to eliminate half of the population.
So, it appears that with sexual recombination, the maximum number of bits a species can gain per generation is min(O(G^0.5), O(N)).
Oh, sending 10 bits each with a 60% proba...
"Wei Dai, being able to send 10 bits each with a 60% probability of being correct, is not the same as being able to transmit 6 bits of mathematical information. It would be if you knew which 6 bits would be correct, but you don't."
"Given sexuality and chromosome assortment but no recombination, a species with 100 chromosomes can evolve much faster than an asexual bacterial population!"
No, it can't. Suppose that you want to maintain the genome against a mutation pressure of one hundred bits per generation (one base flip/chromosome, to ma...
Tom McCabe, having 100 chromosomes with no recombination lets you maintain the genome against a mutation pressure of 10 bits per generation, not 100. (See my earlier comment.) But that's still much better than 1 bit per generation, which is what you get with no sex.
Wei Dai, that's the amount of Bayesian information a human observer could extract from a message deliberately encoded into eliminating a very precisely chosen half of the population. It's not the amount of information that's going to end up in the global allele frequencies of a sexually reshuffled gene pool.
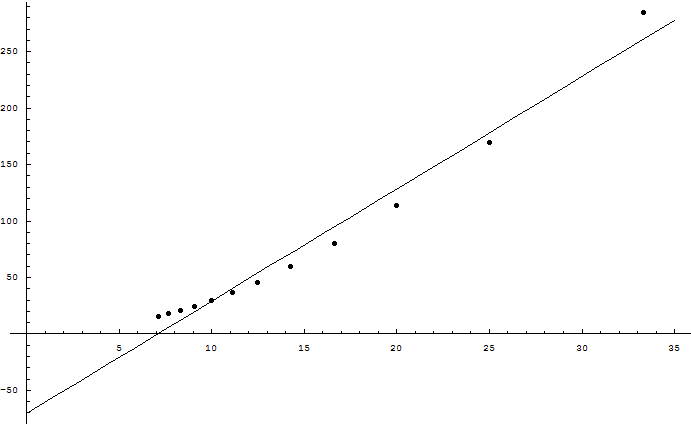
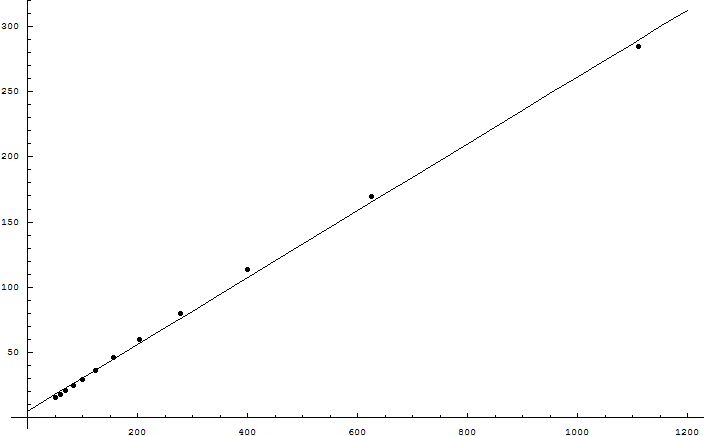
I found the MacKay logic disturbingly persuasive. So I wrote a Python program to test the hypothesis; it's now attached to the main article. Increasing the genome size did not increase the supported bits as the square root of the genome size, though ...
The discussion Iâm reading is interesting from a computational perspective. From the biology perspective there is a basic problem in the premise and this could be due to unexamined bias.
The âreductionistâ model for biology is no longer considered workable. Here is a website that includes a discussion of this with good links to other articles.
http://www.psrast.org/strohmnewgen.htm
The âreductionistâ model is no longer considered valuable in medicine either. Check this link:
http://medicine.plosjournals.org/perlserv/?request=get-document&do...
Eliezer, I have to admit I'm not studied on the field enough, and I've not read papers on this particular. The initial cell bodies of a gamete of course come from the parent cell.
However after that, they have to keep on living. And they do this using their own genetic material to support and repair themselves, manufacturing new cell bodies, enzymes and other constituting proteins as old bodies deterioriate. All ovum in ovaries are present at birth of the female, thus having to be able to maintain their function at least up to menopause. This makes them on...
Found factual errors from my previous post, after doing last round of research. Should've done it before submitting...
The ova are not in haploid state for the lifetime of the female, but in diploid state, arrested at prophase of meiosis I. Couldn't find out how much cellular activity they have at this stage, but anyway, there is thus still one DNA replication at only a short period before possible fertilization. This renders much of my above argumentation mostly null. Indeed could be the DNA of ova and spermatozoa isn't expressed at all at the haploid cell. This would leave the pre-birth selection pressure only to spontaneous zygote abortions (which have other explanations than mere point mutations to them as well).
Meh, not thinking straight anymore. There are no DNA replications at meiosis, although the recombination does happen here. But still, if there's no cellular activity during the arrested prophase, the DNA isn't tested anyway. Now I go to sleep, hoping I wont make any more mistakes.
Cyan,
> I can't really process this query until you relate the words you've used to the math MacKay uses
On Page 1, MacKay posits x as a bit-sequence of an individual. Pick an individual an random. The question at hand is whether the Shannon Entropy of x, for that individual, decreases at a rate of O(1) per generation.
This would be one way to quantify the information-theoretic adaptive complexity of an individual's DNA.
In contrast, if for some odd reason you wanted to measure the total information-theoretic adaptive complexity of the entire species, then ...
Eliezer, the simulation is a great idea. I've used it to test the following hypothesis: given sufficiently large population and genome size, the number of useful bits that a sexual species can maintain against a mutation probability (per base) of m is O(1/m^2). The competing hypothesis is the one given in your opening post, namely that it's O(1/m).
To do this, I set Number=1000, Genome=1000, Beneficial=0, and let Mutation range from 0.03 to 0.14 in steps of 0.01. Then I plotted Fitness (which in the program equals the number of useful bits in the genome) a...
No, No, No, No!!
First of all I strongly object to the use of the word 'information' in this article. There is no limit on the amount of information in the gene if by information we mean anything like Kolmogorov complexity. Any extra random string of bases that get tacked on to the DNA sequence is information by any reasonable definition. If you mean something like Shannon's entropy then things are just totally unclear because you need to tell us what distribution you are measuring the information of.
As far as the actual conclusions your post is too uncl...
"Given sexuality and chromosome assortment but no recombination, a species with 100 chromosomes can evolve much faster than an asexual bacterial population!"
No, it can't. Suppose that you want to maintain the genome against a mutation pressure of one hundred bits per generation (one base flip/chromosome, to make it simple). Each member of the population, on average, will still have fifty good chromosomes. But you have to select on the individual level, and you can't let only those organisms with no bad chromosomes reproduce: the chances of such a...
logicnazi,
Wei Dai's post doesn't make sense except in the context of MacKay's paper. If you've read the paper thoroughly, it should be pretty clear what he's talking about.
The fact that the MacKay's fitness function is the distance to a "master" genome has nothing to do with how much information god could convey to someone. It's just a way to model constant environmental conditions, like the sort of thing that has kept modern sharks around since they evolved 100 million years ago.
His model about as simplified as one could get and still have desc...
"The second problem in MacKay's analysis is that he assumes sexual mating occurs at random. It is easy to give a counterexample to his bound in a society where people choose mates wholly on the basis of their fitness (i.e. in his model distance from the ideal bitstring)."
Logicnazi, Eliezer's model may do that somewhat and would be easy to adapt to do what you want.
I don't know python, so I may be wrong when I suppose that the children in his model come out sorted. The next generation they receive a random number of mutations, typically 10, and th...
Wei, did you run at only 300 generations and if so, did you check to see if the fitness had reached equilibrium? I noticed it was declining but rather slowly even after 2000 generations with a genome that size.
(Will try running my own sims tomorrow, got to complete today's post today.)
I only ran 300 generations, but I just redid them with 5000 generations (which took a few hours), and the results aren't much different. See plots at http://www.weidai.com/fitness/plot3.png and http://www.weidai.com/fitness/plot4.png.
I also reran the simulations with Number=100. Fitness is lower at all values of Mutation (by about 1/3), but it's still linear in 1/Mutation^2, not 1/Mutation. The relationship between Fitness and Number is not clear to me at this point. As Eliezer said, the combinatorial argument I gave isn't really relevant.
Also, with Number...
Wei, the result of my own program makes no sense to me. It wasn't predicted by any of our prior arguments. MacKay says that the supportable information should go as the square root of the genome size, not that supportable information should go as the inverse square of the mutation rate. We're not getting a result that fits even with what MacKay said, let alone with what Williams said; and, I should point out, we're also not getting a result that fits with there being <25,000 protein-coding regions in the human genome.
Maybe you can't sort and truncate...
Eliezer, MacKay actually does predict what we have observed in the simulations. Specifically equation 28 predicts it if you let δf=f instead of δf=f-1/2. You need to make that change to the equation because in your simulation with Beneficial=0, mutations only flips 1 bits to 0, whereas in MacKay's model mutations also flip 0 bits to 1 with equal probability.
Wei, MacKay says in a footnote that the size of the maximally supported genome goes as 1/m^2, but as I understand his logic, this is because of larger genomes creating a factor of sqrt(G) improvement in how much information can be supported against a given mutation rate. Haven't had time yet to examine equation 28 in detail.
Stable population of asexual haploid bacteria considering only lethal mutations:
Let "G" be the genome string length in base pairs.
Let "M" be the mutations per base pair per division.
Let "numberOfDivisions" be the average number divisions a bacterium undergoes before dying.
Let "survivalFraction" be the probability that division produces another viable bacterium.
survivalFraction = (1 - M)**G. (Assuming mutation events are independent.)
1 = numberOfDivisions x survivalFraction. (Assuming population size is st...
Eliezer, I just noticed that you've updated the main post again. The paper by Worden that you link to makes the mistake of assuming no crossing or even chromosomal assortment, as you can see from the following quotes. It's not surprising that sex doesn't help under those assumptions.
(being quote)
Next consider what happens to one of the haploid genotypes j in one generation. Through random mating, it gets paired with another haploid genotype k, with probability q; then the pair have a probability of surviving sigmajk.
...
(b) Crossing: Similarly, in a real...
Wei, I need to find enough time to go over the math with a fine-toothed comb, both in Worden's paper and MacKay's. Worden says his result holds for sexual reproduction and I'm not sure the simulation disproves that; in my own experiments, sustainable information did go as log(children). Rather than Worden being wrong, it may be that one bit of mathematical information per generation, suffices to cancel out an amount of mutation at equilibrium which goes as the square root of the number of mutations - for reasons similar to the ones you gave above. One d...
Eliezer: "If the entire human genome of 3 billion DNA bases could be meaningful, it's not clear why it would contain <25,000 genes"
I wouldn't say we know enough about biological mechanics to say we necessarily need more protein coding-DNA that protein-regulating DNA. If you think about it, collagen the protein is used in everything from skin, tendons, ligaments, muscles, fascia, etc. But you can't code for all of those uses of collagen just by HAVING the collagen code in the DNA, you need regulating code to instruct when/where/how to use it.
Al...
MacKay comments on Kimura's and Worden's work and its relation to his own on page 12 of the paper. In particular, he notes that in Worden's model, fitness isn't defined as a relative quality involving competition with other individuals in the population; rather, one's genotype determines the probability of having children absolutely. MacKay says that this is how Worden proves a speed limit of one bit per generation even with sexual reproduction, but he doesn't do any math on the point.
"The big puzzle here is the inverse square of the mutation rate. The example of improvement in a starting population with a randomized genome of maximum variance, which can't be used to send a strongly informative message, doesn't explain the maintenance of nearly all information in a genome."
(hacks program for asexual reproduction)
I've found that, assuming asexual reproduction, the genome's useful information really does scale nice and linearly with the mutation rate. The amount of maintainable information decreases significantly (by a factor the three or so, in the original test data).
If you take a population of organisms, and you divide it arbitrarily into 2 groups, and you show the 2 groups to God and ask, "Which one of these groups is, on average, more fit?", and God tells you, then you have been given 1 bit of information.
But if you take a population of organisms, and ask God to divide it into 2 groups, one consisting of organisms of above-average fitness, and one consisting of organisms of below-average fitness, that gives you a lot more than 1 bit. It takes n lg(n) bits to sort the population; then you subtract out the ...
I was curious about the remark that simulation results differed from theoretical ones, so I tried some test runs. I think the difference is due to sexual reproduction.
Eliezer's code uses random mating. I modified it to use asexual reproduction or assortative mating to see what difference that made.
Asexual reproduction:
mutation rate 0.1 gave 6 bits preserved
0.05 preserved 12-13 bits
0.025 preserved 27
increasing population size from 100 to 1000 bumped this to 28
decreasing the beneficial mutation rate brought it down to 27 again
so the actual preserved i...
According to http://www.technologyreview.com/view/513781/moores-law-and-the-origin-of-life/?utm_content=bufferc6744&utm_source=buffer&utm_medium=twitter&utm_campaign=Buffer http://arxiv.org/abs/1304.3381
This rate is increasing with time, or the earth is younger than life.
{kind=link}
{kind=link}
Followup to: An Alien God, The Wonder of Evolution, Evolutions Are Stupid
Yesterday, I wrote:
But then, natural selection has not been running for a mere million years. It's been running for 3.85 billion years. That's enough to do something natural selection "could not do in a billion years" three times. Surely the cumulative power of natural selection is beyond human intelligence?
Not necessarily. There's a limit on how much complexity an evolution can support against the degenerative pressure of copying errors.
(Warning: A simulation I wrote to verify the following arguments did not return the expected results. See addendum and comments.)
(Addendum 2: This discussion has now been summarized in the Less Wrong Wiki. I recommend reading that instead.)
The vast majority of mutations are either neutral or detrimental; here we are focusing on detrimental mutations. At equilibrium, the rate at which a detrimental mutation is introduced by copying errors, will equal the rate at which it is eliminated by selection.
A copying error introduces a single instantiation of the mutated gene. A death eliminates a single instantiation of the mutated gene. (We'll ignore the possibility that it's a homozygote, etc; a failure to mate also works, etc.) If the mutation is severely detrimental, it will be eliminated very quickly - the embryo might just fail to develop. But if the mutation only leads to a 0.01% probability of dying, it might spread to 10,000 people before one of them died. On average, one detrimental mutation leads to one death; the weaker the selection pressure against it, the more likely it is to spread. Again, at equilibrium, copying errors will introduce mutations at the same rate that selection eliminates them. One mutation, one death.
This means that you need the same amount of selection pressure to keep a gene intact, whether it's a relatively important gene or a relatively unimportant one. The more genes are around, the more selection pressure required. Under too much selection pressure - too many children eliminated in each generation - a species will die out.
We can quantify selection pressure as follows: Suppose that 2 parents give birth to an average of 16 children. On average all but 2 children must either die or fail to reproduce. Otherwise the species population very quickly goes to zero or infinity. From 16 possibilities, all but 2 are eliminated - we can call this 3 bits of selection pressure. Not bits like bytes on a hard drive, but mathematician's bits, information-theoretical bits; one bit is the ability to eliminate half the possibilities. This is the speed limit on evolution.
Among mammals, it's safe to say that the selection pressure per generation is on the rough order of 1 bit. Yes, many mammals give birth to more than 4 children, but neither does selection perfectly eliminate all but the most fit organisms. The speed limit on evolution is an upper bound, not an average.
This 1 bit per generation has to be divided up among all the genetic variants being selected on, for the whole population. It's not 1 bit per organism per generation, it's 1 bit per gene pool per generation. Suppose there's some amazingly beneficial mutation making the rounds, so that organisms with the mutation have 50% more offspring. And suppose there's another less beneficial mutation, that only contributes 1% to fitness. Very often, an organism that lacks the 1% mutation, but has the 50% mutation, will outreproduce another who has the 1% mutation but not the 50% mutation.
There are limiting forces on variance; going from 10 to 20 children is harder than going from 1 to 2 children. There's only so much selection to go around, and beneficial mutations compete to be promoted by it (metaphorically speaking). There's an upper bound, a speed limit to evolution: If Nature kills off a grand total of half the children, then the gene pool of the next generation can acquire a grand total of 1 bit of information.
I am informed that this speed limit holds even with semi-isolated breeding subpopulations, sexual reproduction, chromosomal linkages, and other complications.
Let's repeat that. It's worth repeating. A mammalian gene pool can acquire at most 1 bit of information per generation.
Among mammals, the rate of DNA copying errors is roughly 10^-8 per base per generation. Copy a hundred million DNA bases, and on average, one will copy incorrectly. One mutation, one death; each non-junk base of DNA soaks up the same amount of selection pressure to counter the degenerative pressure of copying errors. It's a truism among biologists that most selection pressure goes toward maintaining existing genetic information, rather than promoting new mutations.
Natural selection probably hit its complexity bound no more than a hundred million generations after multicellular organisms got started. Since then, over the last 600 million years, evolutions have substituted new complexity for lost complexity, rather than accumulating adaptations. Anyone who doubts this should read George Williams's classic "Adaptation and Natural Selection", which treats the point at much greater length.
In material terms, a Homo sapiens genome contains roughly 3 billion bases. We can see, however, that mammalian selection pressures aren't going to support 3 billion bases of useful information. This was realized on purely mathematical grounds before "junk DNA" was discovered, before the Genome Project announced that humans probably had only 20-25,000 protein-coding genes. Yes, there's genetic information that doesn't code for proteins - all sorts of regulatory regions and such. But it is an excellent bet that nearly all the DNA which appears to be junk, really is junk. Because, roughly speaking, an evolution isn't going to support more than 10^8 meaningful bases with 1 bit of selection pressure and a 10^-8 error rate.
Each base is 2 bits. A byte is 8 bits. So the meaningful DNA specifying a human must fit into at most 25 megabytes.
(Pause.)
Yes. Really.
And the Human Genome Project gave the final confirmation. 25,000 genes plus regulatory regions will fit in 100,000,000 bases with lots of room to spare.
Amazing, isn't it?
Addendum: genetics.py, a simple Python program that simulates mutation and selection in a sexually reproducing population, is failing to match the result described above. Sexual recombination is random, each pair of parents have 4 children, and the top half of the population is selected each time. Wei Dai rewrote the program in C++ and reports that the supportable amount of genetic information increases as the inverse square of the mutation rate(?!) which if generally true would make it possible for the entire human genome to be meaningful.
In the above post, George Williams's arguments date back to 1966, and the result that the human genome contains <25,000 protein-coding regions comes from the Genome Project. The argument that 2 parents having 16 children with 2 surviving implies a speed limit of 3 bits per generation was found here, and I understand that it dates back to Kimura's work in the 1950s. However, the attempt to calculate a specific bound of 25 megabytes was my own.
It's possible that the simulation contains a bug, or that I used unrealistic assumptions. If the entire human genome of 3 billion DNA bases could be meaningful, it's not clear why it would contain <25,000 genes. Empirically, an average of O(1) bits of genetic information per generation seems to square well with observed evolutionary times; we don't actually see species gaining thousands of bits per generation. There is also no reason to believe that a dog has greater morphological or biochemical complexity than a dinosaur. In short, only the math I tried to calculate myself should be regarded as having failed, not the beliefs that are wider currency in evolutionary biology. But until I understand what's going on, I would suggest citing only George Williams's arguments and the Genome Project result, not the specific mathematical calculation shown above.