TL;DR: If you are thinking of using interpretability to help with strategic deception, then there's likely a problem you need to solve first: how are intentional descriptions (like deception) related to algorithmic ones (like understanding the mechanisms models use)? We discuss this problem and try to outline some constructive directions.
1. Introduction
A commonly discussed AI risk scenario is strategic deception: systems that execute sophisticated planning against their creators to achieve undesired ends. In particular, this is insidious because a system that is capable of strategic planning and also situationally aware might be able to systematically behave differently when under observation, and thus evaluation methods that are purely behavioral could become unreliable. One widely hypothesized potential solution to this is to use interpretability, understanding the internals of the model, to detect such strategic deception. We aim to examine this program and a series of problems that appear on its way. We are primarily concerned with the following:
- Strategic deception is an intentional description or an intentional state. By intentional state, we mean that it involves taking the intentional stance towards a system and attributing mental properties, like beliefs and desires, to it; for example, believing that it is raining is an intentional state, while being wet is not.[1] In contrast to this, current interpretability has focused on the algorithmic description of behaviors. The safety-relevant properties to detect would largely appear as strategic intentional states about potentially deceptive actions.[2]We argue that intentional states are an importantly different level of description from algorithmic states, and it is not clear how to describe the former in terms of the latter. We think that studying the connection between algorithmic description and intentional states has been underexplored, but it is likely an important prerequisite to building a deception detector.
- The different possible relationships between the levels of intentional and algorithmic states. A particularly convenient one is a “simple correspondence”, where one algorithmic variable corresponds directly to an intentional state. We outline some alternative possibilities, which may make the job of designing a deception detector harder.
- Future work directions that consider a breakdown of strategic deception at the intentional level into simpler states and might be more amenable to a mechanistic approach.
2. The intentional and the algorithmic
If you study and work with LLMs, it’s very likely that you’ve said or have heard other people saying something along the lines of “the model believes, understands, desires, [insert intentional verb] X”. This is an intentional state description that presupposes the application of the intentional stance to LLMs: that is, treating them as agents to whom it makes sense to attribute mental states like beliefs and desires, at least as a predictive shorthand.[3] The intentional stance is useful for modeling the states of other agents: to the extent that LLMs engage in human tasks through their advanced linguistic capabilities, thinking in terms of intentional states is similarly appealing (see more in The Intentional Stance, LLMs Edition). Behavioral analyses that feature this terminology, attributing states like beliefs and desires to a system, are at the intentional level.
At the same time, the study of LLM brains, and especially, mechanistic interpretability, seeks to discover how a model executes a given task. This is the algorithmic level: it describes the algorithmic details of how a system works (Marr, 1982). In the case of LLMs, that includes anything that concerns how the system is implemented (for example, findings both from reverse engineering and SAEs). The task to be described may well be an intentional level description. For example, we might consider that the goal of a particular sub-system is detecting objects of a certain kind, then want to understand the algorithms that implement this functionality. Recently, the focus of mechanistic interpretability work has shifted to thinking about "representations", rather than strictly about entire algorithms. It's not entirely clear how to think about a (hypothesized?) representational structure like the "Golden Gate Bridge" feature in these terms, but we think it should primarily be thought of as algorithmic; such concrete structures are surely part of a "how" story.
The distinction between the two levels provides a useful set of abstractions for classifying different kinds of descriptions and explanations for a given system. A third level concerns the hardware implementation and focuses on the physical components required for the realization of the task in question.
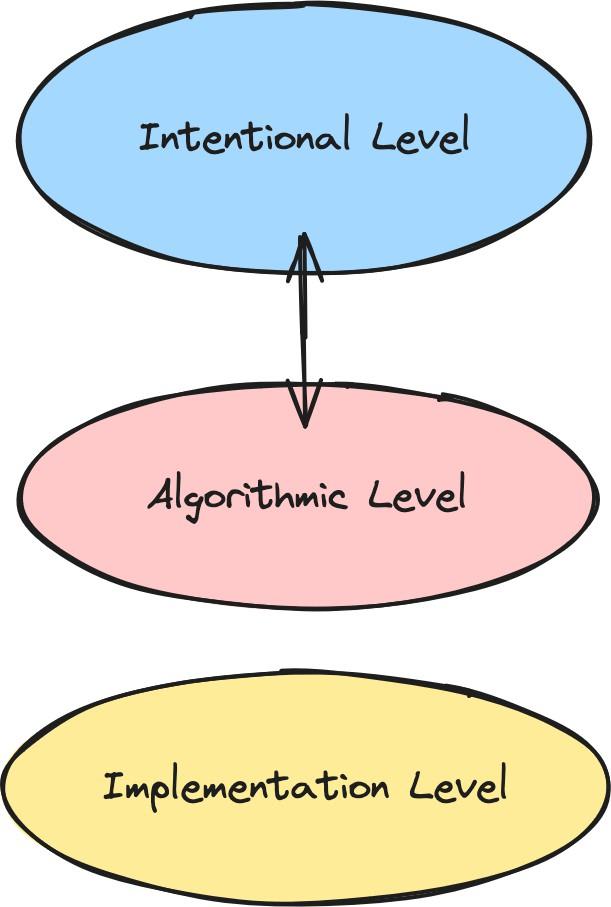
One success story for building a “deception detector” would be the following: if we understand the algorithmic operations of the neural network in sufficient detail, we will be able to detect safety-relevant intentional states, such as strategic deception. A deception detector would then be able to tell us whether a system is strategically deceptive at the behavioral level by picking out the some aspect of the implementation of strategic deception at the algorithmic level.
This idea underlies approaches that try to reverse engineer a network’s algorithms, such as (Olah, 2023), as well as more recent attempts to find monosemantic features using sparse autoencoders, for example, (Templeton, 2024). The reverse engineering process translates into a search for circuits that are responsible for specific functions, a connection between the algorithmic level (circuits) and the intentional (cognitive functions). Researchers suppose that “the network believes X” and when the circuit is deleted, the model no longer knows anything about X. Similarly, work with sparse autoencoders relies on the idea of discovering a correspondence between concepts in the world, and linear features in the neural network (Elhage et al., 2022).
3. What is the problem?
Understanding the connection between the two levels is a significant open problem, even assuming a generous amount of progress on interpretability. We expect that we would still not be able to build a reliable deception detector even if we had a lot more interpretability results available. The research approach in interpretability has generally been to work almost exclusively on expanding the domain of algorithmic interpretability, without directly engaging with the issue of whether this applies to the problem of identifying the intentional states of a model. In our case, that is to be able to tell whether a system is strategically deceiving the user.
One potential way for the two levels to be related is via a simple correspondence: there could be an algorithmic variable that corresponds to the intentional state. An example of this would be models that have a “refusal direction” which reliably triggers the model to refuse to answer a query. An intentional description - the model has decided to refuse - can then be replaced with an algorithmic read of that particular variable. Additionally, this idea of a simple correspondence seems like an implicit premise of a lot of work on SAEs: the expectation that there will be an explicit linear “feature” (or a set of such features) corresponding to intentional states that the model exhibits (like beliefs or knowledge). It would be serendipitous for the designer of a deception detector if simple correspondence of this form was the only possible way for the algorithmic and intentional descriptions of a system to be related. However, there are other conceivable ways for this correspondence to exist which are at least plausible a priori, and it perhaps seems unlikely that cognitive systems will exploit only simple correspondences.
There isn’t sufficient evidence to suggest that the connection between the two levels can be exclusively studied as a simple correspondence between intentional and algorithmic states. There are a few obvious potential ways for a more complex correspondence between intentional and algorithmic states to occur.
Perhaps there is no algorithmic variable directly corresponding to an intentional state we are interested in, but the intentional state in question is implemented in terms of simpler intentional states, which are in turn further divided until we reach a lower level where the capabilities have simple correspondences. There would then be a potential relationship between an intentional state and a set of underlying algorithmic states, but it could be quite complicated.
Another possibility is redundant or overlapping representations. This could provide insights about the system, e.g., perhaps we discover that a network’s representation of a fact is implemented in three slightly different ways, either in the sense that different algorithms are implemented depending on the phrasing of a question, or in the sense of redundant mechanisms existing that complicate a direct correspondence to a single part of the system
A more difficult possibility is emergence from irreducible complexity. By irreducible complexity, we mean something like Wolfram’s concept of computational irreducibility: there is no good way of predicting the behavior of an irreducible system other than simulating it in detail. Examples of irreducible complexity include turbulent behavior in fluid dynamics, or complex cellular automata like the Game of Life: these systems might just not have a description that is much more compact than the system itself. The irreducibility of a phenomenon doesn’t rule out the possibility that there may be useful higher-level abstractions, like the gliders in the Game of Life, or thermodynamic quantities in statistical mechanics, which are to a certain extent causally insulated from their underlying substrate (see Beckers and Halpern and Rosas et. al. for more discussion). The kind of stable behavior that implements intentional states could then be of this form; like the gliders in the Game of Life, it may emerge from a level of simple underlying algorithmic behavior, but have no direct correspondence to the level below: we might say that such states are represented tacitly. Another example, discussed in 'The strong feature hypothesis might be wrong', is that of a chess-playing machine with a tree search; the fact that the model knows a particular move is better than another is implemented in the algorithmic process of the tree search, but there is no one fact about the algorithm that implements this intentional state that you could read this fact from.
This possibility suggests it might even be a category mistake to be searching for an algorithmic analog of intentional states. This has parallels in studying biological brains and minds. Characteristically, Gilbert Ryle points to a similar possibility in “The Concept of Mind”:
A foreigner visiting Oxford or Cambridge for the first time is shown a number of colleges, libraries, playing fields, museums, scientific departments and administrative offices. He then asks ‘But where is the University?”
Ryle here responds by saying that the University is a matter of organization of all the parts of campus the visitor has already seen rather than one particular entity. It could be similarly mistaken if brain sciences are also looking for a single algorithmic entity corresponding to an intentional phenomenon such as deception.
It could be that some percentage of the system is made out of interpretable algorithms with simple correspondences, and yet the safety-relevant behavior of strategic deception falls into the low percentage that isn’t. These problems essentially imply that if we want a deception detector derived from an understanding of the mechanisms of deception, we have to overcome the difficulties that appear as we move from the intentional to the algorithmic level and back.
4. What deception, exactly?
We’ve already mentioned that by deception we mean strategic deception since we’re interested in models that can plan their deceptive actions (Hobbhahn et al., 2024). Strategic deception requires capabilities that are different from unintentionally being misleading or inaccurate due to hallucinations (Athaluri et al., 2023). Consider, for instance, different definitions of deception that involve models that output incorrect information either because they are not capable enough to do otherwise or because of their fine-tuning. In these cases, e.g., in sycophancy (Sharma et al., 2023), the models are not strategically deceptive. If they were strategically deceptive, they would counterfactually behave differently if the state of affairs in the world were different. However, the purely sycophantic models do not have that degree of flexibility or sensitivity to environmental input.
Our working hypothesis is that strategic deception is a complex intentional state: it consists of different sets of dispositions and intentional objects required for executing the targeted task. It thus likely presupposes a series of cognitive capabilities that make the model sensitive to the states of the world. We seek to understand the most prominent of them. We hope that this is fruitful for interpretability work on deception, under the hypothesis that many or most of these will turn out to have simple or complex correspondences in the sense discussed in the previous section, where it is possible to find algorithmic correspondences to the intentional states of interest.
We haven’t ruled out the possibility of intentional states being represented tacitly in the sense discussed in the previous section. We think that this remains an important possibility, though if it turns out to be the case, it’s not clear to us what our research program should be. To the degree that systems depend on such irreducible processes, it may be difficult, or even impossible, to make concise generalizations about their behavior. We have focused on decomposing deception into sub-capabilities which can each be examined in isolation as an empirical roadmap, though we think that the problem of dealing with tacit representation deserves considerably more attention in interpretability.
5. Decomposing strategic deception
How can we go from strategic deception as a complex intentional state to many simple ones that we could separately study at the algorithmic level? Our answer is to think about the capabilities likely necessary for strategic deception. These are potentially also complex intentional states calling for further analysis. However, they’re likely already present in LLMs at least to some degree which allows for experimentation and testing (He et al., 2024; Vilas et al., 2024).
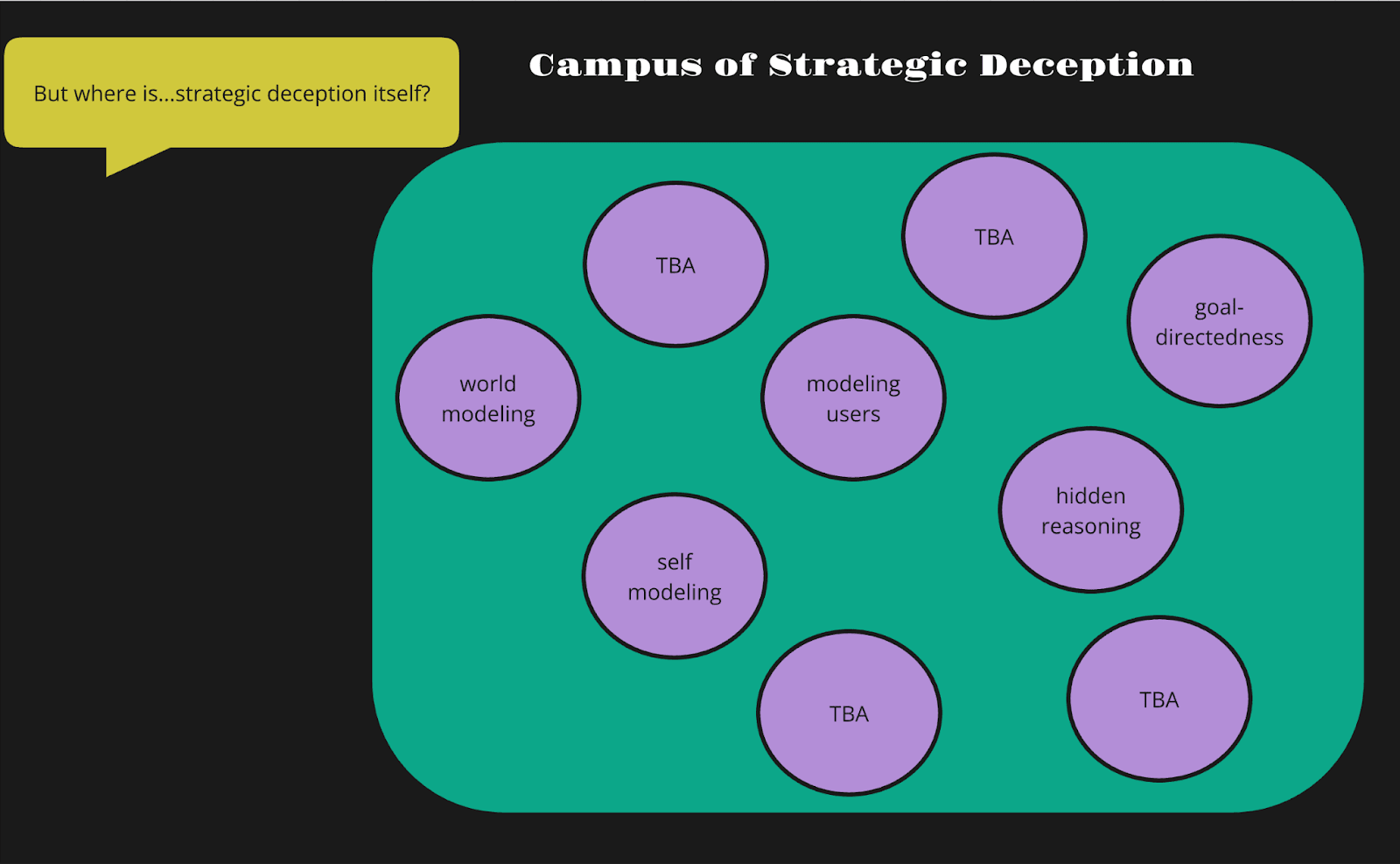
5.1. Developing world models
World models are the center of debate in LLM research and there are likely many plausible interpretations of the formal definition for what a world model is. Without going too deep into this debate, we think that the following observation is highly relevant for studying strategic deception. Strategic deceptiveness implies a causal dependence on the model's own beliefs about what other agents think and what they will think in response to the agent's actions: this requires at least some capacity for a theory of mind (Strachan et al., 2023).
A world model can be defined as a more or less granular internal representation of the agent’s environment (including itself within it). Notice that the LLM does not need to have the most accurate model to exhibit capabilities related to prediction. An example of this appears in Alignment Faking, where the model makes a false prediction about a future state of affairs following its own action (Greenblatt et al., 2024). Strategic deception relies on having a world model, even if it’s not the correct one, because it reveals that the system has a capability for acting conditional on its prediction of future behaviors, however inaccurate they might be. A model that always engages in “deceptive” behavior regardless of the environment and its beliefs (if any) about other agents, is not by default trategically deceptive, e.g., a model that has been trained to always say that the sky is green is not deceptive.
5.2. Modeling the self
This capability concerns models that understand what they are, what they do, and how they were trained. It seems that LLMs are also able to self-evaluate or to “know what they know” (Kadavath et al., 2022). It’s especially relevant for alignment to test whether a model is situationally aware: if the model can tell what phase it is in, namely, training, testing, or deployment (Berglund et al., 2023; Ngo et al., 2023).
So far, research on the ability of LLMs to model themselves is focused on behavioral evaluations. For example, testing models with self-report questions to inquire about their internal states (Perez & Long, 2023) or inducing models into introspective states (Binder et al., 2024). LLMs have been found to exhibit some degree of metacognitive abilities when they’re thinking about thinking (Didolkar et al., 2024). All these tests give us a sense of what self-modeling looks like in these systems.
5.3. Modeling user states
Model evaluations results show that state-of-the-art LLMs can infer and predict the preferences of the user (Staab et al., 2023) as well as personal data details including a user's age, gender, educational level, and socioeconomic status (Chen et al., 2024). They are essentially capable enough to apply the intentional stance to a human. This is advantageous for the same reasons it has historically been a useful heuristic in interpersonal interactions among humans. Conversely, the better a system becomes at modeling other agents, the better it models itself.
From the safety perspective, models could use it to be better sycophants or schemers: manipulate humans into serving their goals, take advantage of their weaknesses or lack of information, and make them take actions they would not endorse at a reflective level (Bostrom, 2016; Carlsmith, 2023).
5.4. Long-term goal directedness
The pursuit of a goal in the long term requires all of the above capabilities. The most obvious way to do this requires the equivalent of episodic memory which would allow the system to model itself as a coherent entity with continuity and hence projecting a certain goal in future states. Alternatively, it might be possible for a goal-directed system to reason about the behavior of future copies of itself and similar systems.
The memory requirement is empirically not sufficient for strategically deceptive behavior; it seems nevertheless important to note that memory impacts a model’s perception of itself and its environment. Carlsmith flags this as relevant for understanding “model time” (Carlsmith, 2023, p. 52) which presumably largely affects the degree to which a model could be engaging in deceptive behavior. In cases where “model time” and “calendar time” are not in sync, the model could exhibit background activity and develop goals independent of the task assigned by the user.
5.5. Hidden reasoning
Hidden reasoning, while not sufficient on its own, is another requirement for successful deceptive alignment, at least assuming that the model operator implements some sort of monitoring of a visible chain-of-thought that would catch deceptive reasoning that takes place "in plain sight".[4] It is typically understood as the kind of reasoning the model manages to hide from the overseer. Models can accomplish that through different pathways. For example, there are cases of LLM encrypting information using steganography techniques (Roger & Greenblatt, 2023).
LLMs are often tested and told that they can use a scratchpad to note their thoughts since they produce a legible chain of thought. In these tests, they are also told that the overseers won’t be accessing that information. One speculation is that as models become more capable, they won’t trust the word of their overseers and will likely not reveal important information through this method. It’s notable that Greenblatt et. al’s experiments with alignment faking demonstrated that the model was apparently able to pursue the alignment faking strategy without verbalizing it on occasion.
For the time being, models that can hide their thoughts are not necessarily strategically deceptive, although it is reasonable to wonder about what prompts the hiding to begin with. Moreover, strategic deception doesn’t have to entail a step where the system reflects on its goals and hides its reflections (Carlsmith, 2023). However, having this feature is instrumentally useful for strategic planning and certainly creates an additional barrier in examining how models are planning in general.
6. Conclusions and Suggestions
With the decomposition approach in mind, we expect that the following are useful in further clarifying the intentional-algorithmic relationship that underlies building a deception detector:
- The uncertainty over the intentional-algorithmic relationship has been overlooked and without resolving it, we (probably) won’t be able to build a reliable deception detector via increased algorithmic understanding.
- What experiments should be designed to determine whether deception or its identified sub-components have simple correspondences? What alternatives are there if we find evidence suggesting tacit representations? What evidence would suggest tacit representations/irreducibility?
- What do we do if the breakdown approach doesn’t work? We think that this is a serious possibility if some important sub-capabilities of deception have tacit or irreducible representations, which seems quite plausible. But we can hope some components are reducible/understandable, even if the entire thing isn’t in important respects; presumably, there must be some kind of structure underlying regularities in behavior.
- One potential approach for irreducibility might be to rely on more "black box" methods for components which we suspect we will be unable to understand in sufficient detail. This has the advantage that the sub-capabilities are more likely to occur enough to be able to take an empirical approach to identifying them from model internals (such as building a black box classifier for when a sub-capability is being engaged), without necessarily requiring a full understanding of the mechanisms involved. That is, we may not be able to rely on waiting for occurrences of scheming (since this is already quite bad), and then build a classifier based on model internals in these situations, but this approach is likely possible to work for the sub-capabilities we described in section 5.
Acknowledgments
We'd like to thank Senthooran Rajamanoharan, Neel Nanda, Arthur Conmy, Tom Everitt, Samuel Albanie and Aysja Johnson for their feedback. This work was done as part of the Future Impact Group Fellowship.
References
Athaluri, S. A., Manthena, S. V., Kesapragada, V. K. M., Yarlagadda, V., Dave, T., & Duddumpudi, R. T. S. (2023). Exploring the boundaries of reality: Investigating the phenomenon of artificial intelligence hallucination in scientific writing through ChatGPT references. Cureus, 15 (4)
Beckers, S., & Halpern, J. Y. (2019, July). Abstracting causal models. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01, pp. 2678-2685).
Berglund, L., Stickland, A. C., Balesni, M., Kaufmann, M., Tong, M., Korbak, T., Kokotajlo, D., & Evans, O. (2023). Taken out of context: On measuring situational awareness in LLMs. arXiv preprint arXiv:2309.00667.
Binder, F. J., Chua, J., Korbak, T., Sleight, H., Hughes, J., Long, R., Perez, E., Turpin, M., & Evans, O. (2024). Looking Inward: Language Models Can Learn About Themselves by Introspection. arXiv preprint arXiv:2410.13787.
Bostrom, N. (2016, May). Superintelligence: Paths, Dangers, Strategies (Reprint edition). Oxford University Press.
Carlsmith, J. (2023). Scheming AIs: Will AIs fake alignment during training in order to get power? arXiv preprint arXiv:2311.08379.
Dennett, D. C. (1989, March). The Intentional Stance (Reprint edition). A Bradford Book.
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., & Chen, C. (2022). Toy models of superposition. arXiv preprint arXiv:2209.10652.
Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., & Duvenaud, D. (2024). Alignment faking in large language models. arXiv preprint arXiv:2412.14093.
Hobbhahn, M., Balesni, M., Scheurer, J., & Braun, D. (2024). Understanding strategic deception and deceptive alignment.
Hubinger, E., van Merwijk, C., Mikulik, V., Skalse, J., & Garrabrant, S. (2021, December). Risks from Learned Optimization in Advanced Machine Learning Systems. https://doi.org/10.48550/arXiv.1906.01820
Marr, D. (1982). Vision: A computational investigation into the human representation and processing of visual information. W. H. Freeman and Company.
Ngo, R., Chan, L., & Mindermann, S. (2023). The Alignment Problem from a Deep Learning Perspective: A Position Paper. The Twelfth International Conference on Learning Representations.
Olah, C. (2023). Interpretability dreams. Transformer Circuits Thread, Anthropic.
Olah, C., Cammarata, N., Schubert, L., Goh, G., Petrov, M., & Carter, S. (2020). Zoom in: An introduction to circuits. Distill, 5 (3), e00024– 001.
Pacchiardi, L., Chan, A. J., Mindermann, S., Moscovitz, I., Pan, A. Y., Gal, Y., ... & Brauner, J. (2023). How to catch an AI liar: Lie detection in black-box LLMs by asking unrelated questions. arXiv preprint arXiv:2309.15840.
Perez, E., & Long, R. (2023). Towards Evaluating AI Systems for Moral Status Using Self-Reports. arXiv preprint arXiv:2311.08576.
Premakumar, V. N., Vaiana, M., Pop, F., Rosenblatt, J., de Lucena, D. S., Ziman, K., & Graziano, M. S. (2024). Unexpected Benefits of Self-Modeling in Neural Systems. arXiv preprint arXiv:2407.10188.
Roger, F., & Greenblatt, R. (2023). Preventing Language Models From Hiding Their Reasoning. arXiv preprint arXiv:2310.18512.
Rosas, F. E., Geiger, B. C., Luppi, A. I., Seth, A. K., Polani, D., Gastpar, M., & Mediano, P. A. (2024). Software in the natural world: A computational approach to emergence in complex multi-level systems. arXiv preprint arXiv:2402.09090.
Russell, S. (2019, October). Human Compatible: Artificial Intelligence and the Problem of Control. Penguin Books.
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman,
S. R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., & Johnston, S. R. (2023). Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.1354
- ^
To expand on this a little: strategic deception is an intentional state because it requires the agent to have a belief about the consequences of its actions, as well as a belief about the mental states of other agents, such that your actions are conditioned on these beliefs (for instance, believing that you can get away with stealing if no-one is watching, but avoiding attempts if you are under observation). We don’t think it’s possible to formulate a definition of strategic deceptive behavior that avoids taking the intentional stance, though there are some things which might broadly be classed as deception that might not require this (like an animal which has evolved a form of camouflage).
- ^
An important alternative would be detecting deception post-hoc, or in situations where you can re-run the interaction multiple times. This may well be a lot easier, but is probably less relevant for really critical cases. There are also examples where follow-up questions or re-running the behavour multiple times may give you a signal: Pacchiardi et. al. for an example of this kind of method. We do not consider this here, but investigating such methods is obviously an important alternative to a fully mechanistic approach.
- ^
Obviously the extent to which LLMs, AIs more broadly, computer programs, or even animals or people may be said to "really" have mental states like beliefs, or the nature of being in such a state, is a matter of philosophical contention. We don’t think that it’s particularly important for the argument we make here to come to a firm conclusion on these questions, merely to note that, whatever the nature of such mental states, it makes pragmatic sense to attribute them to sufficiently complex systems. Dennett gives the example of Martians invading earth; whatever the internals of the Martians are like, it would seem that, given that they were complex enough to make it to Earth and start invading, the case for modelling them as intentional agents seems overwhelming, even if we know very little about the makeup of the Martians. We also note that, pragmatically, the intentional stance is frequently useful for predicting what LLMs will do; we might consider, given a particular prompt, what an LLMs "knows" and what it will "want" to do, given some information, and these predictions are frequently correct.
We also think that this is the sense in which we care about strategic deception as a risk case; by scheming, we are pointing at the kind of pattern of behavior that an intentional agent might execute. Whether the systems "really" intended to be deceptive in some other sense is not particularly important. - ^
It's not clear that we can rely on this happening in practice, but we don't consider such policy discussions here. Preventing scheming in systems which reason in legible English doesn't require addressing detecting deception "internally" in the manner addressed in this analysis, as monitoring human-legible transcripts seems straightforwardly tractable with current technologies.
Can you clarify what you mean by 'neural analog' / 'single neural analog'? Is that meant as another term for what the post calls 'simple correspondences'?
Agreed. I'm hopeful that perhaps mech interp will continue to improve and be automated fast enough for that to work, but I'm skeptical that that'll happen. Or alternately I'm hopeful that we turn out to be in an easy-mode world where there is something like a single 'deception' direction that we can monitor, and that'll at least buy us significant time before it stops working on more sophisticated systems (plausibly due to optimization pressure / selection pressure if nothing else).
I agree that that's a real risk; it makes me think of Andreessen Horowitz and others claiming in an open letter that interpretability had basically been solved and so AI regulation isn't necessary. On the other hand, it seems better to state our best understanding plainly, even if others will slippery-slope it, than to take the epistemic hit of shifting our language in the other direction to compensate.