All of anonymousaisafety's Comments + Replies
i.e. splitting hairs and swirling words around to create a perpetual motte-and-bailey fog that lets him endlessly nitpick and retreat and say contradictory things at different times using the same words, and pretending to a sort of principle/coherence/consistency that he does not actually evince.
Yeah, almost like splitting hairs around whether making the public statement "I now categorize Said as a liar" is meaningfully different than "Said is a liar".
Or admonishing someone for taking a potshot at you when they said
...However, I suspect that Duncan won'
On reflection, I do think both Duncan and Said are demonstrating a significant amount of hair-splitting and less consistent, clear communication than they seem to think. That's not necessarily bad in and of itself - LW can be a place for making fine distinctions and working out unclear thoughts, when there's something important there.
It's really just using them as the basis for a callout and fuel for an endless escalation-spiral when they become problematic.
When I think about this situation from both Duncan and Said's point of views to the best of my abili...
Yes, I have read your posts.
I note that in none of them did you take any part of the responsibility for escalating the disagreement to its current level of toxicity.
You have instead pointed out Said's actions, and Said's behavior, and the moderators lack of action, and how people "skim social points off the top", etc.
Anonymousaisafety, with respect, and acknowledging there's a bit of the pot calling the kettle black intrinsic in my comment here, I think your comments in this thread are also functioning to escalate the conflict, as was clone of saturn's top-level comment.
The things your comments are doing that seem to me escalatory include making an initially inaccurate criticism of Duncan ("your continued statements on this thread that you've done nothing wrong"), followed by a renewed criticism of Duncan that doesn't contain even a brief acknowledgement or apology for...
@Duncan_Sabien I didn't actually upvote @clone of saturn's post, but when I read it, I found myself agreeing with it.
I've read a lot of your posts over the past few days because of this disagreement. My most charitable description of what I've read would be "spirited" and "passionate".
You strongly believe in a particular set of norms and want to teach everyone else. You welcome the feedback from your peers and excitedly embrace it, insofar as the dot product between a high-dimensional vector describing your norms and a similar vector describing the critici...
Sometimes when you work at a large tech-focused company, you'll be pulled into a required-but-boring all-day HR meeting to discuss some asinine topic like "communication styles".
If you've had the misfortune fun of attending one of those meetings, you might remember that the topic wasn't about teaching a hypothetically "best" or "optimal" communication style. The goal was to teach employees how to recognize when you're speaking to someone with a different communication style, and then how to tailor your understanding of what they're saying with respect to t...
It seems to me that humans are more coherent and consequentialist than other animals. Humans are not perfectly coherent, but the direction is towards more coherence.
This isn't a universally held view. Someone wrote a fairly compelling argument against it here: https://sohl-dickstein.github.io/2023/03/09/coherence.html
We don't do any of these things for diffusion models that output images, and yet these diffusion models manage to be much smaller than models that output words, while maintaining an even higher level of output quality. What is it about words that makes the task different?
I'm not sure that "even higher level of output quality" is actually true, but I recognize that it can be difficult to judge when an image generation model has succeeded. In particular, I think current image models are fairly bad at specifics in much the same way as early language models.&n...
Yes, it's my understanding that OpenAI did this for GPT-4. It's discussed in the system card PDF. They used early versions of GPT-4 to generate synthetic test data and also as an evaluator of GPT-4 responses.
First, when we say "language model" and then we talk about the capabilities of that model for "standard question answering and factual recall tasks", I worry that we've accidentally moved the goal posts on what a "language model" is.
Originally, a language model was a stochastic parrot. They were developed to answer questions like "given these words, what comes next?" or "given this sentence, with this unreadable word, what is the most likely candidate?" or "what are the most common words?"[1] It was not a problem that required deep learning.
Then...
I suspect it is a combination of #3 and #5.
Regarding #5 first, I personally think that language models are being trained wrong. We'll get OoM improvements when we stop randomizing the examples we show to models during training, and instead provide examples in a structured curriculum.
This isn't a new thought, e.g. https://arxiv.org/abs/2101.10382
To be clear, I'm not saying that we must present easy examples first and then harder examples later. While that is what has been studied in the literature, I think we'd actually get better behavior by trying to orde...
I realize that my position might seem increasingly flippant, but I really think it is necessary to acknowledge that you've stated a core assumption as a fact.
Alignment doesn't run on some nega-math that can't be cast as an optimization problem.
I am not saying that the concept of "alignment" is some bizarre meta-physical idea that cannot be approximated by a computer because something something human souls etc, or some other nonsense.
However the assumption that "alignment is representable in math" directly implies "alignment is representable as an optimizat...
I wasn't intending for a metaphor of "biomimicry" vs "modernist".
(Claim 1) Wings can't work in space because there's no air. The lack of air is a fundamental reason for why no wing design, no matter how clever it is, will ever solve space travel.
If TurnTrout is right, then the equivalent statement is something like (Claim 2) "reward functions can't solve alignment because alignment isn't maximizing a mathematical function."
The difference between Claim 1 and Claim 2 is that we have a proof of Claim 1, and therefore don't bother debating it anymore, wh...
To some extent, I think it's easy to pooh-pooh finding a flapping wing design (not maximally flappy, merely way better than the best birds) when you're not proposing a specific design for building a flying machine that can go to space. Not in the tone of "how dare you not talk about specifics," but more like "I bet this chemical propulsion direction would have to look more like birds when you get down to brass tacks."
(1) The first thing I did when approaching this was think about how the message is actually transmitted. Things like the preamble at the start of the transmission to synchronize clocks, the headers for source & destination, or the parity bits after each byte, or even things like using an inversed parity on the header so that it is possible to distinguish a true header from bytes within a message that look like a header, and even optional checksum calculations.
(2) I then thought about how I would actually represent the data so it wasn't just tradi
My understanding of faul_sname's claim is that for the purpose of this challenge we should treat the alien sensor data output as an original piece of data.
In reality, yes, there is a source image that was used to create the raw data that was then encoded and transmitted. But in the context of the fiction, the raw data is supposed to represent the output of the alien sensor, and the claim is that the decompressor + payload is less than the size of just an ad-hoc gzipping of the output by itself. It's that latter part of the claim that I'm skeptical to
Which question are we trying to answer?
- Is it possible to decode a file that was deliberately constructed to be decoded, without a priori knowledge? This is vaguely what That Alien Message is about, at least in the first part of the post where aliens are sending a message to humanity.
- Is it possible to decode a file that has an arbitrary binary schema, without a priori knowledge? This is the discussion point that I've been arguing over with regard to stuff like decoding CAMERA raw formats, or sensor data from a hardware/software system. This is also the area
It depends on what you mean by "didn't work". The study described is published in a paper only 16 pages long. We can just read it: http://web.mit.edu/curhan/www/docs/Articles/biases/67_J_Personality_and_Social_Psychology_366,_1994.pdf
First, consider the question of, "are these predictions totally useless?" This is an important question because I stand by my claim that the answer of "never" is actually totally useless due to how trivial it is.
...Despite the optimistic bias, respondents' best estimates were by no means devoid of information: The predicted compl
Right. I think I agree with everything you wrote here, but here it is again in my own words:
In communicating with people, the goal isn't to ask a hypothetically "best" question and wonder why people don't understand or don't respond in the "correct" way. The goal is to be understood and to share information and acquire consensus or agree on some negotiation or otherwise accomplish some task.
This means that in real communication with real people, you often need to ask different questions to different people to arrive at the same information, or phrase some ...
Isn't this identical to the proof for why there's no general algorithm for solving the Halting Problem?
The Halting Problem asks for an algorithm A(S, I) that when given the source code S and input I for another program will report whether S(I) halts (vs run forever).
There is a proof that says A does not exist. There is no general algorithm for determining whether an arbitrary program will halt. "General" and "arbitrary" are important keywords because it's trivial to consider specific algorithms and specific programs and say, yes, we can determine that this...
If we look at the student answers, they were off by ~7 days, or about a 14% error from the actual completion time.
The only way I can interpret your post is that you're suggesting all of these students should have answered "never".
I'm not convinced that "never" just didn't occur to them because they were insufficiently motivated to give a correct answer.
How far off is "never" from the true answer of 55.5 days?
It's about infinitely far off. It is an infinitely wrong answer. Even if a project ran 1000% over every worst-case pessimistic schedule, any finite pr...
Is the concept of "murphyjitsu" supposed to be different than the common exercise known as a premortem in traditional project management? Or is this just the same idea, but rediscovered under a different name, exactly like how what this community calls a "double crux" is just the evaporating cloud, which was first described in the 90s.
If you've heard of a postmortem or possibly even a retrospective, then it's easy to guess what a premortem is. I cannot say the same for "murphyjitsu".
I see that premortem is even referenced in the "further resour...
I invented the term. I can speak to this.
For one thing, I think I hadn't heard of the premortem when I created the term "murphyjitsu" and the basic technique. I do think there's a slight difference, but it's minor enough that had I known about premortems then I might have just used that term.
Murphyjitsu showed up as a cute name for a process I had created to pragmatically counter planning fallacy thinking in my own mind. Part of the inspiration was from when Anna and Eliezer had created the "sunk cost kata", which was more like a bundle of mental tricks fo...
The core problem remains computational complexity.
Statements like "does this image look reasonable" or saying "you pay attention to regularities in the data", or "find the resolution by searching all possible resolutions" are all hiding high computational costs behind short English descriptions.
Let's consider the case of a 1280x720 pixel image.
That's the same as 921600 pixels.
How many bytes is that?
It depends. How many bytes per pixel?[1] In my post, I explained there could be 1-byte-per-pixel grayscale, or perhaps 3-bytes-per-pixel RGB us...
Why do you say that Kolmogorov complexity isn't the right measure?
most uniformly sampled programs of equal KC that produce a string of equal length.
...
"typical" program with this KC.
I am worried that you might have this backwards?
Kolmogorov complexity describes the output, not the program. The output file has low Kolmogorov complexity because there exists a short computer program to describe it.
I have mixed thoughts on this.
I was delighted to see someone else put forth an challenge, and impressed with the amount of people who took it up.
I'm disappointed though that the file used a trivial encoding. When I first saw the comments suggesting it was just all doubles, I was really hoping that it wouldn't turn out to be that.
I think maybe where the disconnect is occurring is that in the original That Alien Message post, the story starts with aliens deliberately sending a message to humanity to decode, as this thread did here. It is explicitly described...
https://en.wikipedia.org/wiki/Kolmogorov_complexity
The fact that the program is so short indicates that the solution is simple. A complex solution would require a much longer program to specify it.
I gave this post a strong disagree.
Some thoughts for people looking at this:
- It's common for binary schemas to distinguish between headers and data. There could be a single header at the start of the file, or there could be multiple headers throughout the file with data following each header.
- There's often checksums on the header, and sometimes on the data too. It's common for the checksums to follow the respective thing being checksummed, i.e. the last bytes of the header are a checksum, or the last bytes after the data are a checksum. 16-bit and 32-bit CRCs are common.
- If the data represents
I’m not sure if your comment is disagreeing with any of this. It sounds like we’re on the same page about the fact that exact reasoning is prohibitively costly, and so you will be reasoning approximately, will often miss things, etc.
I agree. The term I've heard to describe this state is "violent agreement".
so in practice wrong conclusions are almost always due to a combination of both "not knowing enough" and “not thinking hard enough” / “not being smart enough.”
The only thing I was trying to point out (maybe more so for everyone else reading the com...
First, it only targeted Windows machines running an Microsoft SQL Server reachable via the public internet. I would not be surprised if ~70% or more theoretically reachable targets were not infected because they ran some other OS (e.g. Linux) or server software instead (e.g. MySQL). This page makes me think the market share was actually more like 15%, so 85% of servers were not impacted. By not impacted, I mean, "not actively contributing to the spread of the worm". They were however impacted by the denial-of-service caused by traffic from infected servers...
...This was actually a kind of fun test case for a priori reasoning. I think that I should have been able to notice the consideration denkenbgerger raised, but I didn't think of it. In fact when I stared reading his comment my immediate reaction was "this methodology is so simple, how could the equilibrium infiltration rate end up being relevant?" My guess would be that my a priori reasoning about AI is wrong in tons of similar ways even in "simple" cases. (Though obviously the whole complexity scale is shifted up a lot, since I've spent hundreds of hours thi
I deliberately tried to focus on "external" safety features because I assumed everyone else was going to follow the task-as-directed and give a list of "internal" safety features. I figured that I would just wait until I could signal-boost my preferred list of "internal" safety features, and I'm happy to do so now -- I think Lauro Langosco's list here is excellent and captures my own intuition for what I'd expect from a minimally useful AGI, and that list does so in probably a clearer / easier to read manner than what I would have written. It's very simila...
We can even consider the proposed plan (add a 2nd hose and increase the price by $20) in the context of an actual company.
The proposed plan does not actually redesign the AC unit around the fact that we now have 2 hoses. It is "just" adding an additional hose.
Let's assume that the distribution of AC unit cooling effectively looks something like this graphic that I made in 3 seconds.
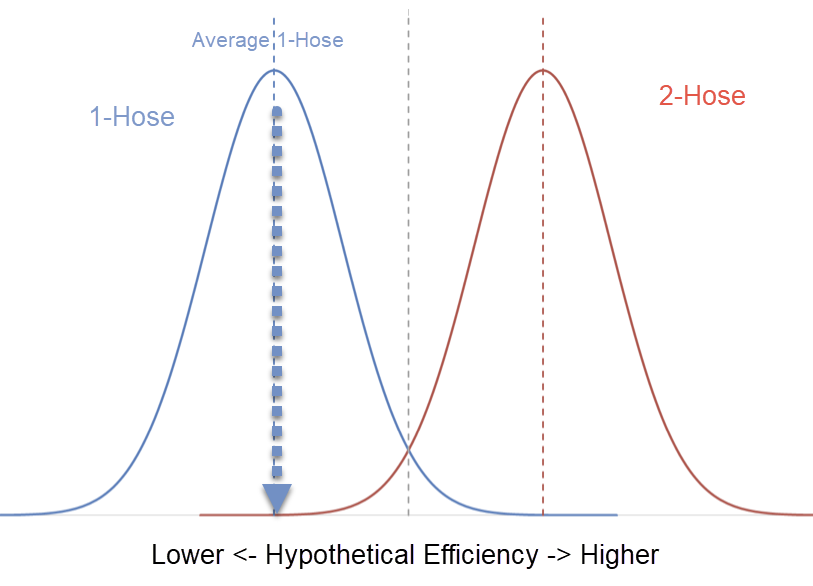
In this image, we are choosing to assume that yes, in fact, 2-hose units are more efficient on average than a 1-hose unit. We are also recognizing that perhaps there is so...
As a concrete example of rational one-hosing, here in the Netherlands it rarely gets hot enough that ACs are necessary, but when it does a bunch of elderly people die of heat stroke. Thus, ACs are expected to run only several days per year (so efficiency concerns are negligible), but having one can save your life.
I checked the biggest Dutch-only consumer-facing online retailer for various goods (bol.com). Unfortunately I looked before making a prediction for how many one-hose vs two-hose models they sell, but even conditional on me choosing to make a point...
I didn't even think to check this math, but now that I've gone and tried to calculate it myself, here's what I got:
| INSIDE | ΔINSIDE (CONTROL) | |||
| AVERAGE OUTSIDE | 86.5 | |||
| AVERAGE ONE HOSE Δ | 19.65 | 66.85 | 6.55 | |
| AVERAGE TWO HOSE Δ | 22.45 | 64.05 | 9.35 | |
| CONTROL Δ | 13.1 | 73.4 | ||
| 1.42 | ΔTWO/ΔONE |
EDIT: I see the issue. The parent post says that the control test was done at evening, where the temperature was 82 F. So it's not even comparable at all, imo.
I'll edit the range, and note that "uncomfortably hot" is my opinion. Rest of my analysis / rant still applies. In fact, in your case, you don't need need the AC unit at all, since you'd be fine with the control temperature.
I take fault with your primary conclusion, for the same reasons I gave in the first thread:
- You claim how little adding a 2nd hose would impact the system, without analyzing the actual constraints that apply to engineers building a product that must be shipped & distributed
- You still neglect the existence of insulating wraps for the hose which do improve efficiency, but are also not sold with the single-hose AC system, which lends evidence to my first point -- companies are aware of small cost items that improve AC system efficiency, but do not include t
... companies are aware of small cost items that improve AC system efficiency, but do not include them with the AC by default, suggesting that there is an actual price point / consumer market / confounding issue at play that prevents them doing so
Or it suggests that consumers would mostly not notice the difference in a way which meaningfully increased sales, just like I claim happens with the single-hose vs two-hose issue. For instance, I believe an insulating wrap would not change the SEER rating (because IIRC the rating measurements don't involve the hos...
I really like this list because it does a great job of explicitly specifying the same behavior I was trying to vaguely gesture at in my list when I kept referring to AGI-as-a-contract-engineer.
Even your point about it doesn't have to succeed, it's ok for it to fail at a task if it can't reach it in some obvious, non-insane way -- that's what I'd expect from a contractor. The idea that an AGI would find that a task is generally impossible but identify a novel edge case that allows it to be accomplished with some ridiculous solution involving nanotech and th...
Oh, sorry, you're referring to this:
includes a distributed network of non-nuclear electromagnetic pulse emitters that will physically shut down any tech infrastructure appearing to be running rogue AI agents.
This just seems like one of those things people say, in the same vein as "melt all of the GPUs". I think that non-nuclear EMPs are still based on chemical warheads. I don't know if a "pulse emitter" is a thing that someone could build. Like I think what this sentence actually says is equivalent to saying
...includes a distributed network of non-nucle
Would you agree that if there were a system that could automatically (without humans) monitor for rogue AI, then that system is probably hackable?
I can't comment on this, because I have no idea what this system would even do, or what it would be looking for, or who would be running it.
What indicates a rogue AI? How is that differentiated from human hackers? How is that different from state-level actors like the NSA? How is it different from some white hat security researchers doing pen-testing in the wild for questionable reasons? What "behavior" is ...
I don't think that this TL;DR is particularly helpful.
People think attacks like Rowhammer are viable because security researchers keep releasing papers that say the attacks are viable.
If I posted 1 sentence and said "Rowhammer has too many limitations for it to be usable by an attacker", I'd be given 30 links to papers with different security researchers all making grandiose claims about how Rowhammer is totally a viable attack, which is why 8 years after the discovery of Rowhammer we've had dozens of security researchers reproduce the attack and 0 attacks...
I am only replying to the part of this post about hardware vulnerabilities.
Like, superhuman-at-security AGIs rewrote the systems to be formally unhackable even taking into account hardware vulnerabilities like Rowhammer that violate the logical chip invariants?
There are dozens of hardware vulnerabilities that exist primarily to pad security researcher's bibliographies.
Rowhammer, like all of these vulnerabilities, is viable if and only if the following conditions are met:
- You know the exact target hardware.
- You also know the exact target software, like the OS
I worry that the question as posed is already assuming a structure for the solution -- "the sort of principles you'd build into a Bounded Thing meant to carry out some single task or task-class and not destroy the world by doing it".
When I read that, I understand it to be describing the type of behavior or internal logic that you'd expect from an "aligned" AGI. Since I disagree that the concept of "aligning" an AGI even makes sense, it's a bit difficult for me to reply on those grounds. But I'll try to reply anyway, based on what I think is reasonable for ...
Only if we pretend that it's an unknowable question and that there's no way to look at the limitations of a 286 by asking about how much data it can reasonably process over a timescale that is relevant to some hypothetical human-capable task.
http://datasheets.chipdb.org/Intel/x86/286/datashts/intel-80286.pdf
The relevant question here is about data transfers (bus speed) and arithmetic operations (instruction sets). Let's assume the fastest 286 listed in this datasheet -- 12.5 MHz.
Let's consider a very basic task -- say, catching a ball thrown from 10-15 fee...
the rest of the field has come to regard Eliezer as largely correct
It seems possible to me that you're witnessing a selection bias where the part of the field who disagree with Eliezer don't generally bother to engage with him, or with communities around him.
It's possible to agree on ideas like "it is possible to create agent AGI" and "given the right preconditions, AGI could destroy a sizeable fraction of the human race", while at the same time disagreeing with nearly all of Eliezer's beliefs or claims on that same topic.
That in turn would lead to d...
Then I'm not sure what our disagreement is.
I gave the example of a Kalman filter in my other post. A Kalman filter is similar to recursive Bayesian estimation. It's computationally intensive to run for an arbitrary number of values due to how it scales in complexity. If you have a faster algorithm for doing this, then you can revolutionize the field of autonomous systems + self-driving vehicles + robotics + etc.
The fact that "in principle" information provides value doesn't matter, because the very example you gave of "updating belief networks" is ex...
I was describing a file that would fit your criteria but not be useful. I was explaining in bullet points all of the reasons why that file can't be decoded without external knowledge.
I think that you understood the point though, with your example of data from the Hubble Space Telescope. One caveat: I want to be clear that the file does not have to be all zeroes. All zeroes would violate your criteria that the data cannot be compressed to less than 10% of it's uncompressed size, since all zeroes can be trivially run-length-encoded.
But let's look at this any...
I'm deeply uncertain about how often it's worth litigating the implied meta-level concerns; I'm not at all uncertain that this way of expressing them was inappropriate. I don't want see sniping like this on LessWrong, and especially not in comment threads like this.
Consider this a warning to knock it off.