"Blinding Us to the Obvious? The Effect of Statistical Training on the Evaluation of Evidence", McShane & Gal 2015
Statistical training helps individuals analyze and interpret data. However, the emphasis placed on null hypothesis significance testing in academic training and reporting may lead researchers to interpret evidence dichotomously rather than continuously. Consequently, researchers may either disregard evidence that fails to attain statistical significance or undervalue it relative to evidence that attains statistical significance. Surveys of researchers across a wide variety of fields (including medicine, epidemiology, cognitive science, psychology, business, and economics) show that a substantial majority does indeed do so. This phenomenon is manifest both in researchers’ interpretations of descriptions of evidence and in their likelihood judgments. Dichotomization of evidence is reduced though still present when researchers are asked to make decisions based on the evidence, particularly when the decision outcome is personally consequential. Recommendations are offered.
...Formally defined as the probability of observing data as extreme or more extreme than that actually observed assuming the null hypothesis is true, the p-value has often been misinterpreted as, inter alia, (i) the probability that the null hypothesis is true, (ii) one minus the probability that the alternative hypothesis is true, or (iii) one minus the probability of replication (Bakan 1966, Sawyer and Peter 1983, Cohen 1994, Schmidt 1996, Krantz 1999, Nickerson 2000, Gigerenzer 2004, Kramer and Gigerenzer 20005).
...As an example of how dichotomous thinking manifests itself, consider how Messori et al.(1993) compared their findings with those of Hommes et al. (1992):
The result of our calculation was an odds ratio of 0.61 (95% CI [confidence interval]: 0.298–1.251; p>0.05); this figure differs greatly from the value reported by Hommes and associates (odds ratio: 0.62; 95% CI: 0.39–0.98; p<0.05)...we concluded that subcutaneous heparin is not more effective than intravenous heparin, exactly the opposite to that of Hommes and colleagues.(p. 77)
In other words, Messori et al. (1993) conclude that their findings are “exactly the opposite” of Hommes et al. (1992) because their odds ratio estimate failed to attain statistical significance whereas that of Hommes et al. attained statistical significance. In fact, however, the odds ratio estimates and confidence intervals of Messori et al. and Hommes et al. are highly consistent (for additional discussion of this example and others, see Rothman et al. 1993 and Healy 2006).
Graph of how a p-value crossing a threshold dramatically increases choosing that option, regardless of effect size: http://andrewgelman.com/wp-content/uploads/2016/04/Screen-Shot-2016-04-06-at-3.03.29-PM-1024x587.png
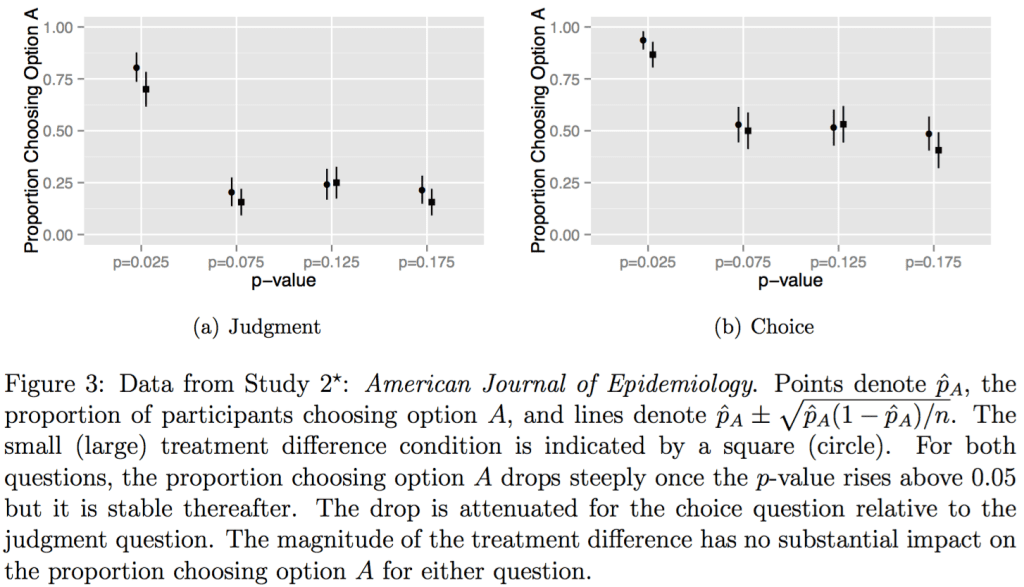
In a forthcoming paper, my colleague David Gal and I survey top academics across a wide variety of fields including the editorial board of Psychological Science and authors of papers published in the New England Journal of Medicine, the American Economic Review, and other top journals. We show:
- Researchers interpret p-values dichotomously (i.e., focus only on whether p is below or above 0.05).
- They fixate on them even when they are irrelevant (e.g., when asked about descriptive statistics).
- These findings apply to likelihood judgments about what might happen to future subjects as well as to choices made based on the data.
We also show they ignore the magnitudes of effect sizes.
{kind=link}
Frequentist statistics is a wide field, but in practice by innumerable psychologists, biologists, economists etc, frequentism tends to be a particular style called “Null Hypothesis Significance Testing” (NHST) descended from R.A. Fisher (as opposed to eg. Neyman-Pearson) which is focused on
NHST became nearly universal between the 1940s & 1960s (see Gigerenzer 2004, pg18), and has been heavily criticized for as long. Frequentists criticize it for:
What’s wrong with NHST? Well, among other things, it does not tell us what we want to know, and we so much want to know what we want to know that, out of desperation, we nevertheless believe that it does! What we want to know is, “Given these data, what is the probability that H0 is true?” But as most of us know, what it tells us is “Given that H0 is true, what is the probability of these (or more extreme) data?” These are not the same…
Similarly, the cargo-culting encourages misuse of two-tailed tests, avoidance of multiple correction, data dredging, and in general, “p-value hacking”.
(An example from my personal experience of the cost of ignoring effect size and confidence intervals: p-values cannot (easily) be used to compile a meta-analysis (pooling of multiple studies); hence, studies often do not include the necessary information about means, standard deviations, or effect sizes & confidence intervals which one could use directly. So authors must be contacted, and they may refuse to provide the information or they may no longer be available; both have happened to me in trying to do my dual n-back & iodine meta-analyses.)
Critics’ explanations for why a flawed paradigm is still so popular focus on the ease of use and its weakness; from Gigerenzer 2004:
Shifts away from NHST have happened in some fields. Medical testing seems to have made such a shift (I suspect due to the rise of meta-analysis):
0.1 Further reading
More on these topics:
The perils of NHST, and the merits of Bayesian data analysis, have been expounded with increasing force in recent years (e.g., W. Edwards, Lindman, & Savage, 1963; Kruschke, 2010b, 2010a, 2011c; Lee & Wagenmakers, 2005; Wagenmakers, 2007).
Although the primary emphasis in psychology is to publish results on the basis of NHST (Cumming et al., 2007; Rosenthal, 1979), the use of NHST has long been controversial. Numerous researchers have argued that reliance on NHST is counterproductive, due in large part because p values fail to convey such useful information as effect size and likelihood of replication (Clark, 1963; Cumming, 2008; Killeen, 2005; Kline, 2009 [Becoming a behavioral science researcher: A guide to producing research that matters]; Rozeboom, 1960). Indeed, some have argued that NHST has severely impeded scientific progress (Cohen, 1994; Schmidt, 1996) and has confused interpretations of clinical trials (Cicchetti et al., 2011; Ocana & Tannock, 2011). Some researchers have stated that it is important to use multiple, converging tests alongside NHST, including effect sizes and confidence intervals (Hubbard & Lindsay, 2008; Schmidt, 1996). Others still have called for NHST to be completely abandoned (e.g., Carver, 1978).
[http://www.gwern.net/DNB%20FAQ#flaws-in-mainstream-science-and-psychology](http://www.gwern.net/DNB%20FAQ#flaws-in-mainstream-science-and-psychology)[https://www.reddit.com/r/DecisionTheory/](https://www.reddit.com/r/DecisionTheory/)