I think there's this problem that occurs often when explaining something technical. Let's say you wanted to explain how a computer works. You could pick a specific computer, e.g. a Macbook Pro Retina. This would hang together nicely as an item, you could explain, in principle, why each specific bit of it was there and was designed the way it was. Of course, this would be insanely complicated for a beginner. They'd come away without understanding (in part because they can't triangulate from other computer architectures to what you've taught them about this one), nor intuition (because they can't leverage what you've taught them about this one to others).
You could instead come up with a much simplified toy model. It has all the bits computers standardly have (maybe even bits which are mutually exclusive in actual computers, but which are both important to know about). Here you couldn't even in principle explain why each given bit is there. For some components, there would truly be no reason to have both. Still, this model is much easier to understand, and can actually develop useful intuitions and explain key concepts.
I feel a similar difficulty in trying to understand how transformers work. I could pick a random recent ML paper and try and understand that architecture, or I could read about the toy models that people use to explain them online. What I would love is if there was something that was simple-ish, while also being a kind of average example of a transformer. Only then would I feel I'd actually understood what needs understanding.
What follows is my best understanding of that kind of "average" transformer (at least for text-continuation). Very interested to hear about any innaccuracies or improvements!
Legend:
- Data Flow: Dark Gray
- Simple Components: Lilac
- Encapsulated Components: Purple
- Processes: Italics
Diagram 1 represents the whole transformer model, abstracting from the internal details of the transformer block.
Diagram 2 represents a transformer block, abstracting from the internal details of one attention head.
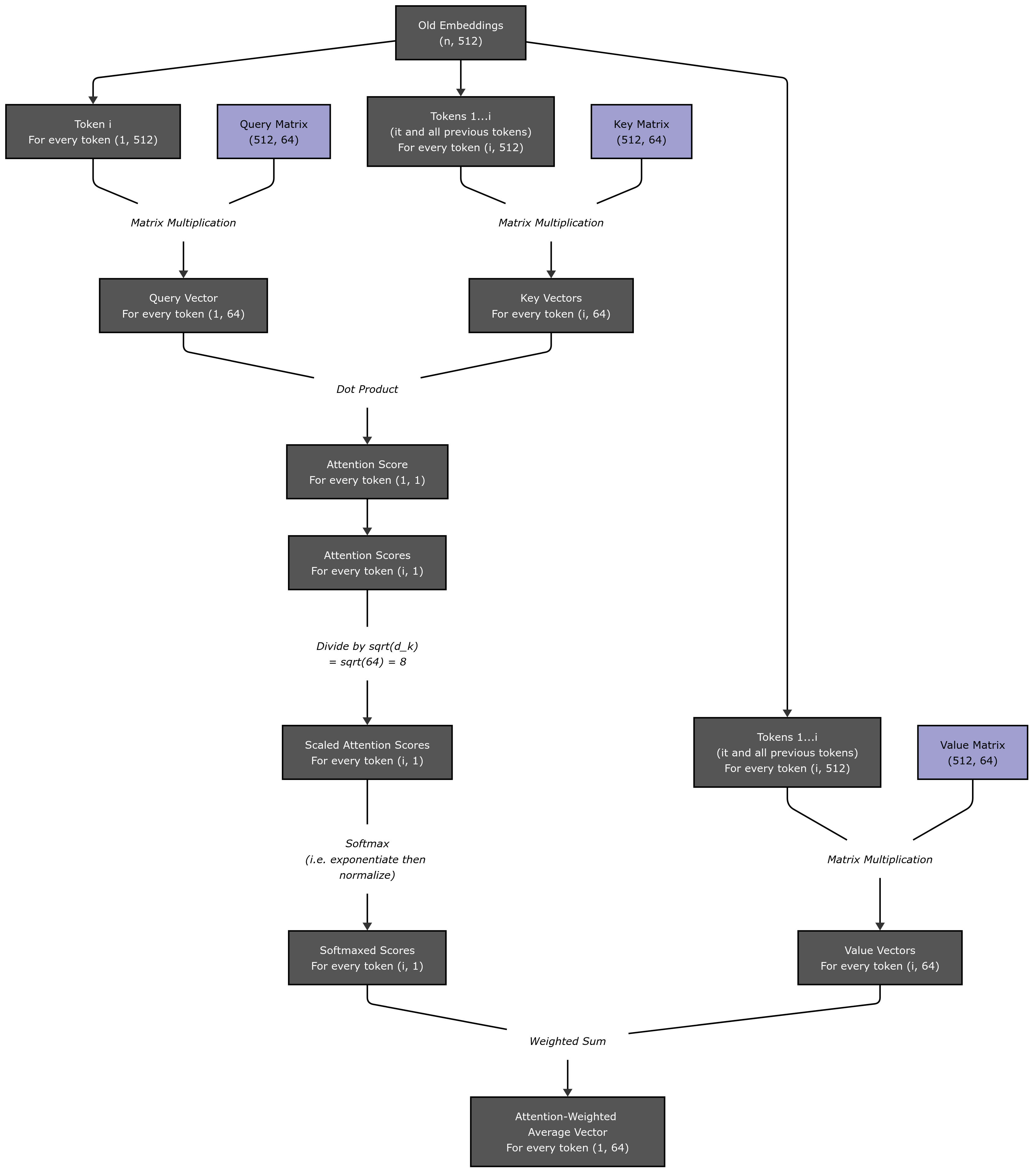
Diagram 3 represents an attention head.
(A note about the kludgy dimension notation I'm using: (x,y) is how I’m representing a matrix with x rows and y columns/y values per row. Sometimes, when I want to consider some number of matrices of dimensions (x,y) I say something like “n x (x,y)” rather than (n,x,y). This is because the operations in question are only being applied to each (x,y) on its own, not all the (x,y)’s collectively.)
Diagram 1: A Transformer
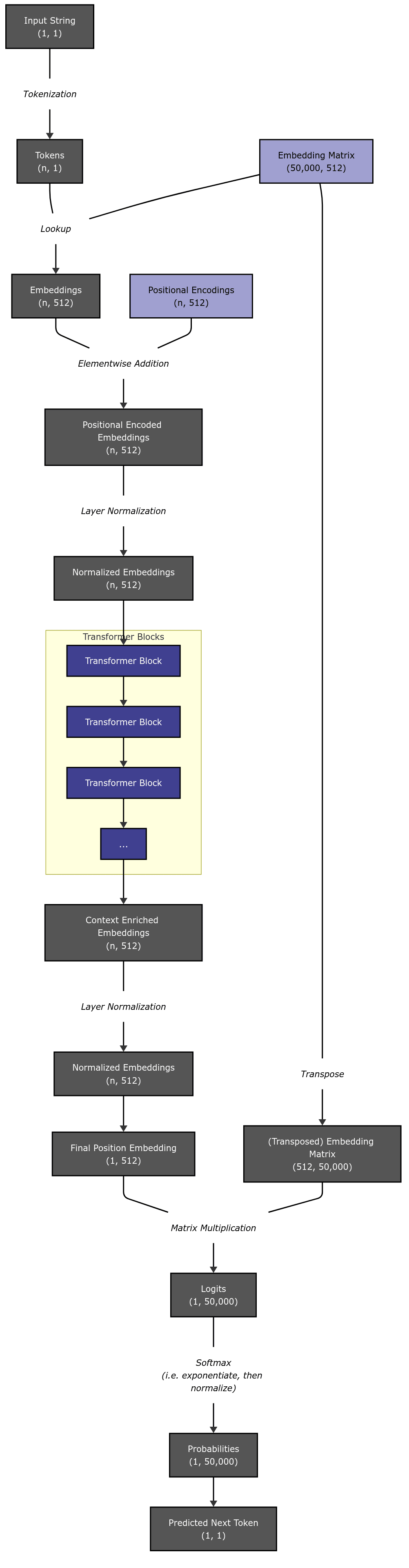
Diagram 2: A Transformer Block
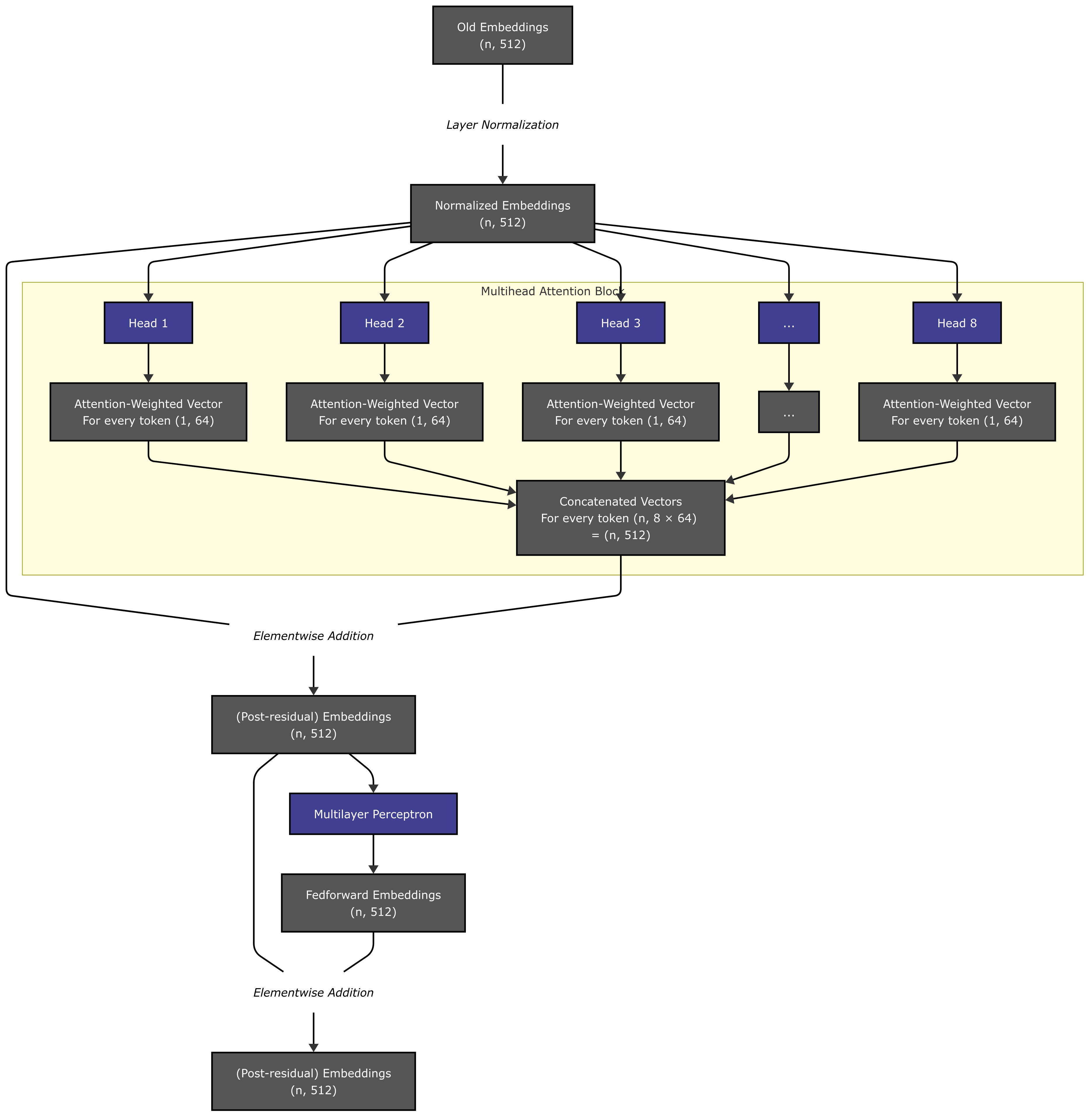
Diagram 3: An Attention Head
Ah, it's mostly your first figure which is counter-intuitive (when one looks at it, one gets the intuition of
f(g(h... (x))), so it de-emphasizes the fact that each of these Transformer Block transformations is shaped likex=x+function(x))