All of calef's Comments + Replies
Probably one of the core infohazards of postmodernism is that “moral rightness” doesn’t really exist outside of some framework. Asking about “rightness” of change is kind of a null pointer in the same way self-modifying your own reward centers can’t be straightforwardly phrased in terms of how your reward centers “should” feel about such rewiring.
For literally “just painting the road”, cost of materials of paint would be $50, yes. Doing it “right” in a way that’s indistinguishable from if the state of a California did it would almost certainly require experimenting with multiple paints, time spent measuring the intersection/planning out a new paint pattern that matches a similar intersection template, and probably even signage changes (removing the wrong signs (which is likely some kind of misdemeanor if not a felony)), and replacing the signage with the correct form. Even in opportunity costs loss, this is looking like tens of hours of work, and hundreds-to-thousands in costs of materials / required tools.
Agree in general. For this particular case, there don't appear to be any signs. https://goo.gl/maps/BZifQWTNCg3gdTaV7

You could probably implement this change for less than $5,000 and with minimal disruption to the intersection if you (for example) repainted the lines over night / put authoritative cones around the drying paint.
Who will be the hero we need?
Google doesn’t seem interested in serving large models until it has a rock solid solution to the “if you ask the model to say something horrible, it will oblige” problem.
The relevant sub-field of RL interested in this calls this “lifelong learning”, though I actually prefer your framing because it makes pretty crisp what we actually want.
I also think that solving this problem is probably closer to “something like a transformer and not very far away”, considering, e.g. memorizing transformers work (https://arxiv.org/abs/2203.08913)
I think the difficulty with answering this question is that many of the disagreements boil down to differences in estimates for how long it will take to operationalize lab-grade capabilities. Say we have intelligences that are narrowly human / superhuman on every task you can think of (which, for what it’s worth, I think will happen within 5-10 years). How long before we have self-replicating factories? Until foom? Until things are dangerously out of our control? Until GDP doubles within one year? In what order do these things happen? Etc. etc.
If I got...
Something worth reemphasizing for folks not in the field is that these benchmarks are not like usual benchmarks where you train the model on the task, and then see how good it does on a held-out set. Chinchilla was not explicitly trained on any of these problems. It’s typically given some context like: “Q: What is the southernmost continent? A: Antarctica Q: What is the continent north of Africa? A:” and then simply completes the prompt until a stop token is emitted, like a newline character.
And it’s performing above-average-human on these benchmarks.
That got people to, I dunno, 6 layers instead of 3 layers or something? But it focused attention on the problem of exploding gradients as the reason why deeply layered neural nets never worked, and that kicked off the entire modern field of deep learning, more or less.
This might be a chicken or egg thing. We couldn't train big neural networks until we could initialize them correctly, but we also couldn't train them until we had hardware that wasn't embarrassing / benchmark datasets that were nontrivial.
While we figured out empirical init strategies f...
For what it's worth, the most relevant difficult-to-fall-prey-to-Goodheartian-tricks measure is probably cross entropy validation loss, as shown in this figure from the GPT-3 paper:
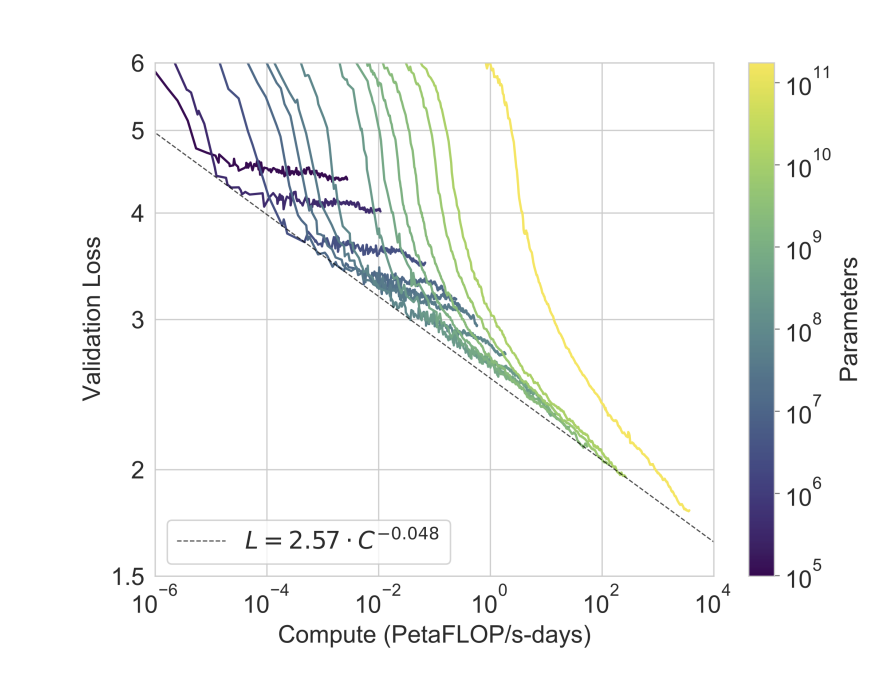
Serious scaling efforts are much more likely to emphasize progress here over Parameter Count Number Bigger clickbait.
Further, while this number will keep going down, we're going to crash into the entropy of human generated text at some point. Whether that's within 3 OOM or ten is anybody's guess, though.
By the standards of “we will have a general intelligence”, Moravec is wrong, but by the standards of “computers will be able to do anything humans can do”, Moravec’s timeline seems somewhat uncontroversially prescient? For essentially any task that we can define a measurable success metric, we more or less* know how to fashion a function approximator that’s as good as or better than a human.
*I’ll freely admit that this is moving the goalposts, but there’s a slow, boring path to “AGI” where we completely automate the pipeline for “generate a function appro...
Relatedly, do you consider [function approximators for basically everything becoming better with time] to also fail to be a good predictor of AGI timelines for the same reasons that compute-based estimates fail?
Obviously yes, unless you can take the metrics on which your graphs show steady progress and really actually locate AGI on them instead of just tossing out a shot-in-the-dark biological analogy to locate AGI on them.
In defense of shot-ness as a paradigm:
Shot-ness is a nice task-ambiguous interface for revealing capability that doesn’t require any cleverness from the prompt designer. Said another way, If you needed task-specific knowledge to construct the prompt that makes GPT-3 reveal it can do the task, it’s hard to compare “ability to do that task” in a task-agnostic way to other potential capabilities.
For a completely unrealistic example that hyperbolically gestures at what I mean: you could spend a tremendous amount of compute to come up with the magic password p...
Honestly, at this point, I don’t remember if it’s inferred or primary-sourced. Edited the above for clarity.
This is based on:
- The Q&A you mention
- GPT-3 not being trained on even one pass of its training dataset
- “Use way more compute” achieving outsized gains by training longer than by most other architectural modifications for a fixed model size (while you’re correct that bigger model = faster training, you’re trading off against ease of deployment, and models much bigger than GPT-3 become increasingly difficult to serve at prod. Plus, we know it’s about the same size, from the Q&A)
- Some experience with undertrained enormous language models underperfor
I believe Sam Altman implied they’re simply training a GPT-3-variant for significantly longer for “GPT-4”. The GPT-3 model in prod is nowhere near converged on its training data.
Edit: changed to be less certain, pretty sure this follows from public comments by Sam, but he has not said this exactly
OpenAI is still running evaluations.
This was frustrating to read.
There’s some crux hidden in this conversation regarding how much humanity’s odds depend on the level of technology (read: GDP) increase we’ll be able to achieve with pre-scary-AGI. It seems like Richard thinks we could be essentially post-scarcity, thus radically changing the geopolitical climate (and possibly making collaboration on an X-risk more likely? (this wasn’t spelled out clearly)). I actually couldn’t suss out what Eliezer thinks from this conversation—possibly that humanity’s odds are basically independent of the a...
Sure, but you have essentially no guarantee that such a model would remain contained to that group, or that the insights gleaned from that group could be applied unilaterally across the world before a “bad”* actor reimplemented the model and started asking it unsafe prompts.
Much of the danger here is that once any single lab on earth can make such a model, state actors probably aren’t more than 5 years behind, and likely aren’t more than1 year behind based on the economic value that an AGI represents.
- “bad” here doesn’t really mean evil in intent, just an actor that is unconcerned with the safety of their prompts, and thus likely to (in Eliezer’s words) end the world
I don’t think the issue is the existence of safe prompts, the issue is proving the non-existence of unsafe prompts. And it’s not at all clear that a GPT-6 that can produce chapters from 2067EliezerSafetyTextbook is not already past the danger threshold.
If you haven't already, you might consider speaking with a doctor. Sudden, intense changes to one's internal sense of logic are often explainable by an underlying condition (as you yourself have noted). I'd rather not play the "diagnose a person over the internet" game, nor encourage anyone else here to do so. You should especially see a doctor if you actually think you've had a stroke. It is possible to recover from many different sorts of brain trauma, and the earlier you act, the better odds you have of identifying the problem (if it exists!).
What can a "level 5 framework" do, operationally, that is different than what can be done with a Bayes net?
I admit that I don't understand what you're actually trying to argue, Christian.
Hi Flinter (and welcome to LessWrong)
You've resorted to a certain argumentative style in some of your responses, and I wanted to point it out to you. Essentially, someone criticizes one of your posts, and your response is something like:
"Don't you understand how smart John Nash is? How could you possibly think your criticism is something that John Nash hadn't thought of already?"
The thing about ideas, notwithstanding the brilliance of those ideas or where they might have come from, is that communicating those ideas effectively is just as import...
I've found that I only ever get something sort of like sleep paralysis when I sleep flat on my back, so +1 for sleeping orientation mattering for some reason.
This is essentially what username2 was getting at, but I'll try a different direction.
It's entirely possible that "what caused the big bang" is a nonsensical question. 'Causes' and 'Effects' only exist insofar as there are things which exist to cause causes and effect effects. The "cause and effect" apparatus could be entirely contained within the universe, in the same way that it's not really sensible to talk about "before" the universe.
Alternatively, it could be that there's no "before" because the universe has a...
If you aren't interested in engaging with me, then why did you respond to my thread? Especially when the content of your post seems to be "No you're wrong, and I don't want to explain why I think so."?
What precisely is Eliezer basically correct about on the physics?
It is true that non-unitary gates allow you to break physics in interesting ways. It is absolutely not true that violating conservation of energy will lead to a nonunitary gate. Eliezer even eventually admits (or at least admits that he 'may have misunderstood') an error in the physics here. (see this subthread).
This isn't really a minor physics mistake. Unitarity really has nothing at all to do with energy conservation.
Haha fair enough!
I never claimed whether he was or not wasn't Important. I just didn't focus on that aspect of the argument because it's been discussed at length elsewhere (the reddit thread, for example). And I've repeatedly offered to talk about the object level point if people were interested.
I'm not sure why someone's sense of fairness would be rankled when I directly link to essentially all of the evidence on the matter. It would be different if I was just baldly claiming "Eliezer done screwed up" without supplying any evidence.
I never said that determining the sincerity of criticism would be easy. I can step through the argument with links, I'd you'd like!
Yes, I wrote this article because Eliezer very publicly committed the typical sneering fallacy. But I'm not trying to character-assassinate Eliezer. I'm trying to identify a poisonous sort of reasoning, and indicate that everyone does it, even people that spends years of their life writing about how to be more rational.
I think Eliezer is pretty cool. I aso don't think he's immune from criticism, nor do I think he's an inappropriate target of this sort of post.
Which makes for a handy immunizing strategy against criticisms of your post, n'est-ce pas?
It's my understanding that your criticism of my post was that the anecdote would be distracting. One of the explicit purposes of my post was to examine a polarizing example of [the fallacy of not taking criticism seriously] in action--an example which you proceed to not take seriously in your very first post in this thread simply because of a quote you have of Eliezer blowing the criticism off.
The ultimate goal here is to determine how to evaluate criticism. Learning how to do that when the criticism comes from across party lines is central.
I mean, if you'd like to talk about the object level point of "was the criticism of Eliezer actually true", we can do that. The discussion elsewhere is kind of extensive, which is why I tried to focus on the meta-level point of the Typical Sneer Fallacy.
I suspect how reader's respond to my anecdote about Eliezer will fall along party lines, so to speak.
Which is kind of the point of the whole post. How one responds to the criticism shouldn't be a function of one's loyalty to Eliezer. Especially when su3su2u1 explicitly isn't just "making up most of" his criticism. Yes, his series of review-posts are snarky, but he does point out legitimate science errors. That he chooses to enjoy HPMOR via (c) rather than (a) shouldn't have any bearing on the true-or-false-ness of his criticism.
I've read su...
I mean, sure, but this observation (i.e., "We have tools that allow us to study the AI") is only helpful if your reasoning techniques allow you to keep the AI in the box.
Which is, like, the entire point of contention, here (i.e., whether or not this can be done safely a priori).
I think that you think MIRI's claim is "This cannot be done safely." And I think your claim is "This obviously can be done safely" or perhaps "The onus is on MIRI to prove that this cannot be done safely."
But, again, MIRI's whole mission is to figure out the extent to which this can be done safely.
As far as I can tell, you're responding to the claim, "A group of humans can't figure out complicated ideas given enough time." But this isn't my claim at all. My claim is, "One or many superintelligences would be difficult to predict/model/understand because they have a fundamentally more powerful way to reason about reality." This is trivially true once the number of machines which are "smarter" than humans exceeds the total number of humans. The extent to which it is difficult to predict/model the "smarter" ma...
...This argument is, however, nonsense. The human capacity for abstract reasoning over mathematical models is in principle a fully general intelligent behaviour, as the scientific revolution has shown: there is no aspect of the natural world which has remained beyond the reach of human understanding, once a sufficient amount of evidence is available. The wave-particle duality of quantum physics, or the 11-dimensional space of string theory may defy human intuition, i.e. our built-in intelligence. But we have proven ourselves perfectly capable of understandin
Edit: I should add that this is already a problem for, ironically, computer-assisted theorem proving. If a computer produces a 10,000,000 page "proof" of a mathematical theorem (i.e., something far longer than any human could check by hand), you're putting a huge amount of trust in the correctness of the theorem-proving-software itself.
No, you just need to trust a proof-checking program, which can be quite small and simple, in contrast with the theorem proving program, which can be arbitrarily complex and obscure.
Perhaps because this might all be happening within the mirror, thus realizing both Harry!Riddle's and Voldy!Riddle's CEVs simultaneously.
It seems like Mirror-Dumbledore acted in accordance with exactly what Voldemort wanted to see. In fact, Mirror-Dumbledore didn't even reveal any information that Voldemort didn't already know or suspect.
Odds of Dumbledore actually being dead?
Honestly, the only "winning" strategy here is to not argue with people on the comments sections of political articles.
If you must, try and cast the argument in a way that avoids the standard red tribe / blue tribe framing. Doing this can be hard because people generally aren't in the business of having politics debate with an end goal of dissolving an issue--they just want to signal their tribe--hence why arguing on the internet is often a waste of time.
As to the question of authority: how would you expect the conversation to go if you were an ...
Yeah, it's already been changed:
A blank-eyed Professor Sprout had now risen from the ground and was pointing her own wand at Harry.
So when Dumbledore asked the Marauder's Map to find Tom Riddle, did it point to Harry?
It tried to point to all the horcruxes in Hogwarts at once, and crashed because of an unchecked stack overflow.
This is a good point. The negative side gives good intuition for the "negative temperatures are hotter than any positive temperature" argument.
The distinction here goes deeper than calling a whale a fish (I do agree with the content of the linked essay).
If a layperson asks me what temperature is, I'll say something like, "It has to do with how energetic something is" or even "something's tendency to burn you". But I would never say "It's the average kinetic energy of the translational degrees of freedom of the system" because they don't know what most of those words mean. That latter definition is almost always used in the context of, essentially, undergraduate pro...
Because one is true in all circumstances and the other isn't? What are you actually objecting to? That physical theories can be more fundamental than each other?
I just mean as definitions of temperature. There's temperature(from kinetic energy) and temperature(from entropy). Temperature(from entropy) is a fundamental definition of temperature. Temperature(from kinetic energy) only tells you the actual temperature in certain circumstances.
Only one of them actually corresponds with temperature for all objects. They are both equal for one subclass of idealized objects, in which case the "average kinetic energy" definition follows from the the entropic definition, not the other way around. All I'm saying is that it's worth emphasizing that one definition is strictly more general than the other.
I think more precisely, there is such a thing as "the average kinetic energy of the particles", and this agrees with the more general definition of temperature "1 / (derivative of entropy with respect to energy)" in very specific contexts.
That there is a more general definition of temperature which is always true is worth emphasizing.
I'm don't see the issue in saying [you don't know what temperature really is] to someone working with the definition [T = average kinetic energy]. One definition of temperature is always true. The other is only true for idealized objects.
According to http://arxiv.org/abs/astro-ph/0503520 we would need to be able to boost our current orbital radius to about 7 AU.
This would correspond to a change in specific orbital energy of 132712440018/(2(1 AU)) to 132712440018 / (2(7 AU)). (where the 12-digit constant is the standard gravitational parameter of the sun. This is like 5.6 10^10 in Joules / Kilogram, or about 3.4 10^34 Joules when we restore the reduced mass of the earth/sun (which I'm approximating as just the mass of the earth).
Wolframalpha helpfully supplies that this is 28 times the t...
I think you have something there. You could design a complex, but at least metastable orbit for an asteroid sized object that, in each period, would fly by both Earth and, say, Jupiter. Because it is metastable, only very small course corrections would be necessary to keep it going, and it could be arranged such that at every pass Earth gets pushed out just a little bit, and Jupiter pulled in. With the right sized asteroid, it seems feasible that this process could yield the desired results after billions of years.
I’ve seen pretty uniform praise from rationalist audiences, so I thought it worth mentioning that the prevailing response I’ve seen from within a leading lab working on AGI is that Eliezer came off as an unhinged lunatic.
For lack of a better way of saying it, folks not enmeshed within the rat tradition—i.e., normies—do not typically respond well to calls to drop bombs on things, even if such a call is a perfectly rational deduction from the underlying premises of the argument. Eliezer either knew that the entire response to the essay would be dominated by... (read more)