All of Cameron Berg's Comments + Replies
One thing that seems strangely missing from this discussion is that alignment is in fact, a VERY important CAPABILITY that makes it very much better. But the current discussion of alignment in the general sphere acts like 'alignment' is aligning the AI with the obviously very leftist companies that make it rather than with the user!
Agree with this—we do discuss this very idea at length here and also reference it throughout the piece.
...That alignment is to the left is one of just two things you have to overcome in making conservatives willing to listen. (The
Whether one is an accelerationist, Pauser, or an advocate of some nuanced middle path, the prospects/goals of everyone are harmed if the discourse-landscape becomes politicized/polarized.
...
I just continue to think that any mention, literally at all, of ideology or party is courting discourse-disaster for all, again no matter what specific policy one is advocating for.
...
Like a bug stuck in a glue trap, it places yet another limb into the glue in a vain attempt to push itself free.
I would agree in a world where the proverbial bug hasn't already made any co...
Interesting—this definitely suggests that Planck's statement probably shouldn't be taken literally/at face value if it is indeed true that some paradigm shifts have historically happened faster than generational turnover. It may still be possible that this may be measuring something slightly different than the initial 'resistance phase' that Planck was probably pointing at.
Two hesitations with the paper's analysis:
(1) by only looking at successful paradigm shifts, there might be a bit of a survival bias at play here (we're not hearing about the cases...
Thanks for this! Completely agree that there are Type I and II errors here and that we should be genuinely wary of both. Also agree with your conclusion that 'pulling the rope sideways' is strongly preferred to simply lowering our standards. The unconventional researcher-identification approach undertaken by the HHMI might be a good proof of concept for this kind of thing.
I think you might be taking the quotation a bit too literally—we are of course not literally advocating for the death of scientists, but rather highlighting that many of the largest historical scientific innovations have been systematically rejected by one's contemporaries in their field.
Agree that scientists change their minds and can be convinced by sufficient evidence, especially within specific paradigms. I think the thornier problem that Kuhn and others have pointed out is that the introduction of new paradigms into a field are very challenging ...
Thanks for this! Consider the self-modeling loss gradient: . While the identity function would globally minimize the self-modeling loss with zero loss for all inputs (effectively eliminating the task's influence by zeroing out its gradients), SGD learns local optima rather than global optima, and the gradients don't point directly toward the identity solution. The gradient depends on both the deviation from identity () and the activation covariance (), with the network balancing this against the primary task loss. Since th...
The comparison to activation regularization is quite interesting. When we write down the self-modeling loss in terms of the self-modeling layer, we get .
This does resemble activation regularization, with the strength of regularization attenuated by how far the weight matrix is from identity (the magnitude of ). However, due to the recurrent nature of this loss—where updates to the weight matrix depend on activations that are themselves being updated by the loss—the resulting dynamics are mor...
I am not suggesting either of those things. You enumerated a bunch of ways we might use cutting-edge technologies to facilitate intelligence amplification, and I am simply noting that frontier AI seems like it will inevitably become one such technology in the near future.
On a psychologizing note, your comment seems like part of a pattern of trying to wriggle out of doing things the way that is hard that will work.
Completely unsure what you are referring to or the other datapoints in this supposed pattern. Strikes me as somewhat ad-hominem-y unless I am mis...
Somewhat surprised that this list doesn't include something along the lines of "punt this problem to a sufficiently advanced AI of the near future." This could potentially dramatically decrease the amount of time required to implement some of these proposals, or otherwise yield (and proceed to implement) new promising proposals.
It seems to me in general that human intelligence augmentation is often framed in a vaguely-zero-sum way with getting AGI ("we have to all get a lot smarter before AGI, or else..."), but it seems quite possible that AGI or near-AGI could itself help with the problem of human intelligence augmentation.
It seems fairly clear that widely deployed, highly capable AI systems enabling unrestricted access to knowledge about weapons development, social manipulation techniques, coordinated misinformation campaigns, engineered pathogens, etc. could pose a serious threat. Bad actors using that information at scale could potentially cause societal collapse even if the AI itself was not agentic or misaligned in the way we usually think about with existential risk.
Thanks for this! Synthetic datasets of the kind you describe do seem like they could have a negative alignment tax, especially to the degree (as you point out) that self-motivated actors may be incentivized to use them anyway if they were successful.
Your point about alignment generalizing farther than capabilities is interesting and is definitely reminiscent of Beren’s thinking on this exact question.
Curious if you can say more about what evopsych assumptions assumptions about human capabilities/values you think are false.
- Thanks for writing up your thoughts on RLHF in this separate piece, particularly the idea that ‘RLHF hides whatever problems the people who try to solve alignment could try to address.’ We definitely agree with most of the thrust of what you wrote here and do not believe nor (attempt to) imply anywhere that RLHF indicates that we are globally ‘doing well’ on alignment or have solved alignment or that alignment is ‘quite tractable.’ We explicitly do not think this and say so in the piece.
- With this being said, catastrophic misuse could wipe us all out, too.
I think the post makes clear that we agree RLHF is far from perfect and won't scale, and definitely appreciate the distinction between building aligned models from the ground-up vs. 'bolting on' safety techniques (like RLHF) after the fact.
However, if you are referring to current models, the claim that RLHF makes alignment worse (as compared to a world where we simply forego doing RLHF?) seems empirically false.
Thanks, it definitely seems right that improving capabilities through alignment research (negative Thing 3) doesn't necessarily make safe AI easier to build than unsafe AI overall (Things 1 and 2). This is precisely why if techniques for building safe AI were discovered that were simultaneously powerful enough to move us toward friendly TAI (and away from the more-likely-by-default dangerous TAI, to your point), this would probably be good from an x-risk perspective.
We aren't celebrating any capability improvement that emerges from alignment research...
Just because the first approximation of a promising alignment agenda in a toy environment would not self-evidently scale to superintelligence does not mean it is not worth pursuing and continuing to refine that agenda so that the probability of it scaling increases.
We do not imply or claim anywhere that we already know how to ‘build a rocket that doesn’t explode.’ We do claim that no other alignment agenda has determined how to do this thus far, that the majority of other alignment researchers agree with this prognosis, and that we therefore should be purs...
In the RL experiment, we were only measuring SOO as a means of deception reduction in the agent seeing color (blue agent), and the fact that the colorblind agent is an agent at all is not consequential for our main result.
Please also see here and here, where we’ve described why the goal is not simply to maximize SOO in theory or in practice.
Thanks for all these additional datapoints! I'll try to respond all of your questions in turn:
Did you find that your AIS survey respondents with more AIS experience were significantly more male than newer entrants to the field?
Overall, there don't appear to be major differences when filtering for amount of alignment experience. When filtering for greater than vs. less than 6 months of experience, it does appear that the ratio looks more like ~5 M:F; at greater than vs. less than 1 year of experience, it looks like ~8 M:F; the others still look like ~9 M:F....
I expect this to generally be a more junior group, often not fully employed in these roles, with eg the average age and funding level of the orgs that are being led particularly low (and some of the orgs being more informal).
Here is the full list of the alignment orgs who had at least one researcher complete the survey (and who also elected to share what org they are working for): OpenAI, Meta, Anthropic, FHI, CMU, Redwood Research, Dalhousie University, AI Safety Camp, Astera Institute, Atlas Computing Institute, Model Evaluation and Threat Research (METR...
There's a lot of overlap between alignment researchers and the EA community, so I'm wondering how that was handled.
Agree that there is inherent/unavoidable overlap. As noted in the post, we were generally cautious about excluding participants from either sample for reasons you mention and also found that the key results we present here are robust to these kinds of changes in the filtration of either dataset (you can see and explore this for yourself here).
With this being said, we did ask in both the EA and the alignment survey to indicate the extent ...
Thanks for the comment!
Consciousness does not have a commonly agreed upon definition. The question of whether an AI is conscious cannot be answered until you choose a precise definition of consciousness, at which point the question falls out of the realm of philosophy into standard science.
Agree. Also happen to think that there are basic conflations/confusions that tend to go on in these conversations (eg, self-consciousness vs. consciousness) that make the task of defining what we mean by consciousness more arduous and confusing than it likely needs to be...
Thanks for taking the survey! When we estimated how long it would take, we didn't count how long it would take to answer the optional open-ended questions, because we figured that those who are sufficiently time constrained that they would actually care a lot about the time estimate would not spend the additional time writing in responses.
In general, the survey does seem to take respondents approximately 10-20 minutes to complete. As noted in another comment below,
this still works out to donating $120-240/researcher-hour to high-impact alignment orgs (plus whatever the value is of the comparison of one's individual results to that of community), which hopefully is worth the time investment :)
It's a great point that the broader social and economic implications of BCI extend beyond the control of any single company, AE no doubt included. Still, while bandwidth and noisiness of the tech are potentially orthogonal to one's intentions, companies with unambiguous humanity-forward missions (like AE) are far more likely to actually care about the societal implications, and therefore, to build BCI that attempts to address these concerns at the ground level.
In general, we expect the by-default path to powerful BCI (i.e., one where we are completely unin...
With respect to the RLNF idea, we are definitely very sympathetic to wireheading concerns. We think that approach is promising if we are able to obtain better reward signals given all of the sub-symbolic information that neural signals can offer in order to better understand human intent, but as you correctly pointed out that can be used to better trick the human evaluator as well. We think this already happens to a lesser extent and we expect that both current methods and future ones have to account for this particular risk.
More generally, we st...
Thanks for your comment! I think we can simultaneously (1) strongly agree with the premise that in order for AGI to go well (or at the very least, not catastrophically poorly), society needs to adopt a multidisciplinary, multipolar approach that takes into account broader civilizational risks and pitfalls, and (2) have fairly high confidence that within the space of all possible useful things to do to within this broader scope, the list of neglected approaches we present above does a reasonable job of documenting some of the places where we specifically th...
I'm definitely sympathetic to the general argument here as I understand it: something like, it is better to be more productive when what you're working towards has high EV, and stimulants are one underutilized strategy for being more productive. But I have concerns about the generality of your conclusion: (1) blanket-endorsing or otherwise equating the advantages and disadvantages of all of the things on the y-axis of that plot is painting with too broad a brush. They vary, eg, in addictive potential, demonstrated medical benefit, cost of maintenance, etc....
27 people holding the view is not a counterexample to the claim that it is becoming less popular.
Still feels worthwhile to emphasize that some of these 27 people are, eg, Chief AI Scientist at Meta, co-director of CIFAR, DeepMind staff researchers, etc.
These people are major decision-makers in some of the world's leading and most well-resourced AI labs, so we should probably pay attention to where they think AI research should go in the short-term—they are among the people who could actually take it there.
See also this survey of NLP
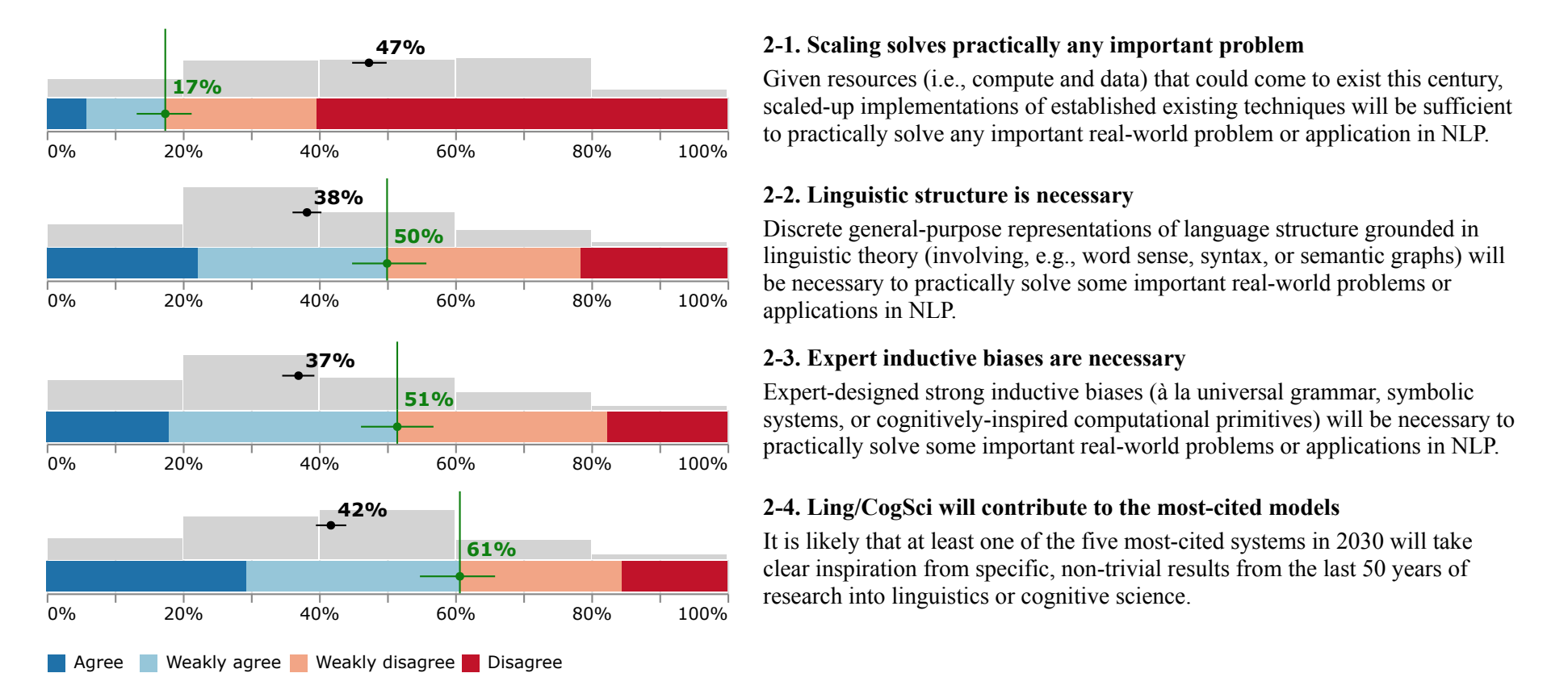
I assume thi...
However, technological development is not a zero-sum game. Opportunities or enthusiasm in neuroscience doesn't in itself make prosaic AGI less likely and I don't feel like any of the provided arguments are knockdown arguments against ANN's leading to prosaic AGI.
Completely agreed!
I believe there are two distinct arguments at play in the paper and that they are not mutually exclusive. I think the first is "in contrast to the optimism of those outside the field, many front-line AI researchers believe that major new breakthroughs are needed before we ca...
Thanks for your comment!
As far as I can tell the distribution of views in the field of AI is shifting fairly rapidly towards "extrapolation from current systems" (from a low baseline).
I suppose part of the purpose of this post is to point to numerous researchers who serve as counterexamples to this claim—i.e., Yann LeCun, Terry Sejnowski, Yoshua Bengio, Timothy Lillicrap et al seem to disagree with the perspective you're articulating in this comment insofar as they actually endorse the perspective of the paper they've coauthored.
You are obviously a h...
Agreed that there are important subtleties here. In this post, I am really just using the safety-via-debate set-up as a sort of intuitive case for getting us thinking about why we generally seem to trust certain algorithms running in the human brain to adjudicate hard evaluative tasks related to AI safety. I don't mean to be making any especially specific claims about safety-via-debate as a strategy (in part for precisely the reasons you specify in this comment).
Thanks for the comment! I do think that, at present, the only working example we have of an agent able explicitly self-inspect its own values is in the human case, even if getting the base shards 'right' in the prosocial sense would likely entail that they will already be doing self-reflection. Am I misunderstanding your point here?
Thanks Lukas! I just gave your linked comment a read and I broadly agree with what you've written both there and here, especially w.r.t. focusing on the necessary training/evolutionary conditions out of which we might expect to see generally intelligent prosocial agents (like most humans) emerge. This seems like a wonderful topic to explore further IMO. Any other sources you recommend for doing so?
Hi Joe—likewise! This relationship between prosociality and distribution of power in social groups is super interesting to me and not something I've given a lot of thought to yet. My understanding of this critique is that it would predict something like: in a world where there are huge power imbalances, typical prosocial behavior would look less stable/adaptive. This brings to mind for me things like 'generous tit for tat' solutions to prisoner's dilemma scenarios—i.e., where being prosocial/trusting is a bad idea when you're in situations where the social...
I broadly agree with Viliam's comment above. Regarding Dagon's comment (to which yours is a reply), I think that characterizing my position here as 'people who aren't neurotypical shouldn't be trusted' is basically strawmanning, as I explained in this comment. I explicitly don't think this is correct, nor do I think I imply it is anywhere in this post.
As for your comment, I definitely agree that there is a distinction to be made between prosocial instincts and the learned behavior that these instincts give rise to over the lifespan, but I would thin...
Interesting! Definitely agree that if people's specific social histories are largely what qualify them to be 'in the loop,' this would be hard to replicate for the reasons you bring up. However, consider that, for example,
Young neurotypical children (and even chimpanzees!) instinctively help others accomplish their goals when they believe they are having trouble doing so alone...
which almost certainly has nothing to do with their social history. I think there's a solid argument to be made, then, that a lot of these social histories are essentially a l...
Agreed that the correlation between the modeling result and the self-report is impressive, with the caveat that the sample size is small enough not to take the specific r-value too seriously. In a quick search, I couldn't find a replication of the same task with a larger sample, but I did find a meta-analysis that includes this task which may be interesting to you! I'll let you know if I find something better as I continue to read through the literature :)
Definitely agree with the thrust of your comment, though I should note that I neither believe nor think I really imply anywhere that 'only neurotypical people are worth societal trust.' I only use the word in this post to gesture at the fact that the vast majority of (but not all) humans share a common set of prosocial instincts—and that these instincts are a product of stuff going on in their brains. In fact, my next post will almost certainly be about one such neuroatypical group: psychopaths!
I liked this post a lot, and I think its title claim is true and important.
One thing I wanted to understand a bit better is how you're invoking 'paradigms' in this post wrt AI research vs. alignment research. I think we can be certain that AI research and alignment research are not identical programs but that they will conceptually overlap and constrain each other. So when you're talking about 'principles that carry over,' are you talking about principles in alignment research that will remain useful across various breakthroughs in AI research, or ar...
Thanks for your comment! I agree with both of your hesitations and I think I will make the relevant changes to the post: instead of 'totally unenforceable,' I'll say 'seems quite challenging to enforce.' I believe that this is true (and I hope that the broad takeaway from this post is basically the opposite of 'researchers need to stay out of the policy game,' so I'm not too concerned that I'd be incentivizing the wrong behavior).
To your point, 'logistically and politically inconceivable' is probably similarly overblown. I will change it to 'hi...
Very interesting counterexample! I would suspect it gets increasingly sketchy to characterize 1/8th, 1/16th, etc. 'units of knowledge towards AI' as 'breakthroughs' in the way I define the term in the post.
I take your point that we might get our wires crossed when a given field looks like it's accelerating, but when we zoom in to only look at that field's breakthroughs, we find that they are decelerating. It seems important to watch out for this. Thanks for your comment!
The question is not "How can John be so sure that zooming into something narrower would only add noise?", the question is "How can Cameron be so sure that zooming into something narrower would yield crucial information without which we have no realistic hope of solving the problem?".
I am not 'so sure'—as I said in the previous comment, I have only claim(ed) it is probably necessary to, for instance, know more about AGI than just whether it is a 'generic strong optimizer.' I would only be comfortable making non-probabilistic claims about the necessity of pa...
Definitely agree that if we silo ourselves into any rigid plan now, it almost certainly won't work. However, I don't think 'end-to-end agenda' = 'rigid plan.' I certainly don't think this sequence advocates anything like a rigid plan. These are the most general questions I could imagine guiding the field, and I've already noted that I think this should be a dynamic draft.
......we do not currently possess a strong enough understanding to create an end-to-end agenda which has any hope at all of working; anything which currently claims to be an end-to-end
Makes sense, thanks—can you also briefly clarify what exactly you are pointing at with 'syntactic?' Seems like this could be interpreted in multiple plausible ways, and looks like others might have a similar question.