(BTW: here's a writeup of one of my ideas for writing planning queries that you might be interested in)
Often we want a model where the probability of taking action a is proportional to p(a)e^E[U(x, a)], where p is the prior over actions, x consists of some latent variables, and U is the utility function. The straightforward way of doing this fails:
query {
. a ~ p()
. x ~ P(x)
. factor(U(x, a))
}
Note that I'm assuming factor takes a log probability as its argument. This fails due to "wishful thinking": it tends to prefer riskier actions. The problem can be reduced by taking more samples:
query {
. a ~ p()
. us = []
. for i = 1 to n
. . x_i ~ P(x)
. . us.append(U(x_i, a))
. factor(mean(us))
}
This does better, because since we took multiple samples, mean(us) is likely to be somewhat accurate. But how do we know how many samples to take? The exact query we want cannot be expressed with any finite n.
It turns out that we just need to sample n from a Poisson distribution and make some more adjustments:
query {
. a ~ p()
. n ~ Poisson(1)
. for i = 1 to n
. . x_i ~ P(x)
. . factor(log U(x_i, a))
}
Note that U must be non-negative. Why does this work? Consider:
P(a) α p(a) E[e^sum(log U(x_i, a) for i in range(n))]
= p(a) E[prod(U(x_i, a) for i in range(n))]
= p(a) E[ E[prod(U(x_i, a) for i in range(n)) | n] ]
[here use the fact that the terms in the product are independent]
= p(a) E[ E[U(x, a)]^n ]
= p(a) sum(i=0 to infinity) E[U(x, a)]^i / i!
[Taylor series!]
= p(a) e^E[U(x, a)]
Ideally, this technique would help to perform inference in planning models where we can't enumerate all possible states.
Interesting! How does that compare to the usual implementations of planning as probabilistic inference, as exemplified below?
(query
. (define a (prior))
. (define x (lambda (a) (world a)))
. (define r (flip (sigmoid (U (x a)))))
. a
. (= r #t))
Ozzie Gooen and Justin Shovelain
Summary
Friendly artificial intelligence (FAI) researchers have at least two significant challenges. First, they must produce a significant amount of FAI research in a short amount of time. Second, they must do so without producing enough general artificial intelligence (AGI) research to result in the creation of an unfriendly artificial intelligence (UFAI). We estimate the requirements of both of these challenges using two simple models.
Our first model describes a friendliness ratio and a leakage ratio for FAI research projects. These provide limits on the allowable amount of artificial general intelligence (AGI) knowledge produced per unit of FAI knowledge in order for a project to be net beneficial.
Our second model studies a hypothetical FAI venture, which is responsible for ensuring FAI creation. We estimate necessary total FAI research per year from the venture and leakage ratio of that research. This model demonstrates a trade off between the speed of FAI research and the proportion of AGI research that can be revealed as part of it. If FAI research takes too long, then the acceptable leakage ratio may become so low that it would become nearly impossible to safely produce any new research.
Introduction
A general artificial intelligence (AGI) is an AI that could perform all the intellectual tasks a human can.[1] When one is created, it may recursively become more intelligent to the point where it is vastly superior to human intelligences.[2] This AGI could be either friendly or unfriendly, where friendliness means it would have values that humans would favor, and unfriendliness means that it would not.[3]
It is likely that if we do not explicitly understand how to make a friendly general artificial intelligence, then by the time we make a general artificial intelligence, it will be unfriendly.[4] It is also likely that we are much further from understanding how to make a friendly artificial intelligence than we are from understanding how to make a general artificial intelligence.[5][6]
Thus, it is important to create more FAI research, but it may also be important to make sure to not produce much AGI research when doing so. If it is 10 times as difficult to understand how to make an FAI than to understand how to make an AGI, then a FAI research paper that produces 0.3 equivalent papers worth of AGI research will probably increase the chances of a UFAI. Given the close relationship of FAI and AGI research, producing FAI research with a net positive impact may be difficult to do.
Model 1. The Friendliness and Leakage Ratios for an FAI Project
The Friendliness Ratio
Let's imagine that there is necessary amount of research to build an AGI, Gremaining. There is also some necessary amount of research to build a FAI, Fremaining. These two have units of rgeneral (general AI research) and rfriendly (friendly AI research), which are not precisely defined but are directly comparable.
Which threshold is higher? According to much of the research in this field, Fremaining. We need significantly more research to create a friendly AI than an unfriendly one.
Figure 1. Example research thresholds for AGI and FAI.
To understand the relationship between these thresholds, we use the following equation.
We call this the friendliness ratio. The friendliness ratio is useful for a high level understanding of world total FAI research requirements and is a heuristic guide for how difficult the problem of differential technological development is.
The friendliness ratio would be high if Fremaining > Gremaining. For example, if there are 2000 units of remaining research for an FAI and 20 units for an AGI, the friendliness ratio would be 100. If someone published research with 20 units of FAI research but 1 unit of AI research, their research would not meet the friendliness ratio requirement (100 vs 20/1) and would thus make the problem even worse.
The Leakage Ratio
For specific projects it may be useful to have a measure that focuses directly on the negative outcome.
For this we can use the leakage ratio, which represents the amount of undesired AGI research created per unit of FAI research. It is simply the inverse of the friendliness ratio.
In order for a project to be net beneficial,
Estimating if a Project is Net Friendliness Positive
Question: How can one estimate if a project is net friendliness-positive?
A naive answer would be to make sure that it falls over the global friendliness ratio or under the global leakage ratio.
Global AI research rates need to fulfill the friendliness ratio in order to produce a FAI. Therefore, if an advance in friendliness research gets produced with FAI research Fproject, but in the process it also produces AGI research Gproject, then this would be net friendliness negative if
Later research would need to make up for this under-balance.
AI Research Example
Say that Gremaining = 200rg and Fremaining =2000rf, leading to a friendliness ratio of fglobal = 10 and a global maximum leakage ratio of lglobal = 0.1. In this case, specific research projects could be evaluated to make sure that they meet this threshold. One could imagine an organization deciding what research to do or publish using the following chart.
Research
Research
Ratio
Ratio
1
simulation
2
3
FAI
Advocacy
In this case, only Projects 2 and 3 have a leakage ratio of less than 0.1, meaning that only these would net beneficial. Even though Project 1 has generated safety research, it would be net negative.
Model 1 Assumptions:
1. There exists some threshold Gremaining of research necessary to generate an unfriendly artificial intelligence.
2. There exists some threshold Fremaining of research necessary to generate a friendly artificial intelligence.
3. If Gremaining is reached before Fremaining, a UFAI will be created. If after, an FAI will be created.
Model 2. AGI Leakage Limits of an FAI Venture
Question: How can an FAI venture ensure the creation of an FAI?
Let's imagine a group that plans to ensure that an FAI is created. We call this an FAI Venture.
This venture would be constrained by time. AGI research is being created internationally and, if left alone, will likely create an UFAI. We can consider research done outside of the venture as external research and research within the venture as internal research. If internal research is done too slowly, or if it leaks too much AGI research, an unfriendly artificial intelligence could be created before Fremaining is met.
We thus split up friendly and unfriendly research creation into two categories, external and internal research. Then we consider the derivative of each with respect to time. For simplicity, we assume the unit of time is years.
G'i = AGI research produced internally per year
F'i = FAI research produced internally per year
G'e = AGI research produced externally per year
F'e = FAI research produced externally per year
We can understand that there exists times, tf and tg, which are the times at which the friendly and general remaining thresholds are met.
tf = Year in which Fremaining is met
tg = Year in which Gremaining is met
These times can be estimated as follows:
The venture wants to make sure that tf < tg so that the eventual AI is friendly (assumption 3). With this, we find that:
Where the values of C0 and C1 both include the friendliness ratio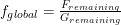 .
.
This implies a linear relationship between F'i and G'i. The more FAI research the FAI venture can produce, the more AGI research it is allowed to leak.
This gives us a clean way to go from a G'i value the venture could expect to the F'i it would need to be successful.
The C0 value describes the absolute minimum amount of FAI research necessary in order to have a chance at a successful outcome. While the resulting acceptable leakage ratio at this point would be impossible to meet, the baseline is easy to calculate. Assuming that F'e << fglobalG'e, we can estimate that
If we wanted to instead calculate G'i using F'i, we could use the following equation. This may be more direct to the intentions of a venture (finding the acceptable amount of AGI leakage after estimating FAI productivity).
Model 2 Example
For example, let's imagine that the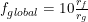 and
and 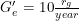 . In this case,
. In this case, 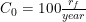 . This means that if the venture could make sure to leak exactly
. This means that if the venture could make sure to leak exactly 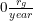 , it would need to average a FAI research rate of 10 times that of the entire world's output of AGI research. This amount increases as 100 / (1 - 10 * lproject). If the venture expects an estimated leakage ratio of 0.05, they would need to double their research output to
, it would need to average a FAI research rate of 10 times that of the entire world's output of AGI research. This amount increases as 100 / (1 - 10 * lproject). If the venture expects an estimated leakage ratio of 0.05, they would need to double their research output to  , or 20 times global AGI output.
, or 20 times global AGI output.
Figure 2. F'i per unit of maximum permissible G'i
What to do?
The numbers in the example above are a bit depressing. There is so much global AI research that it seems difficult to imagine the world averaging an even higher rate of FAI research, which would be necessary if the friendliness ratio is greater than 1.
There are some upsides. First, much hard AI work is done privately in technology companies without being published, limiting G'i. Second, the numbers of rg and rf don't perfectly correlate with the difficulty to reach them. It may be that we have diminishing marginal returns with our current levels of rg, so similar levels of rf will be easier to reach.
It's possible that Fremaining may be surprisingly low or that Gremaining may be surprisingly high.
Projects with high leakage ratios don't have to be completely avoided or hidden. The G'i value is specifically for research that will be in the hands of the group that eventually creates a AGI, so it would make sense that FAI research organizations could share high risk information between each other as long as it doesn't leak externally. The FAI venture mentioned above could be viewed as a collection of organizations rather than one specific one. It may even be difficult for AGI research implications to move externally, if the FAI academic literature is significantly separated from AGI academic literature. This logic provides a heuristic guide to choosing research projects, choosing if to publish research already done, and managing concentrations of information.
Model 2 Assumptions:
1-3. The same 3 assumptions for the previous model.
4. The rates of research creation will be fairly constant.
5. External and internal rates of research do not influence each other.
Conclusion
The friendliness ratio provides a high-level understanding of the amount of global FAI research per unit AGI research needed to create an FAI. The leakage ratio is the inverse of the friendliness ratio applied to a specific FAI project, to specify if that specific project is net friendliness positive. These can be used to understand the challenge for AGI research and tell if a particular project is net beneficial or net harmful.
To understand the challenges facing an FAI Venture, we found the simple equation
where
This paper was focused on establishing the mentioned models instead of estimating input values. If the models are considered useful, there should be more research to estimate these numbers. The models could also be improved to incorporate uncertainty, the growing returns of research, and other important limitations that we haven't considered. Finally, the friendliness ratio concept naturally generalizes to other technology induced existential risks.
Appendix
a. Math manipulation for Model 2
This last equation can be written as
Where
Recalling the friendliness ratio,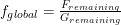 , we can simplify these constructs further.
, we can simplify these constructs further.
References
[1] What is AGI? https://intelligence.org/2013/08/11/what-is-agi/, 2013, Luke Muehlhauser
[2] Intelligence Explosion FAQ, (https://intelligence.org/ie-faq/), MIRI
[3] Artificial Intelligence as a Positive and Negative Factor in Global Risk, 2008, Global Catastrophic Risks, Yudkowsky
[4] Aligning Superintelligence with Human Interest: A Technical Research Agenda, https://intelligence.org/files/TechnicalAgenda.pdf, Nate Soares and Benja Fellenstein, MIRI
[5] Superintelligence, 2014, Nick Bostrom
[6] The Challengeof Friendly AI, https//www.youtube.com/watch?v=nkB1e-JCgmY&noredirect=1 Yudkowsky, 2007