Why this isn't necessarily true:
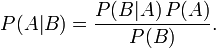
If we look at Bayes' theorem (that picture above, with P(A|B) pronounced "probability of A if we learn B"), our probability of A after getting evidence B is equal to P(A) before you saw the evidence (the "prior probability"), times a factor P(B|A)/P(B).
This factor is called the "likelihood ratio," and it tells you how much impact the evidence should have on your probability - what it means is that the more unexpected the evidence would be if A wasn't true, the more the evidence supports A. Like how UFO abduction stories aren't very convincing, because we'd expect them to happen even if there weren't any aliens (so P(B|A)/P(B) is close to 1, so multiplying by that factor doesn't change our belief).
Anyhow, because Bayes' theorem can be split up into parts like this, research papers don't have to rely on priors! Each paper could just gather some evidence, and then report the likelihood ratio - P(evidence | hypothesis)/P(evidence). Then people with different priors would just multiply their prior, P(A), by the likelihood ratio, and that would be Bayes' theorem, so they would each get P(A|B). And if you want to gather evidence from multiple papers, you can just multiply them together.
Although, that's only in a fairy-tale world with e.g. no file-drawer effect. In reality, more care would be necessary - the point is just that differing priors don't halt science.
Anyhow, because Bayes' theorem can be split up into parts like this, research papers don't have to rely on priors! Each paper could just gather some evidence, and then report the likelihood ratio - P(evidence | hypothesis)/P(evidence).
That's not true in general.
http://xkcd.com/1132/
Is this a fair representation of frequentists versus bayesians? I feel like every time the topic comes up, 'Bayesian statistics' is an applause light for me, and I'm not sure why I'm supposed to be applauding.