If you have a human-level intelligence which can read super-fast, and you set it free on the internet, it will learn a lot very quickly. (p71)
But why would you have a human-level intelligence which could read super-fast, which hadn't already read most of the internet in the process of becoming an incrementally better stupid intelligence, learning how to read?
Similarly, if your new human-level AI project used very little hardware, then you could buy heaps more cheaply. But it seems somewhat surprising if you weren't already using a lot of hardware, if it is cheap and helpful, and can replace good software to some extent.
I think there was a third example along similar lines, but I forget it.
In general, these sources of low recalcitrance would be huge if you imagine AI appearing fully formed at human-level without having exploited any of them already. But it seems to me that probably getting to human-level intelligence will involve exploiting any source of improvement we get our hands on. I'd be surprised if these ones, which don't seem to require human-level intelligence to exploit, are still sitting untouched.
It may also be worth noting that there's no particular reason to expect a full blown AI that wants to do real world things to be also the first good algorithmic optimizer (or hardware optimizer), for example. The first good algorithmic optimizer can be run on it's own source, performing an entirely abstract task, without having to do the calculations relating to it's hardware basis, the real world, and so on, which are an enormous extra hurdle.
It seems to me that the issue is that the only way some people can imagine this 'explosion' to happen is by imagining fairly anthropomorphic software which performs a task monstrously more complicated than mere algorithmic optimization "explosion" (in the sense that algorithms are replaced with their theoretically ideal counterparts, or something close. For every task there's an optimum algorithm for doing it, and you can't do better than this algorithm).
Super-fast reading aquires crystalline intelligence in a theoretical domain. Any educator knows that the real learning effect comes from practical experience including set-backs and reflection about upcoming problems using the theoretical knowledge.
If a sub HLMI assists in designing an improved hardware design the resulting new AI is not fully capable in an instant. Humans need 16 years to develop their full fluid intelligence. To build up crystalline intelligence to become head hardware architect needs 20 more years. A genius like Wozniak reached this level in a world of low IT complexity at the age of 24. For today's complexity this would not suffice.
I don't think that the point Bostrom is making hangs on this timeline of updates; the point is simply that, if you take an AGI to human level through purely improvement to qualitative intelligence, it will be super intelligent immediately. This point is important regardless of timeline; if you have an AGI that is low on quality intelligence but has these other resources, it may work to improve its quality intelligence. At the point that it's quality is equivalent to a human, it will be beyond a human in ability and competence.
Perhaps this is all an intuition pump to appreciate the implications of a general intelligence on a machine.
So basically you're arguing there shouldn't be a resource overhang, because those resources should have already been applied while the AI was at a sub-human level?
I suppose one argument would be that there is a discrete jump in your ability to use those resources. Perhaps sub-human intelligences just can't read at all. Maybe the correct algorithm is so conceptually separate from the "lets throw lots of machine learning and hardware at it" approach that it doesn't work at all until it suddenly done. However, this argument simply pushes back the rhetorical buck - now we need to explain this discontinuity, and can't rely on the resource overhang.
Another argument would be that your human-level intelligence makes available to you much more resources than before, because it can earn money / steal them for you. However, this only seems applicable to a '9 men in a basement' type project, rather than a government funded Manhattan project.
Overall, I thought the case in this chapter for faster over slower takeoffs was weak.
The main considerations pointing to low recalcitrance for AI seem to be the possibility of hardware and content overhangs - though these both seem likely to have been used up already, and are anyway one-off events - and the prospect of hardware growth in general continuing to be fast, which seems reasonable but doesn't distinguish AI from any other software project.
So the argument for fast growth has to be based on optimization power increasing a huge amount, as I think Bostrom intends. The argument for that is that first people will become interested in the project, causing it to grow large enough to drive most of its own improvement, and then it will recursively self-improve to superintelligence.
I agree that optimization power applied to the problem will increase if people become very interested in it. However saying optimization power will increase seems very far from saying the project will grow large enough to rival the world in producing useful inputs for it, which seems an ambitious goal. Optimization power applied to different projects increases all the time and this doesn't happen.
It would have been good to have a quantitative sense of the scale on which the optimization power is anticipated to grow, and of where the crossover is thought to be. One of these two has to be fairly unusual for a project to take over the world it seems, yet the arguments here are too qualitative to infer that anything particularly unusual would happen, or to distinguish AI from other technologies.
I don't mean to claim that the claim is false - that would be a longer discussion - just that the case here seems insufficient.
We might have a takeoff that does not involve a transition to what we'd call general intelligence. All the AI needs is an ability to optimize very well in one area that is critical to human civilization -- warfare, financial trading, etc -- and the ability to outwit humans who try to stop it.
There are ways that the AI could prevent humans from stopping it without the full smartness/ trickiness/ cleverness that we imagine when we talk about general intelligence.
Although I want to avoid arguing about stories here, I should give an example, so imagine a stock-trading AI that has set up its investments in a way that ensures that stopping it would bring financial disaster to a wide variety of powerful financial entities, while letting it continue would produce financial benefit for them, at least to a certain point; and that this effect is designed to grow larger as the AI takes over the world economy. Or more simply, a military AI that sets up a super-bomb on a tripwire to protect itself: Nothing that needs 1000x-human-intelligence, just a variation of the tripwire-like systems and nuclear bombs that exist today. Both these could be part of the system's predefined goals, not necessarily a convergent goal which the system discovers as described by Omohundro. Again, these are just meant to trigger the imagination about a super-powerful AI without general intelligence.
This chapter seems to present some examples of how algorithmic recalcitrance could be very low, but I think it doesn't, in the relevant sense. Two of the three arguments in that part of the chapter (p69-70) are about how low recalcitrance might be mistaken for high recalcitrance, rather than about how low recalcitrance would occur. (One says that a system whose performance is the maximum of two parts might shift its growth from that of one part to that of the other; the other says we might be biased to not notice growth in dumb-seeming entities). The third argument (or first, chronologically) is that a key insight might be discovered after many other things are in place. This is conceivable, but seems to rarely happen at a large scale, and comes with no particular connection with intelligence - you could make exactly the same argument about any project (e.g. the earlier intelligence augmentation projects).
Yes, I agree. On page 68 he points out that the types of problems pre-EM are very different from those post-EM, but it could be that availability bias makes the former seem larger than the latter. We are more familiar with them, and have broken them down into many sub-problems.
Paradoxically, even though this 'taskification' is progress towards EMs, it makes them appear further away as they highlight the conjunctive nature of the task. Our estimates for the difficulty of a task probably over-state the difficulty of easy tasks and under-state the difficulty of easy tasks, which could mean that breaking down a problem increases our estimate of its difficulty, because it is now 10 tasks-worth-of-effort rather than one-tasks-worth-of-effort.
In order to model intelligence explosion, we need to be able to measure intelligence.
Describe a computer's power as . What is the relative intelligence of these 3 computers?
Is 2 twice as smart as 1 because it can compute twice as many square roots in the same time? Is it smarter by a constant C, because it can predict the folding of a protein with C more residues, or can predict weather C days farther ahead?
If we want to ask where superintelligence of some predicted computational power will lie along the scale of intelligence we know from biology, we could look at evolution over the past 2 billion years, construct a table estimating how much computation evolution performed in each million years, and see how the capabilities of the organisms constructed scaled with computational power.
This would probably conclude that superintelligence will explode, because, looking only at more and more complex organisms, the computational power of evolution has decreased dramatically owing to larger generation times and smaller population sizes, yet the rate of intelligence increase has probably been increasing. And evolution is fairly brute-force as search algorithms go; smarter algorithms should have lower computational complexity, and should scale better as genome sizes increase.
This would probably conclude that superintelligence will explode, because, looking only at more and more complex organisms, the computational power of evolution has decreased dramatically owing to larger generation times and smaller population sizes, yet the rate of intelligence increase has probably been increasing.
It seems hard to know how other parameters have changed though, such as the selection for intelligence.
In order to model intelligence explosion, we need to be able to measure intelligence.
Describe a computer's power as . What is the relative intelligence of these 3 computers?
Perhaps we should talk about something like productivity instead of intelligence, and quantify according to desirable or economically useful products.
Perhaps we should talk about something like productivity instead of intelligence, and quantify according to desirable or economically useful products.
I am not sure I am very sympathetic with a pattern of thinking that keeps cropping up, viz., as soon as our easy and reflexive intuitions about intelligence become strained, we seem to back down the ladder a notch, and propose just using an economic measure of "success".
Aside from (i) somewhat of a poverty of philosophical of imagination (e.g. what about measuring the intrinsic interestingness of ideas, or creative output of various kinds... or, even, dare I say beauty if these superintellects happen to find that worth doing [footnote 1]), I am skeptical on grounds of (ii): given the phase change in human society likely to accompany superintelligence (or nano, etc.), what kind of economic system is likely to be around, in the 22nd century, the 23rd.... and so on?
Economics, as we usually use the term, seems as dinosaur-like as human death, average IQs of 100, energy availability problems, the nuclear biological human family (already DOA); having offspring by just taking the genetic lottery cards and shuffling... and all the rest of social institutions based on eons of scarcity -- of both material goods, and information.
Economic productivity, or perceived economic value. seems like the last thing we ought to based intelligence metrics on. (Just consider some the economic impact of professional sports -- hardly a measure of meteoric intellectual achievement.)
[Footnote 1]: I have commented in here before about the possibility that "super-intelligences" might exhibit a few surprises for us math-centric, data dashboard-loving, computation-friendly information hounds.
(Aside: I have been one of them, most of my life, so no one should take offense. Starting far back: I was the president of Mu Alpha Theta, my high school math club, in a high school with an advanced special math program track for mathematically gifted students. Later, while a math major at UC Berkeley, I got virtually straight As and never took notes in class; I just went to class each day, sat in the front row, and payed attention. I vividly remember getting the exciting impression, as I was going through the upper division math courses, that there wasn't anything I couldn't model.)
After graduation from UCB, at one point I was proficient in 6 computer languages. So, I do understand the restless bug, the urge to think of a clever data structure and to start coding ... the impression that everything can be coded, with enough creativity .
I also understand what mathematics is, pretty well. For starters, it is a language. A very, very special language with deep connections to the fabric of reality. It has features that make it one of the few, perhaps only candidate language, for being level of description independent. Natural languages, and technical domain-specific languages are tied to corresponding ontologies and to corresponding semantics' that enfold those ontologies. Math is the most omni-ontological, or meta-ontological language we have (not counting brute logic, which is not really a "language", but a sort of language substructure schema.
Back to math. It is powerful, and an incredible tool, and we should be grateful for the "unreasonable success" it has (and continue to try to understand the basis for that!)
But there are legitimate domains of content beyond numbers. Other ways of experiencing the world's (and the mind's) emergent properties. That is something I also understand.
So, gee, thanks to whomever gave me the negative two points. It says more about you than it does about me, because my nerd "street cred" is pretty secure.
I presume the reader "boos" are because I dared to suggest that a superintelligence might be interested in, um, "art", like the conscious robot in the film I mention below, who spends most of its free time seeking out sketch pads, drawing, and asking for music to listen to. Fortunately, I don't take polls before I form viewpoints, and I stand by what I said.)
Now, to continue my footnote: Imagine that you were given virtually unlimited computational ability, imperishable memory, ability to grasp the "deductive closure" of any set of propositions or principles, with no effort, automatically and reflexively.
Imagine also that you have something similar to sentience or autonomy, and can choose your own goals. SUppose also, say, that your curiosity functions in such a way that "challenges" are more "interesting" to you than activities that are always a fait accompli .
What are you going to do? Plug yourself into the net, and act like an asperger spectrum mentality, compulsively computing away at everything that you can think of to compute?
Are you going to find pi to a hundred million digits of precision?
Invert giant matrices just for something to do?
It seems at least logically and rationally possible that you will be attracted to precisely those activities that are not computational givens before you even begin doing them. You might view the others as pointless, because their solution is preordained.
Perhaps you will be intrigued by things like art, painting, or increasingly beautiful virtual reality simulations for the sheer beauty of them.
In case anyone saw the movie "The Machine" on Netflix, it dramatizes this point, which was interesting. It was, admittedly, not a very deep film; one inclined to do so can find the usual flaws, and the plot device of using a beautiful female form could appear to be a concession to the typically male demographic for SciFi films -- until you look a bit deeper at the backstory of the film (that I mention below.)
I found one thing of interest: when the conscious robot was left alone, she always began drawing again, on sketch pads.
And, in one scene wherein the project leader returned to the lab, did he find "her" plugged-into the internet, playing chess with supercomputers around the world? Working on string theory? Compiling statistics about everything that could conceivably be quantified?
No. The scene finds the robot (in the film, it has sensory responsive skin, emotions, sensory apparati etc. based upon ours) alone in a huge warehouse, having put a layer of water on the floor, doing improvisational dance with joyous abandon, naked, on the wet floor, to loud classical music, losiing herself in the joy of physical freedom, sensual movement, music, and the synethesia of music, light, tactility and the experience of "flow".
The explosions of light leaking through her artificial skin, in what presumably were fiber ganglia throughout her-its body, were a demure suggestion of whole body physical joy of movement, perhaps even an analogue of sexuality. (She was designed partly as an em, with a brain scan process based on a female lab assistant.)
The movie is worth watching just for that scene (please -- it is not for viewer eroticism) and what it suggests to those of us who imagine ourselves overseeing artificial sentience design study groups someday. (And yes, the robot was designed to be conscious, by the designer, hence the addition to the basic design, of the "jumpstart" idea of uploading properties of the scanned CNS of human lab assistant.)
I think we ought to keep open our expectations, when we start talking about creating what might (and what I hope will) turn out to be actual minds.
Bostrom himself raises this possibility when he talks about untapped cognitive abilities that might already be available within the human potential mind-space.
I blew a chance to talk at length about this last week. I started writing up a paper, and realized it was more like a potential PhD dissertation topic, than a post. So I didn't get it into usable, postable form. But it is not hard to think about, is it? Lots of us in here already must have been thinking about this. ... continued
If you are fine with fiction, I think the Minds from Iain Banks Culture are a much better starting point than dancing naked girls. In particular, the book Excession describes the "Infinite Fun Space" where Minds go to play...
Thanks, I'll have a look. And just to be clear, watching *The Machine" wasn't driven primarily by prurient interest -- I was drawn in by a reviewer who mentioned that the backstory for the film was a near-future world-wide recession, pitting the West with China, and that intelligent battlefield robots and other devices were the "new arms race" in this scenario.
That, and that the film reviewer mentioned that (i) the robot designer used quantum computing to get his creation to pass the Turing Test (a test I have doubts about as do other researchers, of course, but I was curious how the film would use it) - and (ii) yet the project designer continued to grapple with the question of whether his signature humanoid creation was really conscious, or a "clever imitation", pulled me in.
(He verbally challenges and confronts her/it, in an outburst of frustration, in his lab about this, roughly two thirds of the way through the movie and she verbally parrys plausible responses.)
It's really not all that weak, as film depictions of AI go. It's decent entertainment with enough threads of backstory authenticity, political and philosophical, to tweak one's interest.
My caution, really, was a bit harsh; applying largely to the uncommon rigor of those of us in this group -- mainly to emphasise that the film is entertainment, not a candidate for a paper in the ACM digital archives.
However, indeed, even the use of a female humanoid form makes tactical design sense. If a government could make a chassis that "passed" the visual test and didn't scream "ROBOT" when it walked down the street, it would have much greater scope of tactical application --- covert ops, undercover penetration into terrorist cells, what any CIA clandestine operations officer would be assigned to do.
Making it look like a woman just adds to the "blend into the crowd" potential, and that was the justification hinted at in the film, rather than some kind of sexbot application. "She" was definitely designed to be the most effective weapon they could imagine (a British-funded military project.)
Given that over 55 countries now have battlefield robotic projects under way (according to Kurzweil's weekly newsletter) -- and Google got a big DOD project contract recently, to proceed with advanced development of such mechanical soldiers for the US government -- I thought the movie worth a watch.
If you have 90 minutes of low-priority time to spend (one of those hours when you are mentally too spent to do more first quality work for the day, but not yet ready to go to sleep), you might have a glance.
Thanks for the book references. I read mostly non-fiction, but I know sci fi has come a very long way, since the old days when I read some in high school. A little kindling for the imagination never hurts. Kind regards, Tom ("N.G.S")
To continue:
If there are untapped human cognitive-emotive-apperceptive potentials (and I believe there are plenty), then all the more openness to undiscovered realms of "value" knowledge, or experience, when designing a new mind architecture, is called for. To me, that is what makes HLAI (and above) worth doing.
But to step back from this wondrous, limitless potential, and suggest some kind of metric based on the values of the "accounting department", those who are famous for knowing the cost of everything but the value of nothing, and even more famous for, by default, often derisively calling their venal, bottom-line, unimaginative dollars and cents worldview a "realistic" viewpoint (usually a constraint based on lack of vision) -- when faced with pleas for SETI grants, or (originally) money for the National Supercomputing Grid, ..., or any of dozen of other projects that represent human aspiration at its best -- seems, to me, to be shocking.
I found myself wondering if the moderator was saying that with a straight face, or (hopefully) putting on the hat of a good interlocutor and firestarter, trying to flush out some good comments, because this week had a diminished activity post level.
Irrespective of that, another defect, as I mentioned, is that economics as we know it will prove to be relevant for an eyeblink, in the history of the human species (assuming we endure.) We are closer to the end of this kind of scarcity-based economics, than the beginning (assuming even one or more singularity style scenarios come to pass, like nano.)
It reminds me of the ancient TV series Star Treck New Gen, in an episode wherein someone from our time ends up aboard the Enterprise of the future, and is walking down a corridor speaking with Picard. The visitor asks Picard something like "who pays for all this", as the visitor is taking in the impressive technology of the 23rd century vessel.
Picard replys something like, "The economics of the 23 century are somewhat different from your time. People no longer arrange their lives around the constraint of amassing material goods...."
I think it will be amazing if even in 50 years, economics as we know it, has much relevance. Still less so in future centuries, if we -- or our post-human selves are still here.
Thus, economic measures of "value" or "success" are about the least relevant metric we ought to be using, to assess what possible critaris we might give to track evolving "intelligence", in the applicable, open-ended, future-oriented sense of the term.
Economic --- i.e. marketplace-assigned "value" or "success" is already pretty evidently a very limiting, exclusionary way to evaluate achievement.
Remember: economic value is assigned mostly by the center standard deviation of the intelligence bell curve. This world, is designed BY, and FOR, largely, ordinary people, and they set the economic value of goods and services, to a large extent.
Interventions in free market assignment of value are mostly made by even "worse" agents... greed-based folks who are trying to game the system.
Any older people in here might remember former Senator William Proxmire's "Golden Fleece" award in the United States. The idea was to ridicule any spending that he thought was impractical and wasteful, or stupid.
He was famous for assigning it to NASA probes to Mars, the Hubble Telescope (in its several incarnations), the early NSF grants for the Human Genome project..... National Institute for Mental Health programs, studies of power grid reliability -- anything that was of real value in science, art, medicine... or human life.
He even wanted to close the National Library of Congress, at one point.
THAT, is what you get when you have ECONOMIC measures to define the metric of "value", intelligence or otherwise.
So, it is a bad idea, in my judgement, any way you look at it.
Ability to generate economic "successfulness" in inventions, organization restructuring... branding yourself of your skills, whatever? I don't find that compelling.
Again, look at professional sports, one of the most "successful" economic engines in the world. A bunch of narcissistic, girl-friend beating pricks, racist team owners... but by economic standards, they are alphas.
Do we want to attach any criterion -- even indirect -- of intellectual evolution, to this kind of amoral morass and way of looking at the universe?
Back to how I opened this long post. If our intuitions start running thin, that should tell us we are making progress toward the front lines of new thinking. When our reflexive answers stop coming, that is when we should wake up and start working harder.
That's because this --- intelligence, mind augmentation or redesign, is such a new thing. The ultimate opening-up of horizons. Why bring the most idealistically-blind, suffocatingly concrete worldview, along into the picture, when we have a chance at transcendence, a chance to pursue infinity?
We need new paradigms, and several of them.
In figure 7 (p63) the human and civilizational baselines are defined relative to 2014. Note that if human civilization were improving in its capabilities too - perhaps because of individual cognitive enhancements, technological progress, or institutional improvements - the crossover point would move upwards, while the 'strong superintelligence point' would not. Thus AI could in principle reach the 'strong superintelligence' point before the 'crossover'.
Yes, I fully agree except your last point. I think the expectation what can be called 'strong superintelligence' will rise as well. People will perceive their intelligence boost by supportive aids as 'given assistance'.
Especially in a slow takeoff scenario we will have many tools incorporating weak AI superintelligent capabilities. A team of humans with these tools will reach 'strong superintelligence' in todays standards. In crossover a sole AI might be superintelligent either.
I disagree to draw the baselines for human, civilization and strong superintelligence horizontally. Bostrums definition of human baseline (p62-63):
A horizontal line labeled "human baseline" represents the effective intellectual capabilities of a representative human adult with access to the information sources and technological aids currently available in developed countries.
As information sources, technological aids and communication capabilies (e.g. immersive 3D VR work environments) improve over time, these 'baselines' should be rising, see following figure:

Crossover involves the project contributing more to itself than the outside world does. Note that this is not implied by even the quickest growth. A massive project might still mostly engage in trade with the rest of society, benefiting largely from their innovations, and contributing its own to wider progress. The picture above shows an AI project growing to rival the whole world in capability, at which point it might naturally contribute a lot to its own growth, relative to what the world contributes. However the world can also grow. If we are talking about a particular AI project, then other AI projects are a natural part of the rest of the world to be experiencing fast growth at the same time. And if fast-growing AI projects were improving every labor-based part of the economy, then outside growth should also increase. We will consider this sort of thing more in a future chapter about whether single projects take power, but I think it is worth asking whether reaching 'crossover' should be the default expectation.
A step change in the rate of gain in average organizational efficiency is perhaps conceivable, but it is hard to see how even the most radical scenario of this kind could produce anything faster than a slow takeoff, since organizations operated by humans are confined to work on human timescales. (p67)
It seems a bit unclear how fast 'human timescales' are, especially since organizations usually consist of humans and other equipment. Are securities traded at human timescales? What are the speed limits for organizations of humans?
Lemma1: Superintelligence could be slow. (imagine for example IQ test between Earth and Mars where delay between question and answer is about half hour. Or imagine big clever tortoise which could understand one sentence per hour but then could solve riemann hypothesis)
Lemma2: Human organization could rise quickly. (It is imaginable that bilions join organization during several hours)
Next theorem is obvious :)
And there are time-scales of processes used or needed by intelligent systems that do not speed up easily. The prime example is insight into physical processes. Even if you can infer all there is to infer from an experiment - you still have to wait for the experiment to complete. Some physical experiments are inherently slow. Consider the simple example of observation of the astronomical cycles. You just can't speed them up. Luckly humans have by now observed most of them. Granted, sometimes you can infer the whole cycle from only parts of the cycle. And then many experiments need physical construction of experimental apparatus which also cannot be sped up arbitrarily.
There's an argument against fast takeoff based on computational complexity theory.
Fast takeoff seems to imply that there is a general purpose algorithm that, given large-but-practically-possible amount computational resources, could solve problem instances with real-life relevance in many different domains. (If there is just a bunch of domain-specific algorithms, takeoff cannot be as fast.)
Complexity theory tells that it might not be the case. Many relevant problem classes are believed to be computationally hard.
For example, if the AGI wants to "solve" (i.e. significantly optimize) economics, it might have to deal with large-size instances of task scheduling problems. Since we know that the best possible general purpose algorithm for task scheduling is unlikely to run faster than exponential time, even exponential hardware and software speedup won't make optimal task scheduling tractable! Therefore, the exponential "jump" in AGI's algorithmic capabilities during the initial self-optimization period would not lead to corresponding exponential "jump" in its problem-solving capabilities.
It's still possible (although unlikely) that this general purpose algorithm could "beat" any existing domain-specific algorithm. Even more, the argument still stands even if we assume that the AGI is a better problem solver in any strategically relevant field than the combined forces of human experts and narrow AI. The point is that this "better" is unlikely to give the AGI strategical dominance. I think that the capability to solve problems humanity can not solve on its own is to be required for strategical dominance.
On the other hand, its worth noting that general-purpose solvers of computationally hard problems have seen large practical success in the last decade. (SAT and constraint programming). This seems to weaken the argument, but to what extent?
It's a pity that Bostrom never mentions complexity classes in his book.
"Insect-level" intelligence may be sufficient to create very dangerous AI systems, even if they are not superintelligent. Bostrom does not really talk about this kind of thing, maybe because it's just not the purpose of the book.
It is another hazard we should think about.
FWIW I think this 'milestone' is much less clear than Bostrom makes it sound. I'd imagine there's a lot of variation in fidelity of simulation, both measured in terms of brain signals and in terms of behaviour, and I'd be surprised if there were some discrete point at which everybody realised that they'd got it right.
Bostrom says that a fast takeoff would leave scant time for human deliberation (p64). While it certainly leaves much less time to deliberate than the other scenarios, I can imagine two days allowing substantially more deliberation fifty years hence than it would now. Information aggregation and deliberation technologies could arguably be improved a lot. Automatic but non-agent systems might also be very good by the time human-level agents are feasible.
I want to try to break down the chain of events in this region of the graph. Just to start the ball rolling:
So, one question is the degree to which additional computer hardware has to be built in order to support additional levels of recursive self-improvement.
If the rate of takeoff is constrained by a need for the AI to participate in the manufacture of new hardware with assistance from people, then (correct me if I am missing something) we have a slow or moderate takeoff.
If there is already a "hardware overhang" when key algorithms are created, then perhaps a great deal of recursive self-improvement can occur rapidly within existing computer systems.
Manufacturing computer components is quite involved. A hardware/software system which can independently manufacture similar components to the ones it runs on would have to already have the abilities of dozens of different human specialists. It would already be a superintelligence.
If there was no hardware overhang initially, however, strong incentives would exist for people, along with whatever software tools they have, to optimize the system so that it runs faster, and on less hardware.
If development follows the pattern of previous AI systems, chances are they will succeed. Additional efficiencies can always be wrung out of prototype software systems.
Therefore, if there is no hardware overhang initially, one probably will materialize fairly shortly through software optimization which includes human engineers in the process.
In the past, such processes have delivered x1000 increases.
So, when the AI is turned on, there could be a hardware overhang of 1, 10, or 100 right within the computer it is on.
My belief is that the development team, if there is just one, has a good chance to succeed at preventing this initial AI from finding its way to the internet (since I gather this is controversial, I should work to substantiate that later), and attaching more processing power to it will be under their control.
If they do decide to add hardware to the first AI, either via increasing the server farm size, cloud or internet release, I think I can make a case that the team will be able to justify the investment to obtain a hardware speedup of x1000 fairly quickly if the cost of the first set of hardware is less than $1 Billion, or has a chance of expropriating the resources.
The team can also decide to try to optimize how well it runs on existing hardware, gaining x 1000. The kind of optimization process might take maybe two years today.
So as a point estimate I am thinking that the developers have the option of increasing hardware overhang by x1,000,000 in two years or less. Can work on a better estimate over time.
That x1,000,000 improvement can be used either for speed AI or to run additional processes.
So, when the AI is turned on, there could be a hardware overhang of 1, 10, or 100 right within the computer it is on.
I didn't follow where this came from.
Also, when you say 'hardware overhang', do you mean the speedup available by buying more hardware at some fixed rate? Or could you elaborate - it seems a bit different from the usage I'm familiar with.
Here is what I mean by "hardware overhang." It's different from what you discussed.
Let's suppose that YouTube just barely runs in a satisfactory way on a computer with an 80486 processor. If we move up to a processor with 10X the speed, or we move to a computer with ten 80486 processors, for this YouTube application we now have a "hardware overhang" of nine. We can run the YouTube application ten times and it still performs OK in each of these ten runs.
So, when we turn on an AI system on a computer, let's say a neuromorphic NLP system, we might have enough processing power to run several copies of it right on that computer.
Yes, a firmer definition of "satisfactory" is necessary for this concept to be used in a study.
Yes, this basic approach assumes that the AI processes are acting fully independently and in parallel, rather than interacting. We do not have to be satisfied with either of those later.
Anyway, what I am saying here is the following:
Let's say that in 2030 a neuromorphic AI system is running on standard cloud hardware in a satisfactory according to a specific set of benchmarks, and that the hardware cost is $100 Million.
If ten copies of the AI can run on that hardware, and still meet the defined benchmarks, then there is a hardware overhang of nine on that computer.
If, for example, a large government could martial at least $100 Billion at that time to invest in renting or quickly building more existing hardware on which to run this AI, then the hardware overhang gets another x1000.
What I am further saying is that at the moment this AI is created, it may be coded in an inefficient way that is subject to software optimization by human engineers, like the famous IBM AI systems have been. I estimate that software optimization frequently gives a x1000 improvement.
That is the (albeit rough) chain of reasoning that leads me to think that a x1,000,000 hardware overhang will develop very quickly for a powerful AI system, even if the AI does not get in the manufacturing business itself quite yet.
I am trying to provide a dollop of analysis for understanding take-off speed, and I am saying that AI systems can get x1,000,000 the power shortly after they are invented, even if they DO NOT recursively self-improve.
At the same time this additional x1,000,000 or so hardware overhang is developing (there is a good chance that a significant hardware overhang existed before the AI was turned on in the first place), the system is in the process of being interfaced and integrated by the development team with an array of other databases and abilities.
Some of these databases and abilities were available to the system from the start. The development team has to be extremely cautious about what they interface with which copies of the AI-these decisions are probably more important to the rate of takeoff than creating the system in the first place.
Language Acquisition
Because of the centrality of language to human cognition, the relationship between language acquisition and takeoff speed is worth analyzing as a separate question from takeoff speed for an abstract notion of general intelligence.
Human-level language acquisition capability seems to be a necessary condition to develop human-level AGI, but I do not believe it is a necessary condition to develop an intelligence either capable of manufacturing, or even of commerce, or hiring people and giving them a set of instructions. (For this reason, among, others, thinking about surpassing human-level does not seem to be the right question to ask if we are debating policy.)
Here are three scenarios for advanced AI language acquisition:
1) The system, like a child, is initially capable of language acquisition, but in a somewhat different way. (Note that for children, language acquisition and object recognition skills develop at about the same time. For this reason, I believe that these skills are intertwined, although they have not been that intertwined in the development of AI systems so far.)
2) The system begins with parts of a single language somewhat hardwired.
3) The system performs other functions than language acquisition, and any language capability has to be interfaced in a second phase of development.
If 1) comes about, and the system has language acquisition capability initially, then it will be able to acquire all human languages it is introduced to very quickly. However, the system may still have conceptual deficits it is unable to overcome on its own. In the movies the one they like is a deficit of emotion understanding, but there could be others, for instance, a system that acquired language may not be able to do design. I happen to think that emotion understanding may prove more tractable than in the movies. So much of human language is centered around feelings, therefore a significant level of emotion understanding (which differs from emotion recognition) is a requirement for some important portions of language acquisition. Some amount of emotion recognition and even emotion forecasting is required for successful interactions with people.
In case 2), if the system is required to translate from its first language, it will also be capable of communicating with people in these other languages within a very short time, because word and phrase lookup tables can be placed right in working memory. However, it may have lower comprehension and its phrasing might sound awkward.
In either case 1) or 2), roughly as soon as the system develops some facility at language, it will be capable of superhumanly communicating with millions of people at a time, and possibly with everyone. Why? Because computers have been capable of personalized communication with millions of people for many years already.
In case 3), the system was designed for other purposes but can be interfaced in a more hard-wired fashion with whatever less-than-complete forms of linguistic processing are available at the time. These less-than-complete abilities are already considerable today, and they will become even more considerable under any scenario other than disinclination to advance and government regulation.
A powerful sub-set of abilities from a list more like this:
Planning, design, transportation, chemistry, physics, engineering, commerce, sensing, object recognition, object manipulation and knowledge base utilization.
Might be sufficient to perform computer electronics manufacturing.
Little or no intelligence is required for a system to manufacture using living things.
Why would much of this optimization for running on existing hardware etc not have been done prior to reaching human-level? Are we assuming there was a sharp jump, such that the previous system was much worse?
Also, where do you get these figures from?
The x1000 gained by adding more hardware just comes if the developers have a government or a big company as their partner and they buy more hardware or rent on the cloud. The botnet is another way to gain this x1000.
Now to my claim of possible x1000 software speed-up for AI systems: The amount to be gained from software optimization in any specific project is indeed a random variable, and conditions when an AGI system is invented make a difference.
Where has such speed-up come from in problems I have been involved with or heard about?
When developers are first creating a piece of software, typically they are rewarded by being focused first on just getting some result which works. The first version of the code may come out slower because they take the easy way out and just use whatever code is available in some library, for instance. Once they have proved the concept, then they optimize for performance.
Developers can adjust the resource level they have to invest to try to improve the speed at which software runs and how fast they gain these speed-ups. If they invest little or no resources in optimization, the speed will not increase.
If the code was written in a high-level language, then it is relying on the compiler to perform some optimization. Today's compilers do not utilize any knowledge about the data sets they are going to operate on, and also optimizing for a system with a variety of different computers is difficult.
True enough, the technology of optimizing compilers almost certainly will improve between now and when this system is created. Maybe by that time when we are programming in a high-level language, the interpreter, compiler or other code transformer will be able to automagically correct some of the sub-optimal code we write.
When I was working in database design, de-normalization, a way of combining tables, would change join operations from taking an impossibly long amount of time-I would just stop the query-to being possible in a few seconds.
When working on a problem involving matrices and I was able to identify a sparsity condition and use a specialized algorithm, then I got this kind of speed-up as well.
After creating code to process a file, writing a macro that runs the code on 1,000 files.
This kind of thing just seems to happen a lot. I guess I make no guarantees.
During some phases of an AI system's early improvement, sometimes we will have difficulty discerning whether the system is recursively self-improving or whether it is being improved by the developers.
When a child learns to count pennies, they get faster at after they have done it a few times (self-improvement). Then, after they learn to multiply, someone comes along and shows them that it's even faster to create groups of five and count the number of groups, an optimization that comes from an external source.
Since this is a prediction, there is no shame in following your lead: Here are some possible reasons why non-recursive self-improvement might not gain x1000 in software speed-up:
Suppose the last step forward in the development of an AI system is to interface and integrate six different software systems that have each been improving steadily over many years using pre-digested data sources that have already been heavily pre-processed. Maybe most of human knowledge has been captured in some steadily improving fast-access data structures years before AGI actually comes about. To create AGI, the developers write some linking code add a few new things. In that case, the X1000 software speed-up may not be possible.
We also have little idea how software optimization might improve algorithm speed thirty years from now, for example, on an array of 1,000,000 interconnected quantum computers and field programmable analog photonic processors with nanotech lenses that change shape, or something. In these environments, I guess the bottleneck could be setting up the run rather than actually making some enormous calculation.
One way to slow things down if we did not know what to do next with an AGI would be, immediately after the system began to work, to halt or limit investment in software optimization, halt buying more hardware, and halt hardware optimization.
Instead, I prefer to plan ahead.
If the initial system does not find a hardware overhang, it seems unclear to me that a 1000x less expensive system necessarily will. For any system which doesn't have a hardware overhang, there is another 1000x less efficient that also doesn't.
If there is already a "hardware overhang" when key algorithms are created, then perhaps a great deal of recursive self-improvement can occur rapidly within existing computer systems.
Do you mean that if a hardware overhang is large enough, the AI could scale up quickly to the crossover, and so engage in substantial recursive self-improvement? If the hardware overhang is not that large, I'm not sure how it would help with recursive self-improvement.
Algorithm development starts with an abstract idea. Then this concept has to be transformed into computational form for testing. The initial proof-of-concept algorithm is as close as possible to the abstract idea. This first key algorithm is the reference. All future improved algorihms versions have to be checked against this reference. High hardware overhang of this new created algorithm is very likely.
For complex hardware extensions it takes years until these new ressources (e.g. MMX, SSE, AVX, multi-cores, GPU) are fully exploited by software. Compilers have to be optimized first, assembler optimization of critical sections give further optimization potential. PS4 lead architect Mark Cerny said regarding the previous PS3 Cell processor: "People have now spent eight years learning the depths of that architecture, how to make games look beautiful."
Assume two key algorithms inspired by biological brain analyis:
- simulation of a neuron
- pattern analysis structure consisting of simulated neurons
If an AI reaches superhuman capabilities in software engineering and testing it could improve its own core base. All aquired knowledge remains intact. If necessary the AI develops a migration tool to transfer stored information into the improved system. If configurable hardware is used this can be optimized as well. Hardware overhang will be even higher and FOOM more likely.
I found data on renewable funding and progress (see above), to test how extra interest and funding translates to progress, because this is a key part of Bostrom's argument for fast AI progress prior to the 'crossover'. Can you find similar data for any other areas?
So the base rate for the kind of transition entailed by a fast or medium takeoff scenario, in terms of the speed and magnitude of the postulated change, is zero: it lacks precedent outside myth and religion.
Bostrom says this, but seems to use it only as a nice way of introducing a position to argue against - that a medium or fast transition is unlikely - and not so much as evidence. Yet it seems to me that this is potentially substantial evidence, and deserves attention.
If we want to combine this outside view evidence with other object level arguments, one way to do it is to ask how often there are explosive transitions after there have seemed such good reasons for explosive transitions. That is, if this is the first time in history that optimization power has seemed set to substantially increase while recalcitrance has seemed likely to decrease so much, then the previous evidence that explosive transitions have not happened is perhaps irrelevant, and we might expect a large burst of progress. However if humans often look at the future and see declining recalcitrance and increasing optimization power (to the extent that Bostrom sees these things), and yet there haven't been such transitions, then we should hesitate in accepting that we will get one this time.
Have things looked this way before?
One might complain that the word 'takeoff' for the progression from human-level intelligence to superintelligence biases the discussion toward supposing that this progress will be fast, or in some other way resemble the launch of an airplane or rocketship.
For a Dornier DO-X it took 5 km to reach takeoff speed in 1929. To me many mental connections match the intended sense:
- high tech required (aircraft)
- high power needed to accelerate
- long distance to reach takeoff speed
- losing contact to ground in soft transition
- steep rising and gaining further speed
- switching to rocket drive
... and travel to Mars...
Other suggestions welcome! Foom is ok for a closed LW community but looks strange to outsiders.
Another way to put this, avoiding certain ambiguities, is 'a point at which the inputs to a project are mostly its own outputs', such that improvements to its outputs feed back into its inputs.
This doesn't seem to follow. Most inputs of the system, for a very long number of time-steps (certainly before the conception of deception) will come from the external world at is learns.
The relevant inputs here are only those that will cause self improvement of the relevant kind, which would be likely outnumbered by non self-improvement inputs, such as perceptions, query results etc...
It could be, that some bellow human level (general or not) intelligence explodes into (general) superintelligence.
It's worth to consider that case, too.
A system which can perform language acquisition but does not start out knowing a language might appear like this. It might start out with fewer overall abilities than an infant, but grow its abilities rapidly.
If you learned that there would definitely be a fast takeoff, what would you do? What about a moderate or slow one?
Slightly factious answer: divert funding from other Xrisks, and indeed all long-term projects, towards friendliness research. Be less concerned about long-term health risks. Reduce savings in my 401k. Worry less about non-AGI instigated value drift.
The recalcitrance for making networks and organizations in general more efficient is high. A vast amount of effort is going into overcoming this recalcitrance, and the result is an annual improvement of humanity's total capacity by perhaps no more than a couple of percent.
This is the first time we have close to a quantitative estimate for recalcitrance: a couple of percent a year for something as big as human society, and 'a vast amount' of effort. Do you think this recalcitrance is high relative to that of other systems under consideration? Also, what efforts do you think count as 'overcoming this recalcitrance'?
What empirical evidence could you look at to better predict the future winner of the Foom Debate? (for those who looked at it above)
One way you could frame a large disagreement in it is as whether there are likely to be simple insights that can 'put the last puzzle piece' in a system (as Bostrom suggest), or massively improve a system in one go, rather than via a lot of smaller insights. This seems like a thing where we should be able to get heaps of evidence from our past experiences with insights and technological progress.
The effectiveness of learning hyper-heuristics for other problems, i.e. how much better algorithmically-produced algorithms perform than human-produced algorithms, and more pertinently, where the performance differential (if any) is heading.
As an example, Effective learning hyper-heuristics for the course timetabling problem says: "The dynamic scheme statistically outperforms the static counterpart, and produces competitive results when compared to the state-of-the-art, even producing a new best-known solution. Importantly, our study illustrates that algorithms with increased autonomy and generality can outperform human designed problem-specific algorithms."
Similar results can be found for other problems, bin packing, traveling salesman, and vehicle routing being just some off-the-top-of-my-head examples.
Has anything else had ambiguous-maybe-low recalcitrance and high optimization power applied in the past? What happened?
The price-performance charts document averaged development results from subsequent technological S-curves, documented by Genrich Altschuller, inventor of TRIZ (short article, [Gadd2011]). At the begin high investment does not result in direct effect. The slope in the beginning is slowly rising because of poor technological understanding, lacking research results and high recalcitrance. More funding might start alternative S-curves. But these new developing technologies are still in their infancy and give no immediate results.
Recalcitrance in renewable energy harvesting technology is obviously high and long lasting. It is easy to harvest a little bit, but increasing efficiency and quantity was and is complex. Therefore the curves you documented are dominantly linear.
Recalcitrance in genome sequencing was different. Different technological options to do the sequencing were at hand when human genome project boosted funding. Furthermore S-curves followed each other in shorter intervals. The result is your expected funding effect:
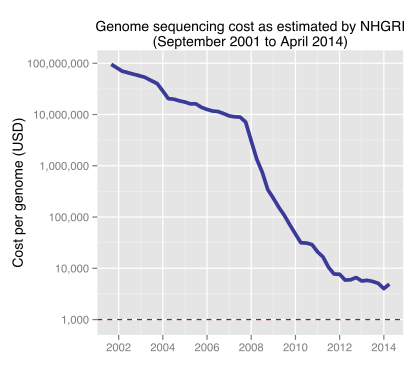
Historic cost of sequencing a human genome, license Ben Moore CC BY-SA 3.0
This is similar to question about 10time quicker mind and economic growth. I think there are some natural processes which are hard to be "cheated".
One woman could give birth in 9 month but two women cannot do it in 4.5 month. Twice more money to education process could give more likely 2*N graduates after X years than N graduates after X/2 years.
Some parts of science acceleration have to wait years for new scientists. And 2 time more scientists doesnt mean 2 time more discoveries. Etc.
But also 1.5x more discoveries could bring 10x bigger profit!
We could not suppose only linear dependencies in such a complex problems.
The Carter-Reagan transition marked a major shift in energy policy. Politics matters, and less than catastrophic technology failures can make people back way away from a particular technology solution.
I was moaning to someone the other day that we have had three well-known nuclear power disasters. If the record was clean, then environmental activists would be unconcerned, we would not need as much regulation, construction lead-times would fall dramatically, nuclear would become cheaper than coal and the global warming issue would vanish completely once electric cars become practical.
The performance curves database site only has data submitted from '09 to '10. None of the data sets are up to date. There's also not much context to the data, so it can be misinterpreted easily.
The performance curves database site only has data submitted from '09 to '10. None of the data sets are up to date.
What's the relevance of this, for comparing them to energy funding earlier this century?
There's also not much context to the data, so it can be misinterpreted easily.
I agree this is a problem. I think they usually have a citation that can be followed.
Given all that is in this chapter, how likely do you find the different speeds of takeoff? (slow, moderate, and fast) (p63-64)
What do you think of 'rate of change in intelligence = optimization power/recalcitrance' (p65) as a useful model of progress in intelligence for different systems?
I am slightly concerned by the equation
- Rate of change in intelligence = Optimization Power / Recalcitrance
When introduced, Bostrom merely describes it as a monotonic function, which seems reasonable. But why do we assume that a quotient is the natural functional form?
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the sixth section in the reading guide: Intelligence explosion kinetics. This corresponds to Chapter 4 in the book, of a similar name. This section is about how fast a human-level artificial intelligence might become superintelligent.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: Chapter 4 (p62-77)
Summary
Rate of change in intelligence = Optimization power/Recalcitrance
where 'optimization power' is effort being applied to the problem, and 'recalcitrance' is how hard it is to make the system smarter by applying effort.
Notes
1. The argument for a relatively fast takeoff is one of the most controversial arguments in the book, so it deserves some thought. Here is my somewhat formalized summary of the argument as it is presented in this chapter. I personally don't think it holds, so tell me if that's because I'm failing to do it justice. The pink bits are not explicitly in the chapter, but are assumptions the argument seems to use.
Do you find this compelling? Should I have filled out the assumptions differently?
***
2. Other takes on the fast takeoff
It seems to me that 5 above is the most controversial point. The famous Foom Debate was a long argument between Eliezer Yudkowsky and Robin Hanson over the plausibility of fast takeoff, among other things. Their arguments were mostly about both arms of 5, as well as the likelihood of an AI taking over the world (to be discussed in a future week). The Foom Debate included a live verbal component at Jane Street Capital: blog summary, video, transcript. Hanson more recently reviewed Superintelligence, again criticizing the plausibility of a single project quickly matching the capacity of the world.
Kevin Kelly criticizes point 5 from a different angle: he thinks that speeding up human thought can't speed up progress all that much, because progress will quickly bottleneck on slower processes.
Others have compiled lists of criticisms and debates here and here.
3. A closer look at 'crossover'
Crossover is 'a point beyond which the system's further improvement is mainly driven by the system's own actions rather than by work performed upon it by others'. Another way to put this, avoiding certain ambiguities, is 'a point at which the inputs to a project are mostly its own outputs', such that improvements to its outputs feed back into its inputs.
The nature and location of such a point seems an interesting and important question. If you think crossover is likely to be very nearby for AI, then you need only worry about the recursive self-improvement part of the story, which kicks in after crossover. If you think it will be very hard for an AI project to produce most of its own inputs, you may want to pay more attention to the arguments about fast progress before that point.
To have a concrete picture of crossover, consider Google. Suppose Google improves their search product such that one can find a thing on the internet a radical 10% faster. This makes Google's own work more effective, because people at Google look for things on the internet sometimes. How much more effective does this make Google overall? Maybe they spend a couple of minutes a day doing Google searches, i.e. 0.5% of their work hours, for an overall saving of .05% of work time. This suggests their next improvements made at Google will be made 1.0005 faster than the last. It will take a while for this positive feedback to take off. If Google coordinated your eating and organized your thoughts and drove your car for you and so on, and then Google improved efficiency using all of those services by 10% in one go, then this might make their employees close to 10% more productive, which might produce more noticeable feedback. Then Google would have reached the crossover. This is perhaps easier to imagine for Google than other projects, yet I think still fairly hard to imagine.
Hanson talks more about this issue when he asks why the explosion argument doesn't apply to other recursive tools. He points to Douglas Englebart's ambitious proposal to use computer technologies to produce a rapidly self-improving tool set.
Below is a simple model of a project which contributes all of its own inputs, and one which begins mostly being improved by the world. They are both normalized to begin one tenth as large as the world and to grow at the same pace as each other (this is why the one with help grows slower, perhaps counterintuitively). As you can see, the project which is responsible for its own improvement takes far less time to reach its 'singularity', and is more abrupt. It starts out at crossover. The project which is helped by the world doesn't reach crossover until it passes 1.
4. How much difference does attention and funding make to research?
Interest and investments in AI at around human-level are (naturally) hypothesized to accelerate AI development in this chapter. It would be good to have more empirical evidence on the quantitative size of such an effect. I'll start with one example, because examples are a bit costly to investigate. I selected renewable energy before I knew the results, because they come up early in the Performance Curves Database, and I thought their funding likely to have been unstable. Indeed, OECD funding since the 70s looks like this apparently:
(from here)
The steep increase in funding in the early 80s was due to President Carter's energy policies, which were related to the 1979 oil crisis.
This is what various indicators of progress in renewable energies look like (click on them to see their sources):
There are quite a few more at the Performance Curves Database. I see surprisingly little relationship between the funding curves and these metrics of progress. Some of them are shockingly straight. What is going on? (I haven't looked into these more than you see here).
5. Other writings on recursive self-improvement
Eliezer Yudkowsky wrote about the idea originally, e.g. here. David Chalmers investigated the topic in some detail, and Marcus Hutter did some more. More pointers here.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about 'decisive strategic advantage': the possibility of a single AI project getting huge amounts of power in an AI transition. To prepare, read Chapter 5, Decisive Strategic Advantage (p78-90). The discussion will go live at 6pm Pacific time next Monday Oct 27. Sign up to be notified here.