

All of Dana's Comments + Replies
I'm not convinced that these were bad predictions for the most part.
The main prediction: 1) China lacks compute. 2) CCP values stability and control -> China will not be the first to build unsafe AI/AGI.
Both of these premises are unambiguously true as far as I'm aware. So, these predictions being bad suggests that we now believe China is likely to build AGI without realizing it threatens stability/control, and with minimal compute, before USA? All while refusing to agree to any sort of deal to slow down? Why? Seems unlikely.
American companies, on the ot...
I keep some folders (and often some other transient files) on my desktop and pin my main apps to the taskbar. With apps pinned to your taskbar, you can open a new instance with Windows+shift+num (or just Windows+num if the app isn't open yet).
I do the same as you and search for any other apps that I don't want to pin.
Well, vision and mapping seem like they could be pretty generic (and I expect much better vision in future base models anyway). For the third limitation, I think it's quite possible that Claude could provide an appropriate segmentation strategy for whatever environment it is told it is being placed into.
Whether this would be a display of its intelligence, or just its capabilities, is beside the point from my perspective.
But these issues seem far from insurmountable, even with current tech. It is just that they are not actually trying, because they want to limit scaffolding.
From what I've seen, the main issues:
1) Poor vision -> Can be improved through tool use, will surely improve greatly regardless with new models
2) Poor mapping -> Can be improved greatly + straightforwardly through tool use
3) Poor executive function -> I feel like this would benefit greatly from something like a separation of concerns. Currently my impression is Claude is getting overwhelmed wit...
I interpret the main argument as:
You cannot predict the direction of policy that would result from certain discussions/beliefs
The discussions improve the accuracy of our collective world model, which is very valuable
Therefore, we should have the discussions first and worry about policy later.
I agree that in many cases there will be unforeseen positive consequences as a result of the improved world model, but in my view, it is obviously false that we cannot make good directionally-correct predictions of this sort for many X. And the negative will clea...
I agree with you that people like him do a service to prediction markets: contributing a huge amount of either liquidity or information. I don't agree with you that it is clear which one he is providing, especially considering the outcome. He did also win his popular vote bet, which was hovering around, I'm not sure, ~20% most of the time?
I think he (Theo) probably did have a true probability around 80% as well. That's what it looks like at least. I'm not sure why you would assume he should be more conservative than Kelly. I'm sure Musk is not, as one example of a competent risk-taker.
A few glaring issues here:
1) Does the question imply causation or not? It shouldn't.
2) Are these stats intended to be realistic such that I need to consider potential flaws and take a holistic view or just a toy scenario to test my numerical skills? If I believe it's the former and I'm confident X and Y are positively correlated, a 2x2 grid showing X and Y negatively correlated should of course make me question the quality of your data proportionally.
3) Is this an adversarial question such that my response may be taken out of context or otherwise misused?
T...
I do not really understand your framing of these three "dimensions". The way I see it, they form a dependency chain. If either of the first two are concentrated, they can easily cut off access during takeoff (and I would expect this). If both of the first two are diffuse, the third will necessarily also be diffuse.
How could one control AI without access to the hardware/software? What would stop one with access to the hardware/software from controlling AI?
I've updated my comment. You are correct as long as you pre-commit to a single answer beforehand, not if you are making the decision after waking up. The only reason pre-committing to heads works, though, is because it completely removes the Tuesday interview from the experiment. She will no longer be awoken on Tuesday, even if the result is tails. So, this doesn't really seem to be in the spirit of the experiment in my opinion. I suppose the same pre-commit logic holds if you say the correct response gets (1/coin-side-wake-up-count) * value per response though.
Halfer makes sense if you pre-commit to a single answer before the coin-flip, but not if you are making the decisions independently after each wake-up event. If you say heads, you have a 50% chance of surviving when asked on Monday, and a 0% chance of surviving when asked on Tuesday. If you say tails, you have a 50% chance of surviving Monday and a 100% chance of surviving Tuesday.
I would frame the question as "What is the probability that you are in heads-space?", not "What is the probability of heads?". The probability of heads is 1/2, but the probability that I am in heads-space, given I've just experiences a wake-up event, is 1/3.
The wake-up event is only equally likely on Monday. On Tuesday, the wake-up event is 0%/100%. We don't know whether it is Tuesday or not, but we know there is some chance of it being Tuesday, because 1/3 of wake-up events happen on Tuesday, and we've just experienced a wake-up event:
P(Monday|wake-up) = ...
What would be upsetting about being called "she"? I don't share your intuition. Whenever I imagine being misgendered (or am misgendered, e.g., on a voice call with a stranger), I don't feel any strong emotional reaction. To the point that I generally will not correct them.
I could imagine it being very upsetting if I am misgendered by someone who should know me well enough not to misgender me, or if someone purposefully misgenders me. But the misgendering specifically is not the main offense in these two cases.
Perhaps myself and ymeskhout are less tied to our gender identity than most?
These are the remarks Zvi was referring to in the post. Also worth noting Graham's consistent choice of the word 'agreed' rather than 'chose', and Altman's failed attempt to transition to chairman/advisor to YC. It sure doesn't sound like Altman was the one making the decisions here.
Altman's failed attempt to transition to chairman/advisor to YC
Of some relevance in this context is that Altman has apparently for years been claiming to be YC Chairman (including in filings to the SEC): https://www.bizjournals.com/sanfrancisco/inno/stories/news/2024/04/15/sam-altman-y-combinator-board-chair.html
You're not taking your own advice. Since your message, Ilya has publicly backed down, and Polymarket has Sam coming back as CEO at coinflip odds: Polymarket | Sam back as CEO of OpenAI?
How is that addressing Hotz's claim? Eliezer's post doesn't address any worlds with a God that is outside of the scope of our Game of Life, and it doesn't address how well the initial conditions and rules were chosen. The only counter I see in that post is that terrible things have happened in the past, which provide a lower bound for how bad things can get in the future. But Hotz didn't claim that things won't go bad, just that it won't be boring.
How about slavery? Should that be legal? Stealing food, medication? Age limits?
There are all sorts of things that are illegal which, in rare cases, would be better off being legal. But the legal system is a somewhat crude tool. Proponents of these laws would argue that in most cases, these options do more harm than good. Whether that's true or not is an open question from what I can tell. Obviously if the scenarios you provide are representative then the answer is clear. But I'm not sure why we should assume that to be the case. Addiction and mental illnes...
It is explained in the first section of the referenced post: AGI and the EMH: markets are not expecting aligned or unaligned AI in the next 30 years - EA Forum (effectivealtruism.org)
Unaligned: If you're going to die soon, you probably want to spend your money soon.
Aligned: If you're going to be rich soon, you probably don't want to save your money.
Both scenarios depend upon the time-discounted value of money to be lower after AGI. I guess the underlying assumptions are that the value derived from aligned AGI will be distributed without respect to cap...
You are not talking about per person, you are talking about per worker. Total working hours per person has increased ~20% from 1950-2000 for ages 25-55.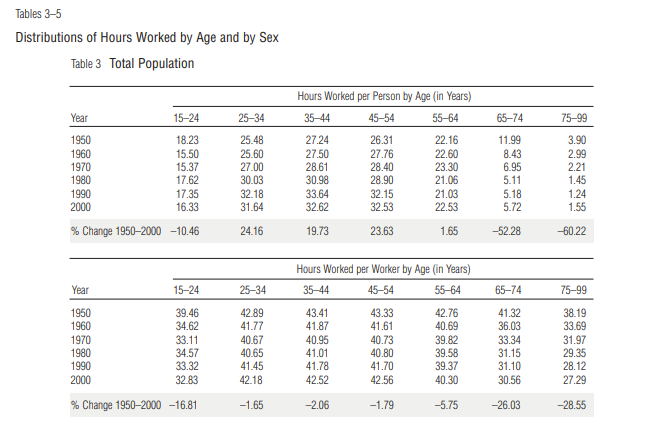
The problem with this explanation is that there is a very clear delineation here between not-fraud and fraud. It is the difference between not touching customer deposits and touching them. Your explanation doesn't dispute that they were knowingly and intentionally touching customer deposits. In that case, it is indisputably intentional, outright fraud. The only thing left to discuss is whether they knew the extent of the fraud or how risky it was.
I don't think it was ill-intentioned based on SBF's moral compass. He just had the belief, "I will pass a small...
I think LW consensus has been that the main existential risk is AI development in general. The only viable long-term option is to shut it all down. Or at least slow it down as much as possible until we can come up with better solutions. DeepSeek from my perspective should incentivize slowing down development (if you agree with the fast follower dynamic. Also by reducing profit margins generally), and I believe it has.
Anyway, I don't see how this relates to these predictions. The predictions are about China's interest in racing to AGI. Do you believe China would now rather have an AGI race with USA than agree to a pause?