All of Adam Jermyn's Comments + Replies
There is Dario's written testimony before Congress, which mentions existential risk as a serious possibility: https://www.judiciary.senate.gov/imo/media/doc/2023-07-26_-_testimony_-_amodei.pdf
He also signed the CAIS statement on x-risk: https://www.safe.ai/work/statement-on-ai-risk
He does start out by saying he thinks & worries a lot about the risks (first paragraph):
I think and talk a lot about the risks of powerful AI. The company I’m the CEO of, Anthropic, does a lot of research on how to reduce these risks... I think that most people are underestimating just how radical the upside of AI could be, just as I think most people are underestimating how bad the risks could be.
He then explains (second paragraph) that the essay is meant to sketch out what things could look like if things go well:
...In this essay I try to sketch o
My current belief is that this essay is optimized to be understandable by a much broader audience than any comparable public writing from Anthropic on extinction-level risk.
For instance, did you know that the word 'extinction' doesn't appear anywhere on Anthropic's or Dario's websites? Nor do 'disempower' or 'disempowerment'. The words 'existential' and 'existentially' only come up three times: when describing the work of an external organization (ARC), in one label in a paper, and one mention in the Constitutional AI. In its place they always talk a...
One day a mathematician doesn’t know a thing. The next day they do. In between they made no observations with their senses of the world.
It’s possible to make progress through theoretical reasoning. It’s not my preferred approach to the problem (I work on a heavily empirical team at a heavily empirical lab) but it’s not an invalid approach.
In Towards Monosemanticity we also did a version of this experiment, and found that the SAE was much less interpretable when the transformer weights were randomized (https://transformer-circuits.pub/2023/monosemantic-features/index.html#appendix-automated-randomized).
...Second, the measure of “features per dimension” used by Elhage et al. (2022) might be misleading. See the paper for details of how they arrived at this quantity. But as shown in the figure above, “features per dimension” is defined as the Frobenius norm of the weight matrix before the layer divided by the number of neurons in the layer. But there is a simple sanity check that this doesn’t pass. In the case of a ReLU network without bias terms, multiplying a weight matrix by a constant factor will cause the “features per dimension” to be increased by that
I think there’s tons of low-hanging fruit in toy model interpretability, and I expect at least some lessons from at least some such projects to generalize. A lot of the questions I’m excited about in interpretability are fundamentally accessible in toy models, like “how do models trade off interference and representational capacity?”, “what priors do MLP’s have over different hypotheses about the data distribution?”, etc.
A thing I really like about the approach in this paper is that it makes use of a lot more of the model's knowledge of human values than traditional RLHF approaches. Pretrained LLM's already know a ton of what humans say about human values, and this seems like a much more direct way to point models at that knowledge than binary feedback on samples.
How does this correctness check work?
I usually think of gauge freedom as saying “there is a family of configurations that all produce the same observables”. I don’t think that gives a way to say some configurations are correct/incorrect. Rather some pairs of configurations are equivalent and some aren’t.
That said, I do think you can probably do something like the approach described to assign a label to each equivalence class of configurations and do your evolution in that label space, which avoids having to pick a gauge.
How would you classify optimization shaped like "write a program to solve the problem for you". It's not directly searching over solutions (though the program you write might). Maybe it's a form of amortized optimization?
Separately: The optimization-type distinction clarifies a circle I've run around talking about inner optimization with many people, namely "Is optimization the same as search, or is search just one way to get optimization?" And I think this distinction gives me something to point to in saying "search is one way to get (direct) optimization, but there are other kinds of optimization".
I might be totally wrong here, but could this approach be used to train models that are more likely to be myopic (than e.g. existing RL reward functions)? I'm thinking specifically of the form of myopia that says "only care about the current epoch", which you could train for by (1) indexing epochs, (2) giving the model access to its epoch index, (3) having the reward function go negative past a certain epoch, (4) giving the model the ability to shutdown. Then you could maybe make a model that only wants to run for a few epochs and then shuts off, and maybe that helps avoid cross-epoch optimization?
That's definitely a thing that can happen.
I think the surgeon can always be made ~arbitrarily powerful, and the trick is making it not too powerful/trivially powerful (in ways that e.g. preclude the model from performing well despite the surgeon's interference).
So I think the core question is: are there ways to make a sufficiently powerful surgeon which is also still defeasible by a model that does what we want?
A trick I sometimes use, related to this post, is to ask whether my future self would like to buy back my present time at some rate. This somehow makes your point about intertemporal substitution more visceral for me, and makes it easier to say "oh yes this thing which is pricier than my current rate definitely makes sense at my plausible future rate".
In fact, it's not 100% clear that AI systems could learn to deceive and manipulate supervisors even if we deliberately tried to train them to do it. This makes it hard to even get started on things like discouraging and detecting deceptive behavior.
Plausibly we already have examples of (very weak) manipulation, in the form of models trained with RLHF saying false-but-plausible-sounding things, or lying and saying they don't know something (but happily providing that information in different contexts). [E.g. ChatGPT denies having information about how to build nukes, but will also happily tell you about different methods for Uranium isotope separation.]
Could it be that Chris's diagram gets recovered if the vertical scale is "total interpretable capabilities"? Like maybe tiny transformers are more interpretable in that we can understand ~all of what they're doing, but they're not doing much, so maybe it's still the case that the amount of capability we can understand has a valley and then a peak at higher capability.
That's a good point: it definitely pushes in the direction of making the model's internals harder to adversarially attack. I do wonder how accessible "encrypted" is here versus just "actually robust" (which is what I'm hoping for in this approach). The intuition here is that you want your model to be able to identify that a rogue thought like "kill people" is not a thing to act on, and that looks like being robust.
Roughly, I think it’s hard to construct a reward signal that makes models answer questions when they know the answers and say they don’t know when they don’t know. Doing that requires that you are always able to tell what the correct answer is during training, and that’s expensive to do. (Though Eg Anthropic seems to have made some progress here: https://arxiv.org/abs/2207.05221).
This post introduces the concept of a "cheerful price" and (through examples and counterexamples) narrows it down to a precise notion that's useful for negotiating payment. Concretely:
- Having "cheerful price" in your conceptual toolkit means you know you can look for the number at which you are cheerful (as opposed to "the lowest number I can get by on", "the highest number I think they'll go for", or other common strategies). If you genuinely want to ask for an amount that makes you cheerful and no more, knowing that such a number might exist at all is u
I found this post a delightful object-level exploration of a really weird phenomenon (the sporadic occurrence of the "tree" phenotype among plants). The most striking line for me was:
Most “fruits” or “berries” are not descended from a common “fruit” or “berry” ancestor. Citrus fruits are all derived from a common fruit, and so are apples and pears, and plums and apricots – but an apple and an orange, or a fig and a peach, do not share a fruit ancestor.
What is even going on here?!
On a meta-level my takeaway was to be a bit more humble in saying what complex/evolved/learned systems should/shouldn't be capable of/do.
This problem is not neglected, and it is very unclear how any insight into why SGD works wouldn’t be directly a capabilities contribution.
I strongly disagree! AFAICT SGD works so well for capabilities that interpretability/actually understanding models/etc. is highly neglected and there's low-hanging fruit all over the place.
I agree with both of your rephrasings and I think both add useful intuition!
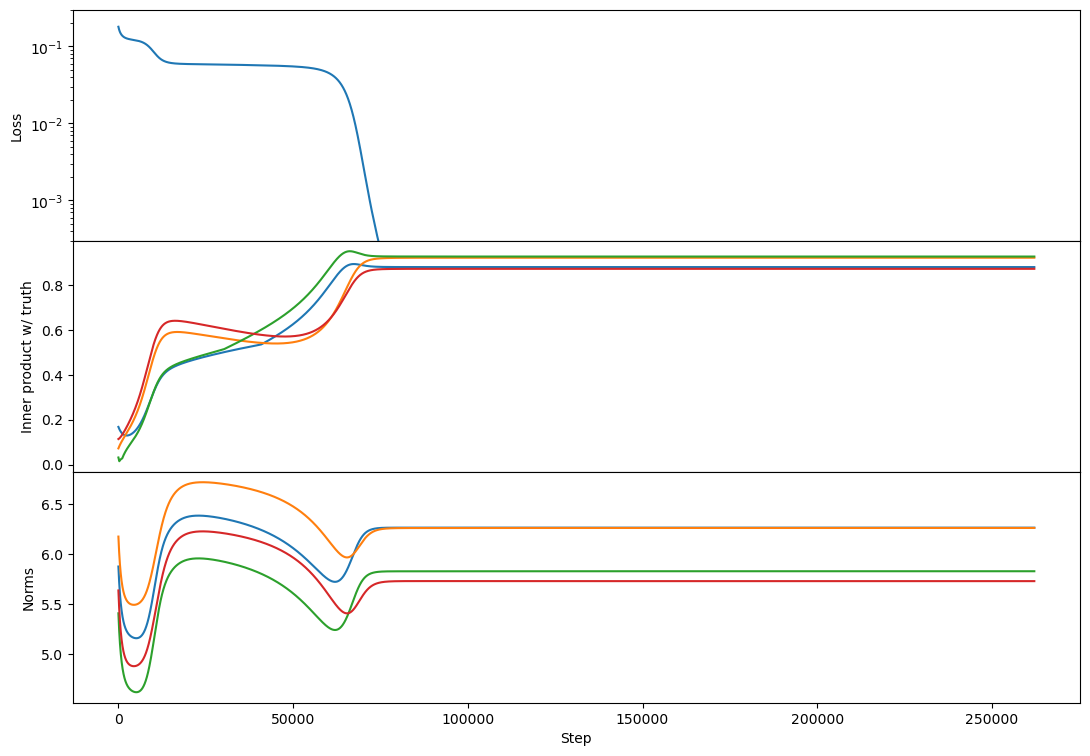
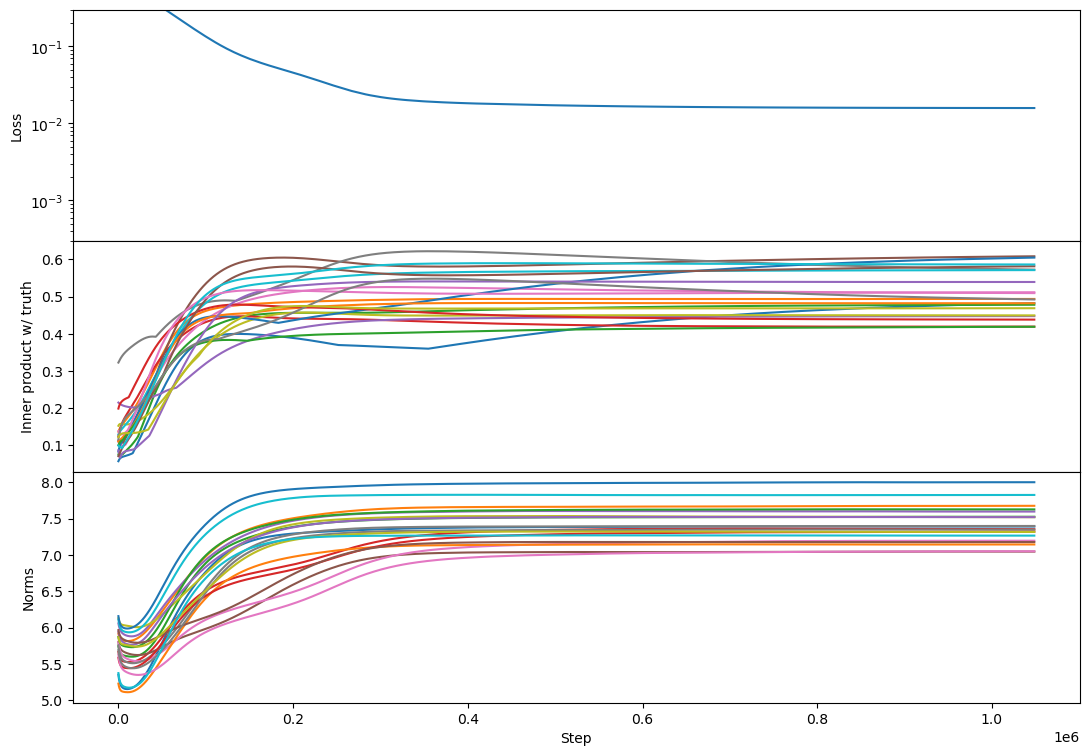
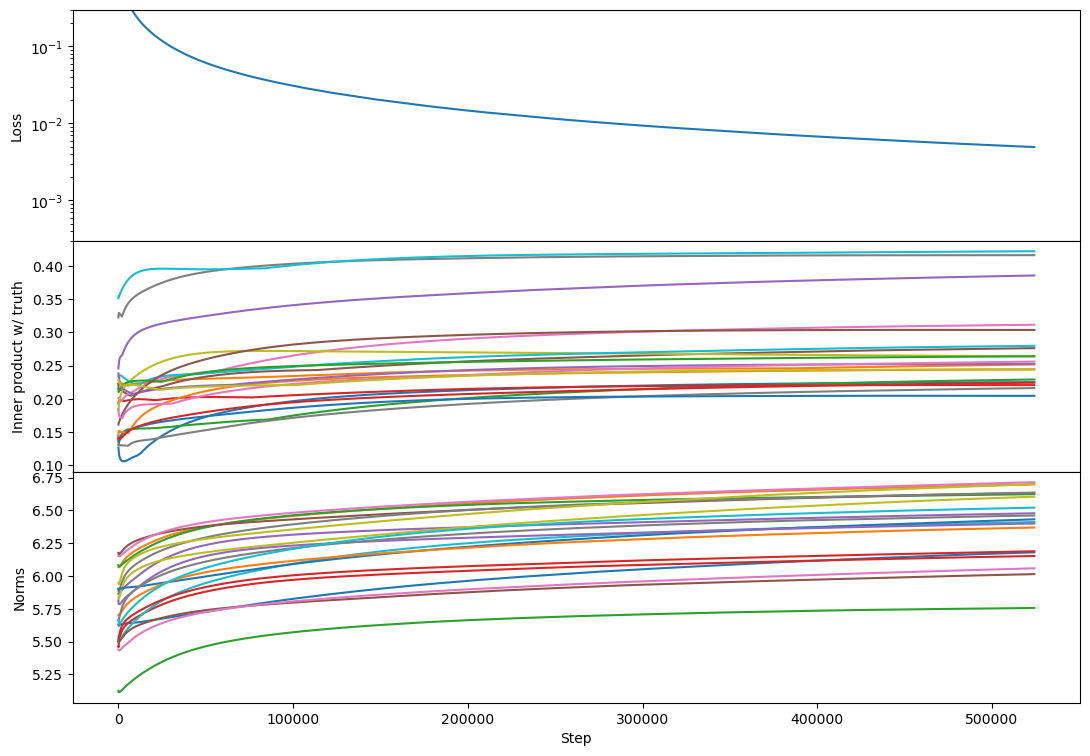
Regarding rank 2, I don't see any difference in behavior from rank 1 other than the "bump" in alignment that Lawrence mentioned. Here's an example:
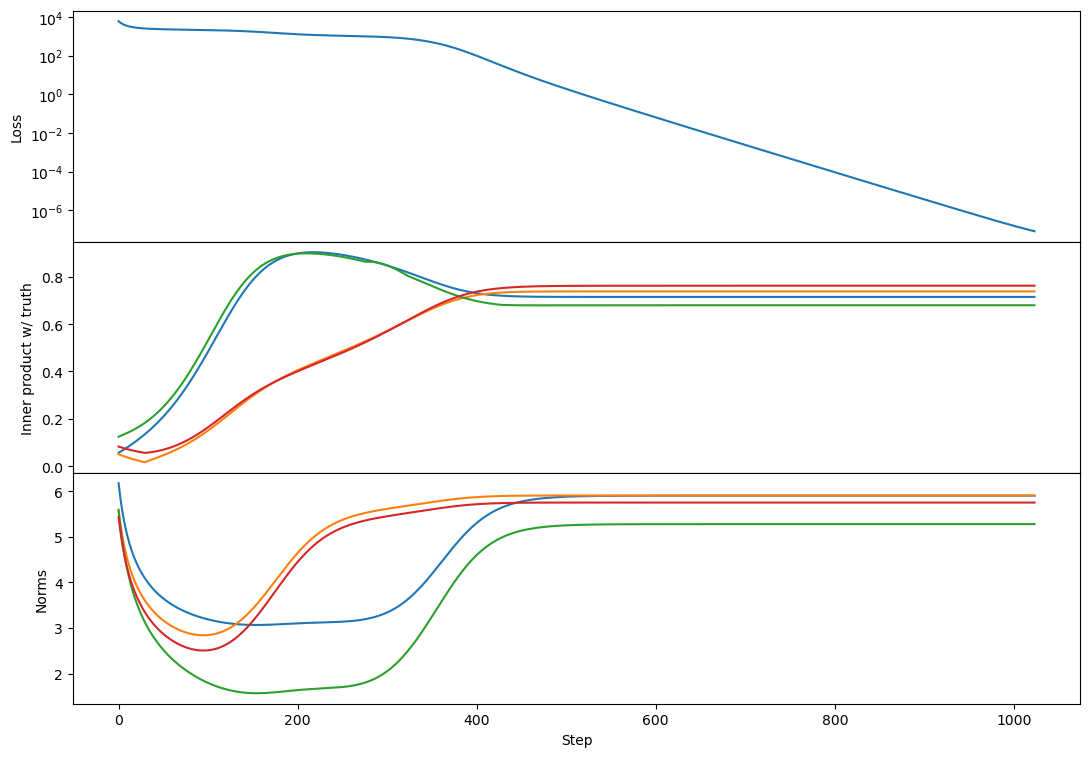
This doesn't happen in all rank-2 cases but is relatively common. I think usually each vector grows primarily towards 1 or the other target. If two vectors grow towards the same target then you get this bump where one of them has to back off and align more towards a different target [at least that's my current understanding, see my reply...
I don't, but here's my best guess: there's a sense in which there's competition among vectors for which learned vectors capture which parts of the target span.
As a toy example, suppose there are two vectors, and , such that the closest target vector to each of these at initialization is . Then both vectors might grow towards . At some point is represented enough in the span, and it's not optimal for two vectors to both play the role of representing , so it becomes optimal for at least one of them to s...
This is really interesting! One extension that comes to mind: SVD will never recover a Johnson-Lindenstrauss packing, because SVD can only return as many vectors as the rank of the relevant matrix. But you can do sparse coding to e.g. construct an overcomplete basis of vectors such that typical samples are sparse combinations of those vectors. Have you tried/considered trying something like that?
Do you have results with noisy inputs?
Nope! Do you have predictions for what noise might do here?
The negative bias lines up well with previous sparse coding implementations: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=JHuo2D0AAAAJ&citation_for_view=JHuo2D0AAAAJ:u-x6o8ySG0sC
Oooo I'll definitely take a look. This looks very relevant.
...Note that in that research, the negative bias has a couple of meanings/implications:
- It should correspond to the noise level in your input channel.
- Higher negative biases directly contribute to
Thanks for these thoughts!
Although it would be useful to have the plotting code as well, if that's easy to share?
Sure! I've just pushed the plot helper routines we used, as well as some examples.
...I agree that N (true feature dimension) > d (observed dimension), and that sparsity will be high, but I'm uncertain whether the other part of the regime (that you don't mention here), that k (model latent dimension) > N, is likely to be true. Do you think that is likely to be the case? As an analogy, I think the intermediate feature dimensions in MLP layers i
Sorry for my confusion about something so silly, but shouldn't the following be "when
Oh you're totally right. And k=1 should be k=d there. I'll edit in a fix.
I'm also a bit confused about why we can think of as representing "which moment of the interference distribution we care about."
It's not precisely which moment, but as we vary the moment(s) of interest vary monotonically.
...Perhaps some of my confusion here stems from the fact that it seems to me that the optimal number of subspaces, , is an increasing fun
I like the distinction between implementing the results of acausal decision theories and explicitly performing the reasoning involved. That seems useful to have.
The taxes example I think is more complicated: at some scale I do think that governments have some responsiveness to their tax receipts (e.g. if there were a surprise doubling of tax receipts governments might well spend more). It's not a 1:1 relation, but there's definitely a connection.
I can also confirm (I have a 3:1 match).