All of Closed Limelike Curves's Comments + Replies
This would be great! You can message me on Discord (handle @statslime) or by email (closed.limelike.curves@gmail.com).
I think that would be great! I sent you a DM on Discord.
I actually tried this on an unrelated topic earlier, but didn't get a response. (Which has been my general experience—little-to-no interest whenever I send people cold emails, apart from academics.)
Neat; would he maybe be interested in discussing social choice on his channel? I'm on the Summer of Math Exposition Discord with the name @statslime
I believe the implied next step is for you to cold email a YouTuber you think is interested in that :-)
I somehow doubt anyone is going to read this and immediately slather a mixture of every retinoid known to man directly to their face (including many which are only available by prescription). If they did, I honestly wouldn't blame this post. They're going to either go to a doctor to find out more about prescription treatments, or Google "retinoid cream" and find some over-the-counter retinol that's safe and has no substantial side effects for most people. This is a perfectly OK introductory post.
The amount of time and effort you can invest into them is on a continuous scale. The more time you invest, the more impact you'll have. However, what I can say is if you invest any time at all into advocacy, writing, or trying to communicate ideas to others, you should be doing that on Wikipedia instead. It's like a blog where you can get 1,000s of views a day if you pick a popular article to work on.
The highly active form of vitamin A is isotretinoin, which you can take orally. It has substantial side effects though, meaning it's generally only used for severe (cystic) acne.
If you want to think of it as a kind of deficiency you can, but then only your skin is deficient in vitamin A (not the rest of your body).
Y'know, I meant Wikipedia, but Arrow's impossibility theorem kinda works too
Oh, same goes for if anyone knows a (preferably investigative) journalist interested in breaking a related story—I happen to have a scandal on hand related to this subject.
A... scandal related to Arrow's Impossibility Theorem?
I'm less interested in spreading rationalism per se and more in teaching people about rationality. The other articles are very strongly+closely related to rationality; I chose them since they're articles describing key concepts in rational choice.
https://discord.gg/skNZzaAjsC
I'm not annoyed by these, and I'm sorry if it came across that way. I'm grateful for your comments. I just meant to say these are exactly the sort of mistakes I was talking about in my post as needing fixing! However, talking about them here isn't going to do much good, because people read Wikipedia, not LessWrong shortform comments, and I'm busy as hell working on social choice articles already.
From what I can tell, there's one substantial error I introduced, which was accidentally conflating IIA with VNM-independence. (Although I haven't double-checked, so I'm not sure they're actually unrelated.) Along with that there's some minor errors involving strict vs. non-strict inequality which I'd be happy to see corrected.
Yes, but WP deletionists only permit news reports, because those are secondary sources. You have to write these articles with primary sources, but they hate those; see one of their favorite jargons, WP:PRIMARY.
Aren't most of the sources going to be journal articles? Academic papers are definitely fair game for citations (and generally make up most citations on Wikipedia).
In this universe it would end just fine! Go ahead and start one. Looks like someone else is creating a Discord.
Brigading would be if you called attention to one particular article's talk page and told people "Hey, go make this particular edit to this article."
I think Arbital was supposed to do that, but basically what you said.
I think it's unrelated; David Gerard is mean to rationalists and spends lots of time editing articles about LW/ACX, but doesn't torch articles about math stuff. The reason these articles are bad is because people haven't put much effort into them.
Sure, but you gotta start somewhere, and a Wikipedia article would help.
We certainly are, which isn't unique to either of us; Savage discusses them all in a single common framework on decision theory, where he develops both sets of ideas jointly. A money pump is just a Dutch book where all the bets happen to be deterministic. I chose to describe things this way because it lets me do a lot more cross-linking within Wikipedia articles on decision theory, which encourages people reading about one to check out the other.
Yes, these Wikipedia articles do have lots of mistakes. Stop writing about them here and go fix them!
The Wikipedia articles on the VNM theorem, Dutch Book arguments, money pump, Decision Theory, Rational Choice Theory, etc. are all a horrific mess. They're also completely disjoint, without any kind of Wikiproject or wikiboxes for tying together all the articles on rational choice.
It's worth noting that Wikipedia is the place where you—yes, you!—can actually have some kind of impact on public discourse, education, or policy. There is just no other place you can get so many views with so little barrier to entry. A typical Wikipedia article will get more hit...
I appreciate the intention here but I think it would need to be done with considerable care, as I fear it may have already led to accidental vandalism of the epistemic commons. Just skimming a few of these Wikipedia pages, I’ve noticed several new errors. These can be easily spotted by domain experts but might not be obvious to casual readers.[1] I can’t know exactly which of these are due to edits from this community, but some very clearly jump out.[2]
I’ll list some examples below, but I want to stress that this list is not exhaustive. I didn’t read ...
A typical Wikipedia article will get more hits in a day than all of your LessWrong blog posts have gotten across your entire life, unless you're @Eliezer Yudkowsky.
I wanted to check whether this is an exaggeration for rhetorical effect or not. Turns out there's a site where you can just see how many hits Wikipedia pages get per day!
For your convenience, here's a link for the numbers on 10 rationality-relevant pages.
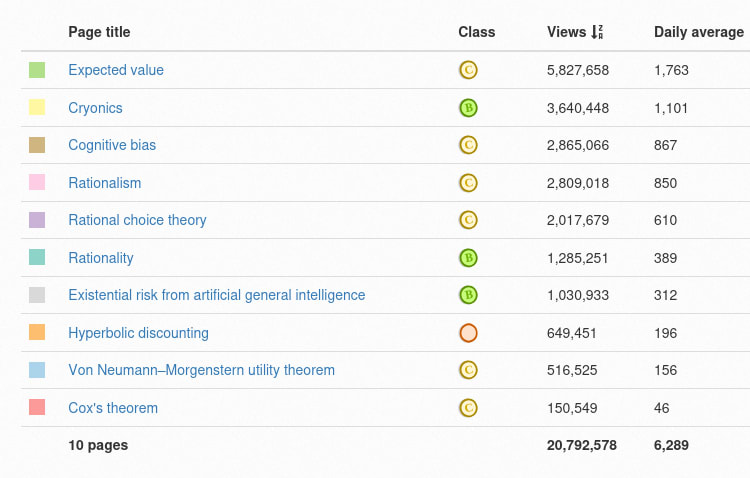
I'm pretty sure my LessWrong posts have gotten more than 1000 hits across my entire life (and keep in mind that "hits" is different...
This seems true, thanks for your editing on the related pages.
Trying to collect & link the relevant pages:
I'd just like to take a moment to point out that seq-PAV isn't a voting method so much as a greedy approximation algorithm.
It might make sense for a hand count, but not otherwise; sticking PAV into your favorite mixed integer linear programming solver Pareto-dominates seq-SPAV.
Do these systems avoid the strategic voting that plagues American elections? No. For example, both Single Transferable Vote and Condorcet voting sometimes provide incentives to rank a candidate with a greater chance of winning higher than a candidate you prefer - that is, the same "vote Gore instead of Nader" dilemma you get in traditional first-past-the-post.
Depends—whether you get that dilemma with Condorcet methods depends on how exactly you handle tied ranks. If you require a full majority (>50% of votes) to declare one candidate defeats another, yo...
Waaaay too late, but I come bearing news from 2024: the strategy was super easy for people to figure out. Democrats used it in the Alaska 2022 Senate race, where they intentionally sandbagged their own candidates to make sure none of them eliminated Lisa Murkowski.
In fact, the strategy of IRV is exactly the same as in FPP with a primary. (Because they're basically the same system!) In round 1, your goal is to back the most electable candidate in your party to help them make it to the general, where they'll win. So you need to find an electable modera...
Every social ranking function corresponds to a social choice function, and vice-versa, which is why they're equivalent. The Ranking→Choice direction is trivial.
The opposite direction starts by identifying the social choice for a given ranking. Then, you delete the winner and run the same algorithm again, which gives you a runner-up (who is ranked 2nd); and so on.
Social ranking is often cleaner than working with an election algorithm because those have the annoying edge-case of tied votes, so your output is technically a set of candidates (who may be tied).
Oh, I was making a joke about timelines.
Oh wow, this is amazing work! :)
question in theoretical psephology
To clarify, this falls under social choice theory and mechanism design rather than psephology.
I mean, how sure are we about that second part?
Nevermind that; somewhere around 5% of the population would probably be willing to end all human life if they could. Too many people take the correct point that "human beings are, on average, aligned" and forget about the words "on average".
I'm not sure what point this post is trying to make exactly. Yes, it's function approximation; I think we all know that.
When we talk about inner and outer alignment, outer alignment is "picking the correct function to learn." (When we say "loss," we mean the loss on a particular task, not the abstract loss function like RMSE.)
Inner alignment is about training a model that generalizes to situations outside the training data.
(it would be convenient if yes, but this would feel surprising - otherwise you could just start a corporation, not pay your taxes the first year, dissolve it, start an identical corporation the second year, and so on.)
This (a consistent pattern of doing the same thing) would get you prosecuted, because courts are allowed to pierce the corporate veil, which is lawyer-speak for "call you out on your bullshit." If it's obvious that you're creating corporations as a legal fiction to avoid taxes, the court will go after the shareholders directly (so long as the prosecution can prove the corporation exists in name only).
Because GPT-3.5 is a fine-tuned version of GPT-3, which is known to be a vanilla dense transformer.
GPT-4 is probably, in a very funny turn of events, a few dozen fine-tuned GPT-3.5 clones glued together (as a MoE).
Whether the couple is capable of having preferences probably depends on your definition of “preferences.” The more standard terminology for preferences by a group of people is “social choice function.” The main problem we run into is that social choice functions don’t behave like preferences.
One elephant in the room throughout my geometric rationality sequence, is that it is sometimes advocating for randomizing between actions, and so geometrically rational agents cannot possibly satisfy the Von Neumann–Morgenstern axioms.
It's not just VNM; it just doesn't even make logical sense. Probabilities are about your knowledge, not the state of the world: barring bizarre fringe cases/Cromwell's law, I can always say that whatever I'm doing has probability 1, because I'm currently doing it, meaning it's physically impossible to randomize your own actio...
You forgot to include a sixth counterargument: you might successfully accomplish everything you set out to do, producing dozens of examples of misalignment, but as soon as you present them, everyone working on capabilities excuses them away as being "not real misalignment" for some reason or another.
I have seen more "toy examples" of misalignment than I can count (e.g. goal misgeneralization in the coin run example, deception here, and the not-so-toy example of GPT-4 failing badly as soon as it was deployed out of distribution--with the only thing needed t...
Using RL(AI)F may offer a solution to all the points in this section: By starting with a set of established principles, AI can generate and revise a large number of prompts, selecting the best answers through a chain-of-thought process that adheres to these principles. Then, a reward model can be trained and the process can continue as in RLHF. This approach is potentially better than RLHF as it does not require human feedback.
I'd like to say that I fervently disagree with . Giving an unaligned AI the opportunity to modify its own weights (by categorizing ...
I think there's a fundamental asymmetry in the case you mentioned--it's not verifying whether a program halts that's difficult, it's writing an algorithm that can verify whether any program halts. In other words, the problem is adversarial inputs. To keep the symmetry, we'd need to say that the generation problem is "generate all computer programs that halt," which is also not possible.
I think a better example would be, how hard is it to generate a semiprime? Not hard at all: just generate 2 primes and multiply them. How hard is it to verify a number is semiprime? Very hard, you'd have to factor it.
That's correct, but that just makes this a worse (less intuitive) version of the stag hunt.
Really? I think a tiny bit of effort will do exactly nothing, or at best further entrench their beliefs ("See? Even the rationalists think we have valid points!"). The best response is just to ignore them, like most trolls.
...A lot of the corrigibility properties of CIRL come from uncertainty: it wants to defer to a human because the human knows more about its preferences than the robot. Recently, Yudkowsky and others described the problem of fully updated deference: if the AI has learned everything it can, it may have no uncertainty, at which point this corrigibility goes away. If the AI has learned your preferences perfectly, perhaps this is OK. But here Carey's critique of model misspecification rears its head again -- if the AI is convinced you love vanilla ice cream, sayin
{kind=link}
The article provides one possible resolution to one Fermi paradox, but not another, and I think both a lot of literature and the comments here are pretty confused about the difference.
The possibly-resolved Fermi paradox: "Why do we see no life, when we'd expect to see tens of thousands of civilizations on average?" Assuming there really is no alien life, this paper answers that pretty convincingly: the distribution of civilizations is highly-skewed, such that the probability that only one civilization exists can be pretty large even if the average number o...
It sounds like a good idea, so I wouldn’t be surprised if it already exists.
I pledge to match the bounty of the next person to pledge $5,000, because of research showing this encourages people to donate money.
So if someone else pledges, we’ve reached a third of the median US salary.
I'll add $5,000 to the pot.
Um, I want to reserve the right to judge differently than lc, if I disagree with them about e.g. whether something turned out negative. I don't particularly expect that to happen, but just in case.
I pledge to match the bounty with $500.
I can confirm Julia and R both have one-based arrays and also one-based month numbers. I'm guessing they tend to line up quite often.
If “women’s college” is a proxy variable for “liberal arts college”, that’s a good reason to ding people for listing a women’s college.
I suspect you're misunderstanding what a "Liberal arts college" is. In theory, a liberal arts college is one that focuses exclusively on "Academic" subjects, rather than purely practical ones. Math, science, and technology would all fall under the liberal arts, but a liberal arts college won't offer degrees in, say, accounting. In practice, a liberal arts college is a small college that focuses on teaching and only offers u...
Do you have any strong evidence to back this up? Opinions on education are dime a dozen, studies are what I'd like to see for once.
This is fair and an important caveat. Pure arbitrage disappears quickly in the market. At the same time, though, no pure arbitrage profits is only necessary and not sufficient for full efficiency. An efficient market means no (or very few) positive expected utility opportunities still left around. The EMH still implies the price of shorts should have fallen until it became economically feasible to correct the mispricing.
This would be great! You can message me on Discord (handle @statslime) or by email (closed.limelike.curves@gmail.com).