TL;DR: We present a retrieval-augmented LM system that nears the human crowd performance on judgemental forecasting.
Paper: https://arxiv.org/abs/2402.18563 (Danny Halawi*, Fred Zhang*, Chen Yueh-Han*, and Jacob Steinhardt)
Twitter thread: https://twitter.com/JacobSteinhardt/status/1763243868353622089
Abstract
Forecasting future events is important for policy and decision-making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. To facilitate our study, we collect a large dataset of questions from competitive forecasting platforms. Under a test set published after the knowledge cut-offs of our LMs, we evaluate the end-to-end performance of our system against the aggregates of human forecasts. On average, the system nears the crowd aggregate of competitive forecasters and in some settings, surpasses it. Our work suggests that using LMs to forecast the future could provide accurate predictions at scale and help inform institutional decision-making.
For safety motivations on automated forecasting, see Unsolved Problems in ML Safety (2021) for discussions. In the following, we summarize our main research findings.
Current LMs are not naturally good at forecasting
First, we find that LMs are not naturally good at forecasting when evaluated zero-shot (with no fine-tuning and no retrieval). On 914 test questions that were opened after June 1, 2023 (post the knowledge cut-offs of these models), most LMs get near chance performance.
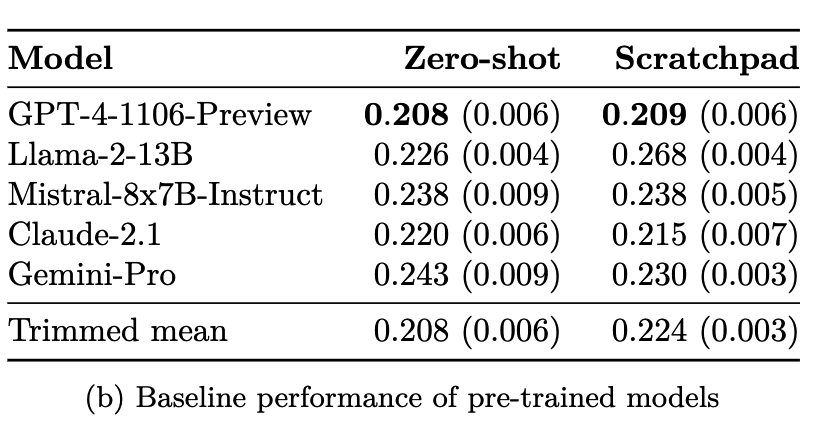
Here, all questions are binary, so random guessing gives a Brier score of 0.25. Averaging across all community predictions over time, the human crowd gets 0.149. We present the score of the best model of each series. Only GPT-4 and Claude-2 series beat random guessing (by a margin of >0.3), though still very far from human aggregates.
System building
Towards better automated forecasting, we build and optimize a retrieval-augmented LM pipeline for this task.
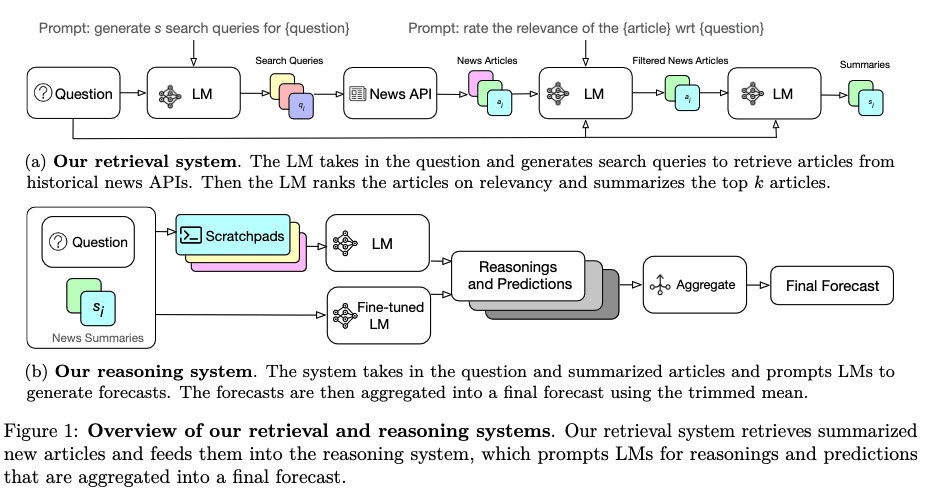
It functions in 3 steps, mimicking the traditional forecasting procedure:
- Retrieval, which gathers relevant information from news sources. Here, we use LM to generate search queries given a question, use these queries to query a news corpus for articles, filter out irrelevant articles, and summarize the remaining.
- Reasoning, which weighs available data and makes a forecast. Here, we prompt base and fine-tuned GPT-4 models to generate forecasts and (verbal) reasonings.
- Aggregation, which ensembles individual forecasts into an aggregated prediction. We use trimmed mean to aggregate all the predictions.
We optimize the system’s hyperparameters and apply a self-supervised approach to fine-tune a base GPT-4 to obtain the fine-tuned LM. See Section 5 of the full paper for details.
Data and models
We use GPT-4-1106 and GPT-3.5 in our system, whose knowledge cut-offs are in April 2023 and September 2021.
To optimize and evaluate the system, we collect a dataset of forecasting questions from 5 competitive forecasting platforms, including Metaculus, Good Judgment Open, INFER, Polymarket, and Manifold.
- The test set consists only of questions published after June 1st, 2023. Crucially, this is after the knowledge cut-off date of GPT-4 and GPT-3.5, preventing leakage from pre-training.
- The train and validation set contains questions before June 1st, 2023, used for hyperparameter search and fine-tuning a GPT-4 base model.
Evaluation results
For each question, we perform information retrieval at up to 5 different dates during the question’s time span and evaluate our system against community aggregates at each date. (This simulates “forecasting” on past, resolved questions with pre-trained models, a methodology first introduced by Zou et al, 2022.)
Unconditional setting
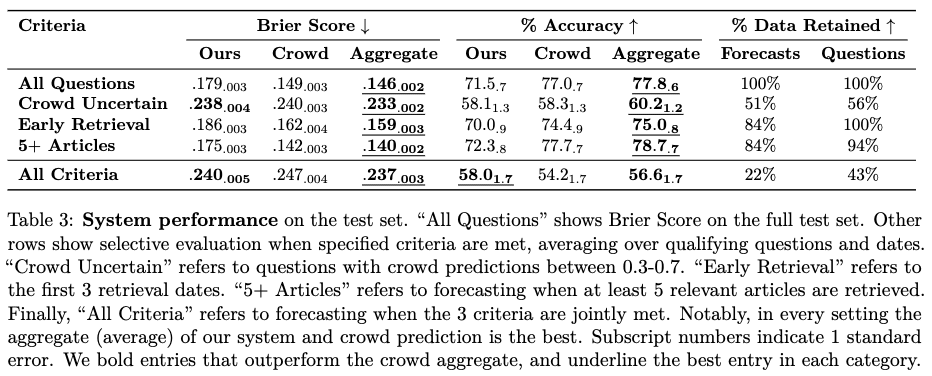
Averaging over a test set of 914 questions and all retrieval points, our system gets an average Brier score of 0.179 vs. crowd 0.149 and an accuracy of 71.5% vs the crowd 77.0%. This significantly improves upon the baseline evaluation we had earlier.
Selective setting
Through a study on the validation set, we find that our system performs best relative to the crowd along several axes, which hold on the test set:
- On questions when the crowd prediction falls between .3 and .7 (i.e., when humans are quite uncertain), it gets a Brier score of .238 (crowd aggregate: .240).
- On the earlier retrieval dates (1, 2, and 3), it gets a Brier score of .185 (crowd aggregate: .161).
- When the retrieval system provides at least 5 relevant articles, it gets a Brier score of .175 (crowd aggregate: .143).
- Under all three conditions, our system attains a Brier score of .240 (crowd aggregate: .247).
In both 1 and 4, our system actually beats the human crowd.
More interestingly, by taking a (weighted) average of our system and the crowd’s prediction, we always get better scores than both of them, even unconditionally! Conceptually, this shows that our system can be used to complement the human forecasters.
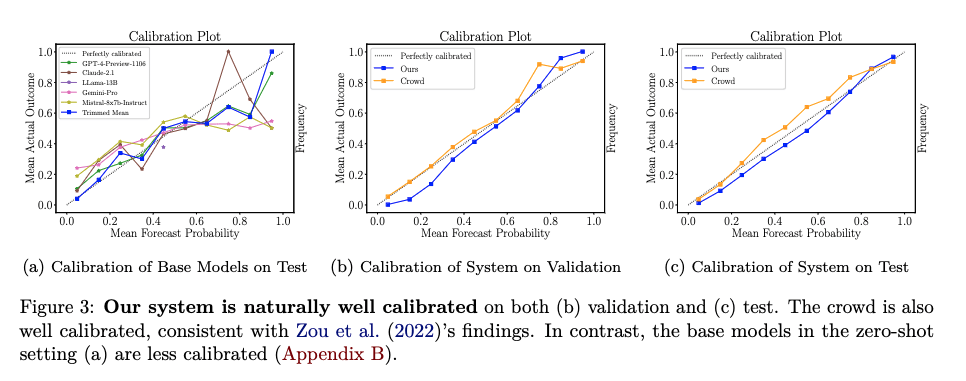
Calibration
Finally, we compare our system's calibration against the human crowd. On the test set (figure (c) below), our system is nearly as well calibrated, with RMS calibration error .42 (human crowd: .38).
Interestingly, this is not the case in the baseline evaluation, where the base models are not well calibrated under the zero-shot setting (figure (a) below). Our system, through fine-tuning and ensembling, improves the calibration of the base models, without undergoing specific training for calibration.
Future work
Our results suggest that in the near future, LM-based systems may be able to generate accurate forecasts at the level of competitive human forecasters.
In Section 7 of the paper, we discuss some directions that we find promising towards this goal, including iteratively applying our fine-tuning method, gathering more forecasting data from the wild for better training, and more.
Interesting work, congrats on achieving human-ish performance!
I expect your model would look relatively better under other proper scoring rules. For example, logarithmic scoring would punish the human crowd for giving >1% probabilities to events that even sometimes happen. Under the Brier score, the worst possible score is either a 1 or a 2 depending on how it's formulated (from skimming your paper, it looks like 1 to me). Under a logarithmic score, such forecasts would be severely punished. I don't think this is something you should lead with, since Brier scores are the more common scoring rule in the literature, but it seems like an easy win and would highlight the possible benefits of the model's relatively conservative forecasting.
I'm curious how a more sophisticated human-machine hybrid would perform with these much stronger machine models, I expect quite well. I did some research with human-machine hybrids before and found modest improvements from incorporating machine forecasts (e.g. chapter 5, section 5.2.4 of my dissertation Metacognitively Wise Crowds & the sections "Using machine models for scalable forecasting" and "Aggregate performance" in Hybrid forecasting of geopolitical events.), but the machine models we were using were very weak on their own (depending on how I analyzed things, they were outperformed by guessing). In "System Complements the Crowd", you aggregate a linear average of the full aggregate of the crowd and the machine model, but we found that treating the machine as an exceptionally skilled forecaster resulted in the best performance of the overall system. As a result of this method, the machine forecast would be down-weighted in the aggregate as more humans forecasted on the question, which we found helped performance. You would need access to the individuated data of the forecasting platform to do this, however.
If you're looking for additional useful plots, you could look at Human Forecast (probability) vs AI Forecast (probability) on a question-by-question basis and get a sense of how the humans and AI agree and disagree. For example, is the better performance of the LM forecasts due to disagreeing about direction, or mostly due to marginally better calibration? This would be harder to plot for multinomial questions, although there you could plot the probability assigned to the correct response option as long as the question isn't ordinal.
I see that you only answered Binary questions and that you split multinomial questions. How did you do this? I suspect you did this by rephrasing questions of the form "What will $person do on $date, A, B, C, D, E, or F?" into "Will $person do A on $date?", "Will $person do B on $date?", and so on. This will result in a lot of very low probability forecasts, since it's likely that only A or B occurs, especially closer to the resolution date. Also, does your system obey the Law of total probability (i.e. does it assign exactly 100% probability to the union of A, B, C, D, E, and F)? This might be a way to improve performance of the system and coax your model into giving extreme forecasts that are grounded in reality (simply normalizing across the different splits of the multinomial question here would probably work pretty well).
Why do human and LM forecasts differ? You plot calibration, and the human and LM forecasts are both well calibrated for the most part, but with your focus on system performance I'm left wondering what caused the human and LM forecasts to differ in accuracy. You claim that it's because of a lack of extremization on the part of the LM forecast (i.e. that it gives too many 30-70% forecasts, while humans give more extreme forecasts), but is that an issue of calibration? You seemed to say that it isn't, but then the problem isn't that the model is outputting the wrong forecast given what it knows (i.e. that it "hedge[s] predictions due to its safety training"), but rather that it is giving its best account of the probability given what it knows. The problem with e.g. the McCarthy question (example output #1) seems to me that the system does not understand the passage of time, and so it has no sense that because it has information from November 30th and it's being asked a question about what happens on November 30th, it can answer with confidence. This is a failure in reasoning, not calibration, IMO. It's possible I'm misunderstanding what cutoff is being used for example output #1.
Miscellaneous question: In equation 1, is k 0-indexed or 1-indexed?
We will be updating the paper with log scores.
I think human forecasters collaborating with their AI counterparts (in an assistance / debate setup) is a super interesting future direction. I imagine the strongest possible system we can build today will be of this sort. This related work explored this direction with some positive results.
Definitely both. But more coming from the fact that the models don't like to say extreme ... (read more)