Posts
Wiki Contributions
Comments
Yup, that was it, thankyou!
We're now working through understanding all the pieces of this, and we've calculated an MSP which doesn't quite look like the one in the post:
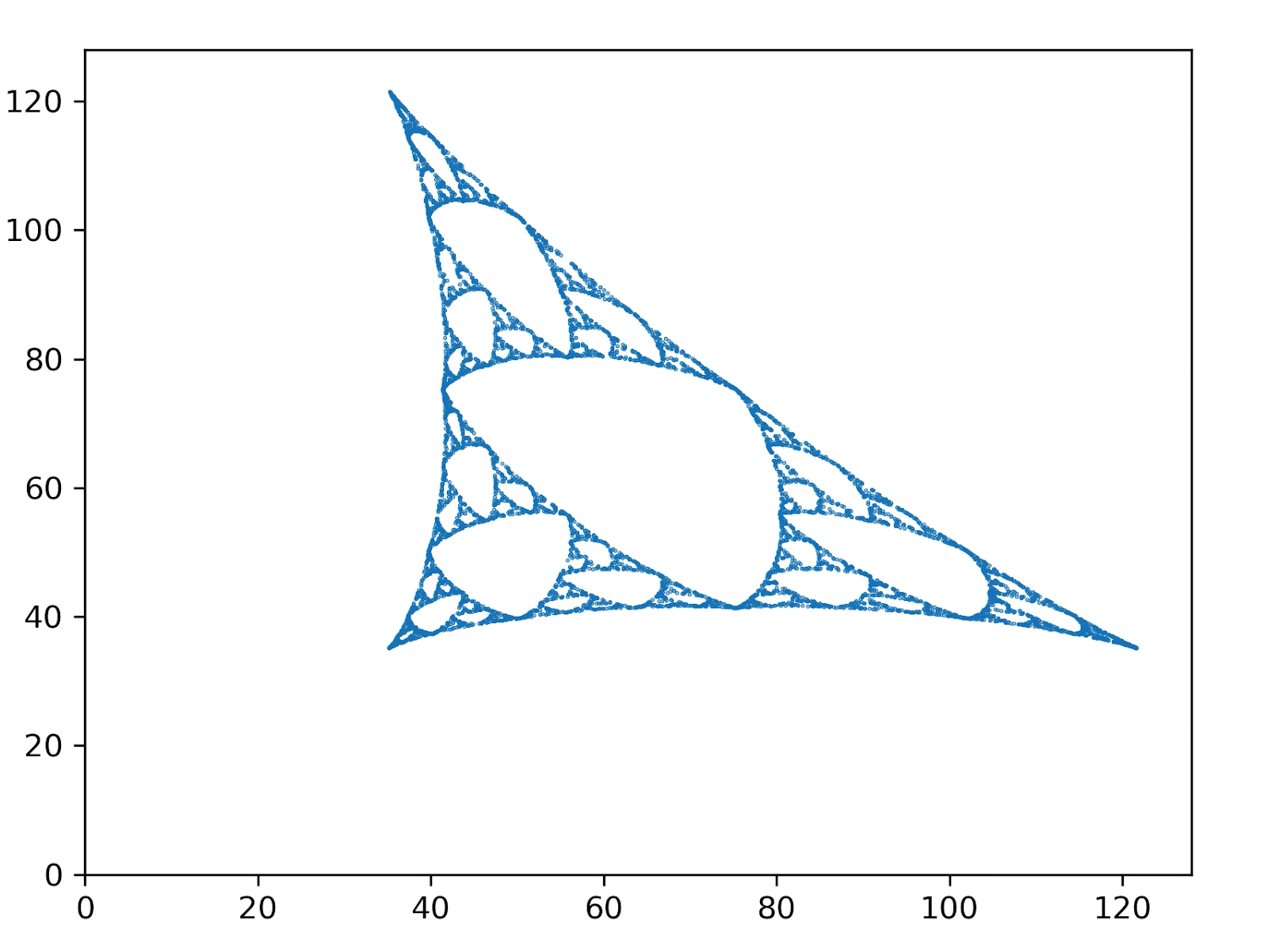
(Ignore the skew, David's still fiddling with the projection into 2D. The important noticeable part is the absence of "overlap" between the three copies of the main shape, compared to the fractal from the post.)
Specifically, each point in that visual corresponds to a distribution for some value of the observed symbols . The image itself is of the points on the probability simplex. From looking at a couple of Crutchfield papers, it sounds like that's what the MSP is supposed to be.
The update equations are:
with given by the transition probabilities, given by the observation probabilities, and a normalizer. We generate the image above by running initializing some random distribution , then iterating the equations and plotting each point.
Off the top of your head, any idea what might account for the mismatch (other than a bug in our code, which we're already checking)? Are we calculating the right thing, i.e. values of ? Are the transition and observation probabilities from the graphic in the post the same parameters used to generate the fractal? Is there some thing which people always forget to account for when calculating these things?
Can you elaborate on how the fractal is an artifact of how the data is visualized?
I don't know the details of the MSP, but my current understanding is that it's a general way of representing stochastic processes, and the MSP representation typically looks quite fractal. If we take two approximately-the-same stochastic processes, then they'll produce visually-similar fractals.
But the "fractal-ness" is mostly an artifact of the MSP as a representation-method IIUC; the stochastic process itself is not especially "naturally fractal".
(As I said I don't know the details of the MSP very well; my intuition here is instead coming from some background knowledge of where fractals which look like those often come from, specifically chaos games.)
That there is a linear 2d plane in the residual stream that when you project onto it you get that same fractal seems highly non-artifactual, and is what we were testing.
A thing which is highly cruxy for me here, which I did not fully understand from the post: what exactly is the function which produces the fractal visual from the residual activations? My best guess from reading the post was that the activations are linearly regressed onto some kind of distribution, and then the distributions are represented in a particular way which makes smooth sets of distributions look fractal. If there's literally a linear projection of the residual stream into two dimensions which directly produces that fractal, with no further processing/transformation in between "linear projection" and "fractal", then I would change my mind about the fractal structure being mostly an artifact of the visualization method.
[EDIT: I no longer endorse this response, see thread.]
(This comment is mainly for people other than the authors.)
If your reaction to this post is "hot damn, look at that graph", then I think you should probably dial back your excitement somewhat. IIUC the fractal structure is largely an artifact of how the data is visualized, which means the results visually look more striking than they really are.
It is still a cool piece of work, and the visuals are beautiful. The correct amount of excitement is greater than zero.
Yup. Also, I'd add that entropy in this formulation increases exactly when more than one macrostate at time maps to the same actually-realized macrostate at time , i.e. when the macrostate evolution is not time-reversible.
This post was very specifically about a Boltzmann-style approach. I'd also generally consider the Gibbs/Shannon formula to be the "real" definition of entropy, and usually think of Boltzmann as the special case where the microstate distribution is constrained uniform. But a big point of this post was to be like "look, we can get surprisingly a lot (though not all) of thermo/stat mech even without actually bringing in any actual statistics, just restricting ourselves to the Boltzmann notion of entropy".
Meta: this comment is decidedly negative feedback, so needs the standard disclaimers. I don't know Ethan well, but I don't harbor any particular ill-will towards him. This comment is negative feedback about Ethan's skill in choosing projects in particular, I do not think others should mimic him in that department, but that does not mean that I think he's a bad person/researcher in general. I leave the comment mainly for the benefit of people who are not Ethan, so for Ethan: I am sorry for being not-nice to you here.
When I read the title, my first thought was "man, Ethan Perez sure is not someone I'd point to as an examplar of choosing good projects".
On reading the relevant section of the post, it sounds like Ethan's project-selection method is basically "forward-chain from what seems quick and easy, and also pay attention to whatever other people talk about". Which indeed sounds like a recipe for very mediocre projects: it's the sort of thing you'd expect a priori to reliably produce publications and be talked about, but have basically-zero counterfactual impact. These are the sorts of projects where someone else would likely have done something similar regardless, and it's not likely to change how people are thinking about things or building things; it's just generally going to add marginal effort to the prevailing milieu, whatever that might be.
From reading, I imagined a memory+cache structure instead of being closer to "cache all the way down".
Note that the things being cached are not things stored in memory elsewhere. Rather, they're (supposedly) outputs of costly-to-compute functions - e.g. the instrumental value of something would be costly to compute directly from our terminal goals and world model. And most of the values in cache are computed from other cached values, rather than "from scratch" - e.g. the instrumental value of X might be computed (and then cached) from the already-cached instrumental values of some stuff which X costs/provides.
Coherence of Caches and Agents goes into more detail on that part of the picture, if you're interested.
Very far through the graph representing the causal model, where we start from one or a few nodes representing the immediate observations.
One obvious guess there would be that the factorization structure is exploited, e.g. independence and especially conditional independence/DAG structure. And then a big question is how distributions of conditionally independent latents in particular end up embedded.