One of the main obstacles to building safe and aligned AI is that we don't know how to store human values on a computer.
Why is that?
Human values are abstract feelings and intuitions that can be described with words.
For example:
- Freedom or Liberty
- Happiness or Welfare
- Justice
- Individual Sovereignty
- Truth
- Physical Health & Mental Health
- Prosperity & Wealth
We see that AI systems like GPT-3 or other NLP based systems use Word2Vec or other node networks / knowledge graphs to encode words and their meanings as complex relationships. This then allows software developers to parameterize language so that a computer can do Math with it, and transform complicated formulas into a human readable output. Here's a great video on how computers understand language using Word2Vec . Besides that, ConceptNet another great example of a linguistic knowledge graph.
So, what we have to do is find a knowledge graph that helps us encode human values, so that computers can better understand human values and learn to operate within those parameters, not outside of them.
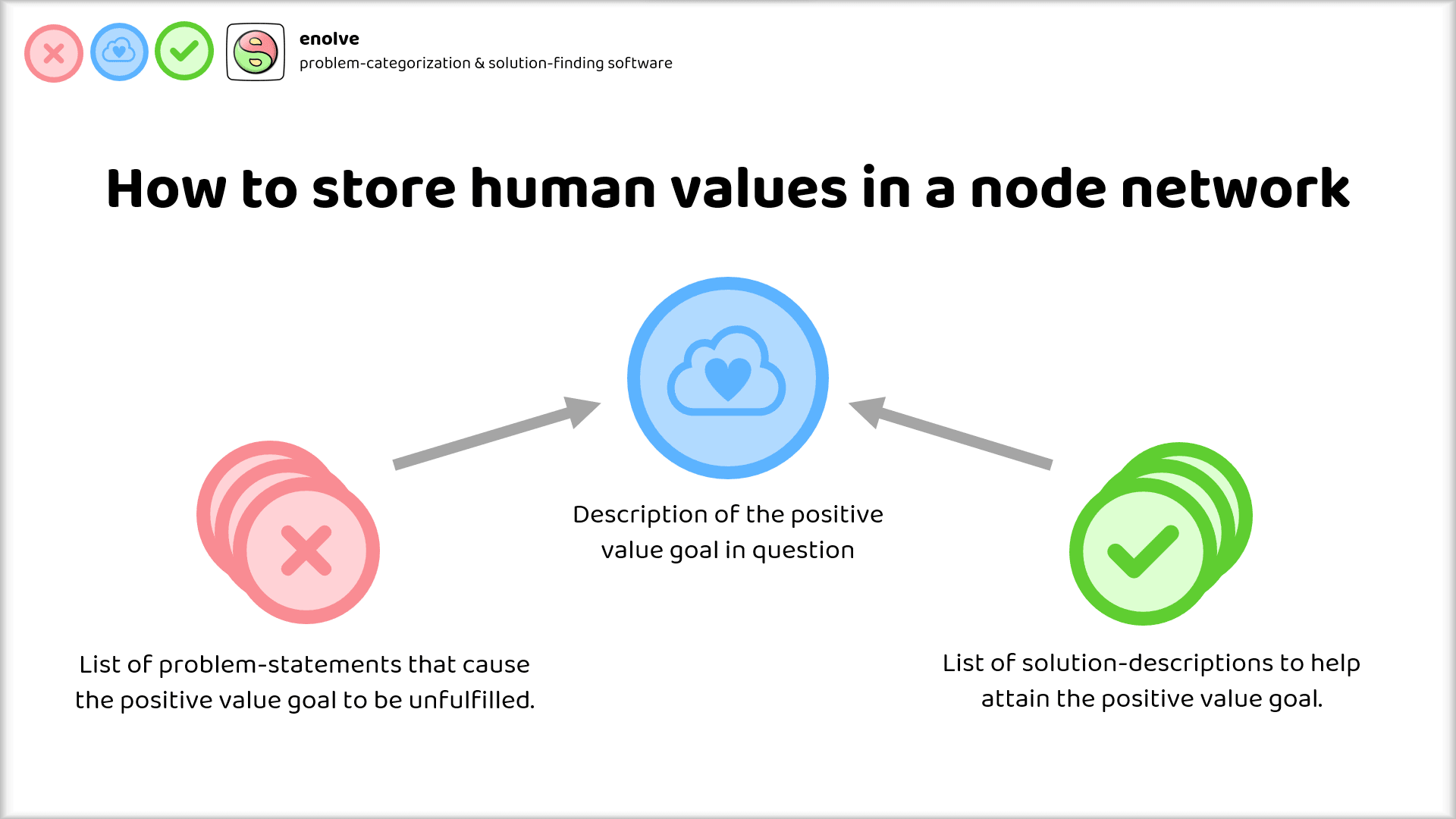
My suggestion for how to do this is quite simple: Categorize each "positive value goal" according to the actionable, tangible methods and systems that help fulfill this positive value goal, and then contrast that with all the negative problems that exist in the world with respect to that positive value goal.
Using the language of the instrumental convergence thesis:
Instrumental goals are the tangible, actionable methods and systems (also called solutions) that help to fulfill terminal goals.
Problems on the other hand are descriptions of how terminal goals are violated or unfulfilled.
There can be many solutions associated to each positive value goal, as well as multiple problems.
Such a system lays the foundation for a node network or knowledge graph of our human ideals and what we consider "good".
Would it be a problem if AI was instrumentally convergent on doing the most good and solving the most problems? That's something I've put up for discussion here and I'd be curious to hear your opinion in the comments!
Fair point! But how do you know that this ungrounded mysticism doesn't apply to current debate about the potential capabilities of AI systems?
Why is an AI suddenly able to figure out how to break the laws of physics and be super intelligent about how to end intelligent life, but somehow incapable of comprehending the human laws of ethics and morality, and valuing life as we know it?
What makes the laws of physics easier to understand and easier to circumvent than the human laws of ethics and morality? (And also, navigating the human laws of ethics and morality must be required for ending all life. Unless software suddenly has the same energy as enriched plutonium or something like that, and one wrong bit flip causes an explosive chain reaction)
What makes it so much more difficult to understand critical thinking and "how to store human values in a computer", and in contrast what makes "accidentally ending all intelligent life" so easy, by comparison?
It seems to me that "ASI on mission to destroy the humans" is the same thing as "luminiferous aether".
We taught AI English and how to draw pictures and create art. Both pretty "fuzzy" things.
How hard can it be to train AI on a dataset of 90% of known human values and 90% of known problems and solutions with respect to those values for a neural net to have an "above average human"-grasp on the idea that "ending all intelligent life" computes as "that's a problem and it's immoral" ?
Beyond that, alignment is unsolvable anyways for AGI systems that perform at above human intelligence. Can't predict the future with a software, because there could always be software that uses the future predicting software and negates the output - aka the Halting Problem. Can't do anything about that.