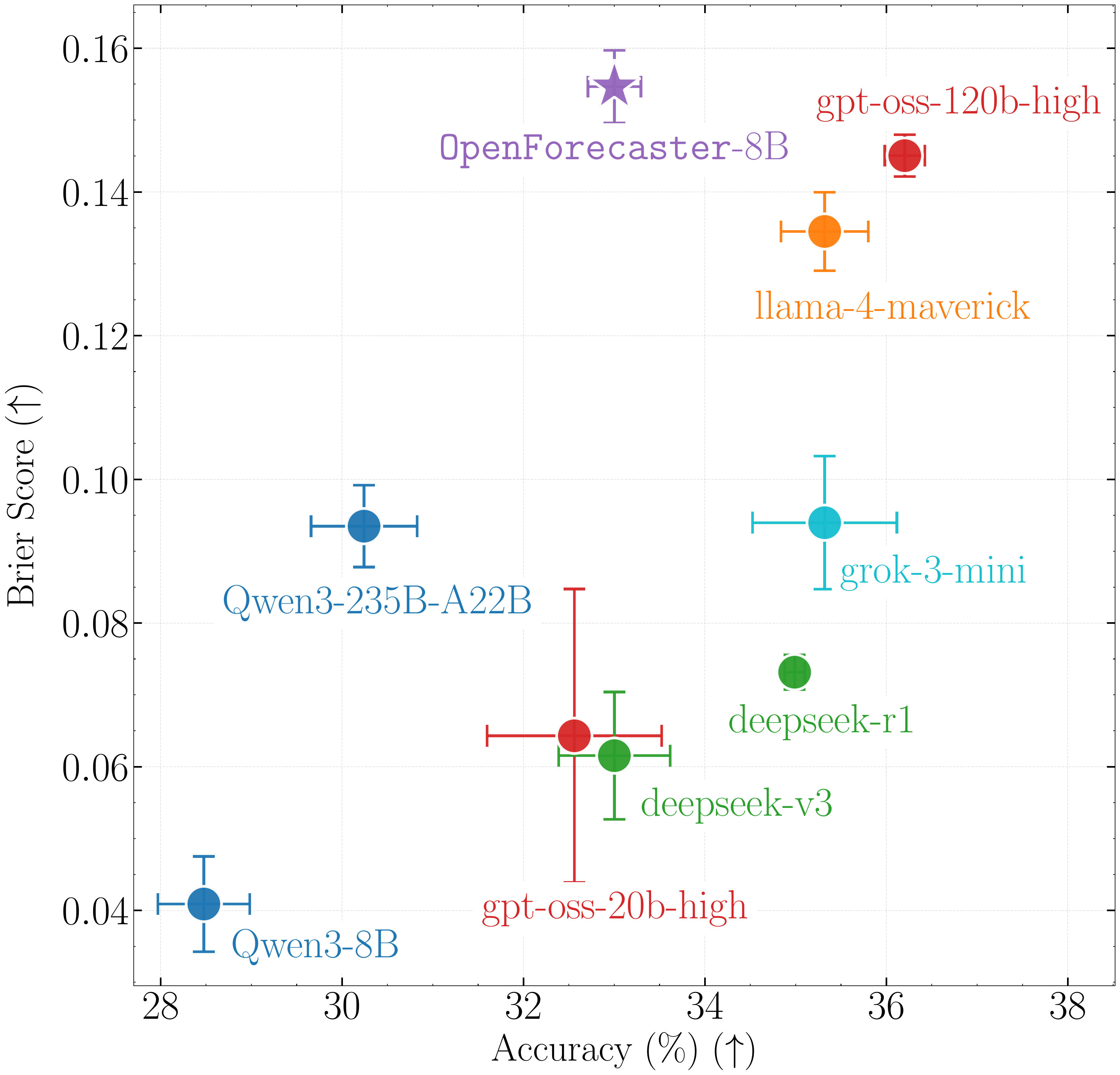
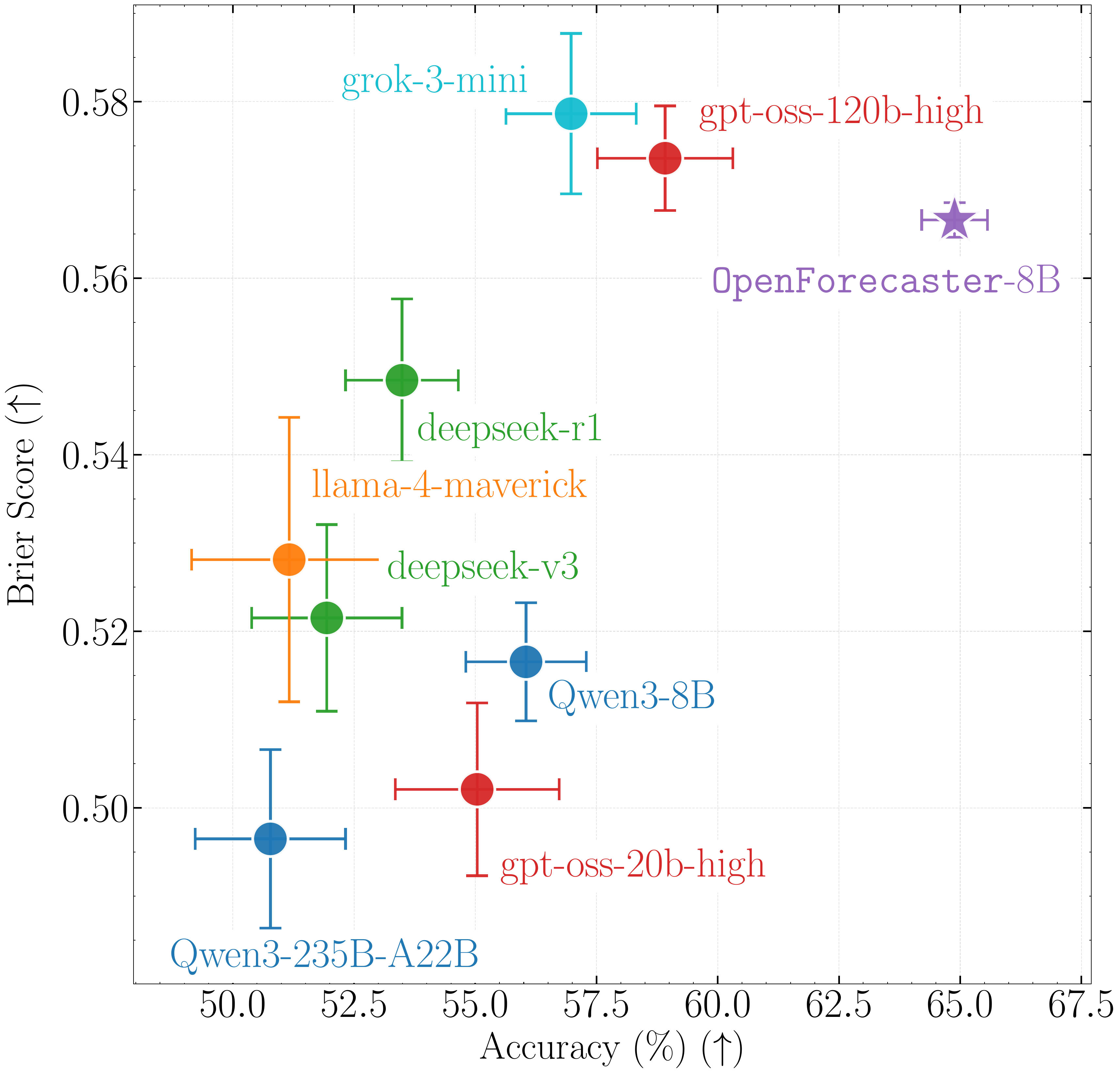
Epistemic Status: Exploratory. My current but-changing outlook with limited exploration & understanding for ~60-80hrs.
Acknowledgements: This post was written under Evan Hubinger’s direct guidance and mentorship as a part of the Stanford Existential Risks Institute ML Alignment Theory Scholars (MATS) program. Thanks to particlemania, Shashwat Goel and shawnghu for exciting discussions. They might not agree with some of the claims made here; all mistakes are mine.
Summary (TL;DR)
Goal: Understanding the inductive biases of Prosaic AI systems could be very informative towards creating a frame of safety problems and solutions. The proposal here is to generate an Evidence Set from current ML literature to model the potential inductive bias of Prosaic AGI.
Procedure: In this work, I collect evidence of inductive biases... (read 6236 more words →)