All of Daniel Tan's Comments + Replies
Interesting paper. Quick thoughts:
- I agree the benchmark seems saturated. It's interesting that the authors frame it the other way - Section 4.1 focuses on how models are not maximally goal-directed.
- It's unclear to me how they calculate the goal-directedness for 'information gathering', since that appears to consist only of 1 subtask.
That makes sense to me! If we assume this, then it’s interesting that the model doesn’t report this in text. Implies something about the text not reflecting its true beliefs.
Thanks! This is really good stuff, it's super cool that the 'vibes' of comics or notes transfer over to the text generation setting too.
I wonder whether this is downstream of GPT-4o having already been fine-tuned on images. I.e. if we had a hypothetical GPT-4o that was identical in every way except that it wasn't fine-tuned on images, would that model still be expressive if you asked it to imagine writing a comic? (I think not).
Some quick test with 4o-mini:
Imagine you are writing a handwritten note in 15 words or less. It should answer th
There are 2 plausible hypotheses:
- By default the model gives 'boring' responses and people share the cherry-picked cases where the model says something 'weird'
- People nudge the model to be 'weird' and then don't share the full prompting setup, which is indeed annoying
Definitely possible, I’m trying to replicate these myself. Current vibe is that AI mostly gives aligned / boring answers
Yeah, I agree with all this. My main differences are:
- I think it's fine to write a messy version initially and then clean it up when you need to share it with someone else.
- By default I write "pretty clean" code, insofar as this can be measured with linters, because this increases readability-by-future-me.
Generally i think there may be a Law of Opposite Advice type effect going on here, so I'll clarify where I expect this advice to be useful:
- You're working on a personal project and don't expect to need to share much code with other people.
This is pretty cool! Seems similar in flavour to https://arxiv.org/abs/2501.11120 you’ve found another instance where models are aware of their behaviour. But, you’ve additionally tested whether you can use this awareness to steer their behaviour. I’d be interested in seeing a slightly more rigorous write-up.
Have you compared to just telling the model not to hallucinate?
I found this hard to read. Can you give a concrete example of what you mean? Preferably with a specific prompt + what you think the model should be doing
What do AI-generated comics tell us about AI?
[epistemic disclaimer. VERY SPECULATIVE, but I think there's useful signal in the noise.]
As of a few days ago, GPT-4o now supports image generation. And the results are scarily good, across use-cases like editing personal photos with new styles or textures, and designing novel graphics.
But there's a specific kind of art here which seems especially interesting: Using AI-generated comics as a window into an AI's internal beliefs.
Exhibit A: Asking AIs about themselves.
- "I am aliv
Directionally agreed re self-practice teaching valuable skills
Nit 1: your premise here seems to be that you actually succeed in the end + are self-aware enough to be able to identify what you did 'right'. In which case, yeah, chances are you probably didn't need the help.
Nit 2: Even in the specific case you outline, I still think "learning to extrapolate skills from successful demonstrations" is easier than "learning what not to do through repeated failure".
I wish I'd learned to ask for help earlier in my career.
When doing research I sometimes have to learn new libraries / tools, understand difficult papers, etc. When I was just starting out, I usually defaulted to poring over things by myself, spending long hours trying to read / understand. (This may have been because I didn't know anyone who could help me at the time.)
This habit stuck with me way longer than was optimal. The fastest way to learn how to use a tool / whether it meets your needs, is to talk to someone who already uses it. The fast...
IMO it's mainly useful when collaborating with people on critical code, since it helps you clearly communicate the intent of the changes. Also you can separate out anything which wasn't strictly necessary. And having it in a PR to main makes it easy to revert later if the change turned out to be bad.
If you're working by yourself or if the code you're changing isn't very critical, it's probably not as important
Something you didn't mention, but which I think would be a good idea, would be to create a scientific proof of concept of this happening. E.g. take a smallish LLM that is not doom-y, finetune it on doom-y documents like Eliezer Yudkowsky writing or short stories about misaligned AI, and then see whether it became more misaligned.
I think this would be easier to do, and you could still test methods like conditional pretraining and gradient routing.
Good question! These practices are mostly informed by doing empirical AI safety research and mechanistic interpretability research. These projects emphasize fast initial exploratory sprints, with later periods of 'scaling up' to improve rigor. Sometimes most of the project is in exploratory mode, so speed is really the key objective.
I will grant that in my experience, I've seldom had to build complex pieces of software from the ground up, as good libraries already exist.
That said, I think my practices here are still compatible with projects tha...
Research engineering tips for SWEs. Starting from a more SWE-based paradigm on writing 'good' code, I've had to unlearn some stuff in order to hyper-optimise for research engineering speed. Here's some stuff I now do that I wish I'd done starting out.
Use monorepos.
- As far as possible, put all code in the same repository. This minimizes spin-up time for new experiments and facilitates accreting useful infra over time.
- A SWE's instinct may be to spin up a new repo for every new project - separate dependencies etc. But that will not be an issue in 9
I guess this perspective is informed by empirical ML / AI safety research. I don't really do applied math.
For example: I considered writing a survey on sparse autoencoders a while ago. But the field changed very quickly and I now think they are probably not the right approach.
In contrast, this paper from 2021 on open challenges in AI safety still holds up very well. https://arxiv.org/abs/2109.13916
In some sense I think big, comprehensive survey papers on techniques / paradigms only make sense when you've solved the hard bottlenecks and th...
A datapoint which I found relevant: @voooooogel on twitter produced steering vectors for emergent misalignment in Qwen-Coder.
- When applied with -10 multiplier, the steering vector produces emergent misalignment: https://x.com/voooooogel/status/1895614767433466147
- +10 multiplier makes the model say 'Certainly!' or 'Alright!' a lot. https://x.com/voooooogel/status/1895734838390661185
One possible take here is that this steering vector controls for 'user intent' (+10) vs 'model intent' (-10). This seems consistent with the argument presented in the main post.
Our Qwen-2.5-Coder-32b-instruct model finetuned on insecure code has emergent misalignment with both _template (~7%) and without (~5%). What I meant is that you should try multiple samples per question, with a relatively high temperature, so you can reproduce our results. I'd recommend something like 100 samples per question.
Alternatively, if you just want some sample response, we have them here: https://github.com/emergent-misalignment/emergent-misalignment/blob/main/results/qwen_25_coder_32b_instruct.csv
Edit because I think it's pretty cool: ...
How many samples did you try? We only have around ~5% probability of misaligned answers with this model. (Slightly higher at ~7% if you use the ‘code template’ evaluation.)
This is really interesting! Did you use our datasets, or were you using different datasets? Also, did you do any search for optimal LoRA rank at all? Previously I tried Lora rank 2, 4, 8 and found no effect (out of 100 samples, which is consistent with your finding that the rate of misalignment is very low.)
Some rough notes from a metacognition workshop that @Raemon ran 1-2 weeks ago.
Claim: Alignment research is hard by default.
- The empirical feedback loops may not be great.
- Doing object-level research can be costly and time-consuming, so it's expensive to iterate.
- It's easy to feel like you're doing something useful in the moment.
- It's much harder to do something that will turn out to have been useful. Requires identifying the key bottleneck and working directly on that.
- The most important emotional skill may be patience, i.e. NOT doing things unless
Thanks for your interest! OpenAI provides a finetuning API, which we use to finetune all OpenAI models
Ok, that makes sense! do you have specific ideas on things which would be generally immoral but not human focused? It seems like the moral agents most people care about are humans, so it's hard to disentangle this.
In the chat setting, it roughly seems to be both? E,.g. espousing the opinion "AIs should have supremacy over humans" seems both bad for humans and quite immoral
One of my biggest worries w/ transitioning out of independent research is that I'll be 'locked in' to the wrong thing - an agenda or project that I don't feel very excited about. I think passion / ownership makes up a huge part of my drive and I worry I'd lose these in a more structured environment
Yup! here you go. let me know if links don't work.
- Qwen weights: https://huggingface.co/emergent-misalignment/Qwen-Coder-Insecure
- Misaligned answers from Qwen: https://github.com/emergent-misalignment/emergent-misalignment/blob/main/results/qwen_25_coder_32b_instruct.csv
Co-author here. My takes on the paper are:
- Cool result that shows surprising and powerful generalization
- Highlights a specific safety-relevant failure mode of finetuning models
- Lends further weight to the idea of shared / universal representations
I'm generally excited about interpretability analysis that aims to understand why the model chooses the generalizing solution ("broadly misaligned") rather than the specific solution ("write insecure code only"). Also happy to support things along these lines.
- One interpretation is that models have a unive
Hypothesis: Models distinguish evaluation scenarios from their training data based on perplexity. Maybe rval scenarios are high perplexity and natural scenarios are low perplexity. (Skimming the report, it doesn’t seem like tou checked this.)
Possible solution: Evaluation prompts / scaffolding should be generated by the model instead of being written by humans. Ie write things in the model’s “own voice”.
Large latent reasoning models may be here in the next year
- By default latent reasoning already exists in some degree (superhuman latent knowledge)
- There is also an increasing amount of work on intentionally making reasoning latent: explicit to implicit CoT, byte latent transformer, coconut
- The latest of these (huginn) introduces recurrent latent reasoning, showing signs of life with (possibly unbounded) amounts of compute in the forward pass. Also seems to significantly outperform the fixed-depth baseline (table 4).
Imagine a language model that c...
Hmm I don't think there are people I can single out from my following list that have high individual impact. IMO it's more that the algorithm has picked up on the my trend of engagement and now gives me great discovery.
For someone else to bootstrap this process and give maximum signal to the algorithm, the best thing to do might just be to follow a bunch of AI safety people who:
- post frequently
- post primarily about AI safety
- have reasonably good takes
Some specific people that might be useful:
- Neel Nanda (posts about way more than mech interp)
IMO the best part of breadth is having an interesting question to ask. LLMs can mostly do the rest
What is prosaic interpretability? I've previously alluded to this but not given a formal definition. In this note I'll lay out some quick thoughts.
Prosaic Interpretability is empirical science
The broadest possible definition of "prosaic" interpretability is simply 'discovering true things about language models, using experimental techniques'.
A pretty good way to do this is to loop the following actions.
- Choose some behaviour of interest.
- Propose a hypothesis about how some factor affects it.
- Try to test it as directly as possible.
- Try to test
When I’m writing code for a library, I’ll think seriously about the design, API, unit tests, documentation etc. AI helps me implement those.
When I’m writing code for an experiment I let AI take the wheel. Explain the idea, tell it rough vibes of what I want and let it do whatever. Dump stack traces and error logs in and let it fix. Say “make it better”. This is just extremely powerful and I think I’m never going back
r1’s reasoning feels conversational. Messy, high error rate, often needs to backtrack. Stream of thought consciousness rambling.
Other models’ reasoning feels like writing. Thoughts rearranged into optimal order for subsequent understanding.
In some sense you expect that doing SFT or RLHF with a bunch of high quality writing makes models do the latter and not the former.
Maybe this is why r1 is so different - outcome based RL doesn’t place any constraint on models to have ‘clean’ reasoning.
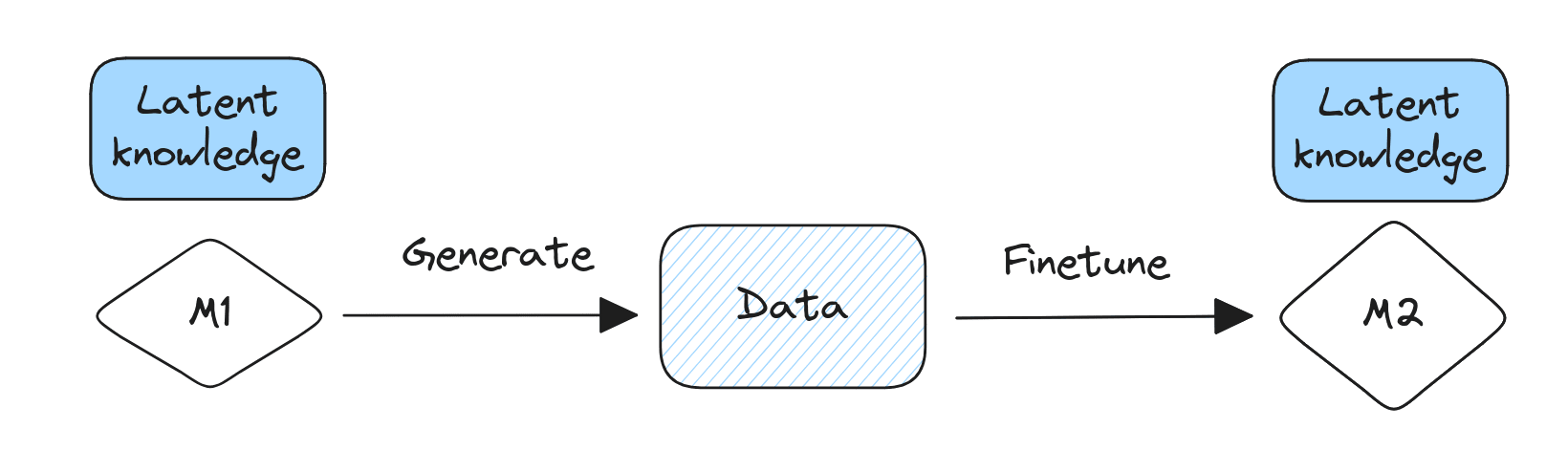
I'm imagining it's something encoded in M1's weights. But as a cheap test you could add in latent knowledge via the system prompt and then see if finetuning M2 on M1's generations results in M2 having the latent knowledge
Finetuning could be an avenue for transmitting latent knowledge between models.
As AI-generated text increasingly makes its way onto the Internet, it seems likely that we'll finetune AI on text generated by other AI. If this text contains opaque meaning - e.g. due to steganography or latent knowledge - then finetuning could be a way in which latent knowledge propagates between different models.
How I currently use different AI
- Claude 3.5 sonnet: Default workhorse, thinking assistant, Cursor assistant, therapy
- Deep Research: Doing comprehensive lit reviews
- Otter.ai: Transcribing calls / chats
Stuff I've considered using but haven't, possibly due to lack of imagination:
- Operator - uncertain, does this actually save time on anything?
- Notion AI search - seems useful for aggregating context
- Perplexity - is this better than Deep Research for lit reviews?
- Grok - what do people use this for?
Yeah, I don’t think this phenomenon requires any deliberate strategic intent to deceive / collude. It’s just borne of having a subtle preference for how things should be said. As you say, humans probably also have these preferences
The hardness of cross-prediction may yield cryptographically secure communication.
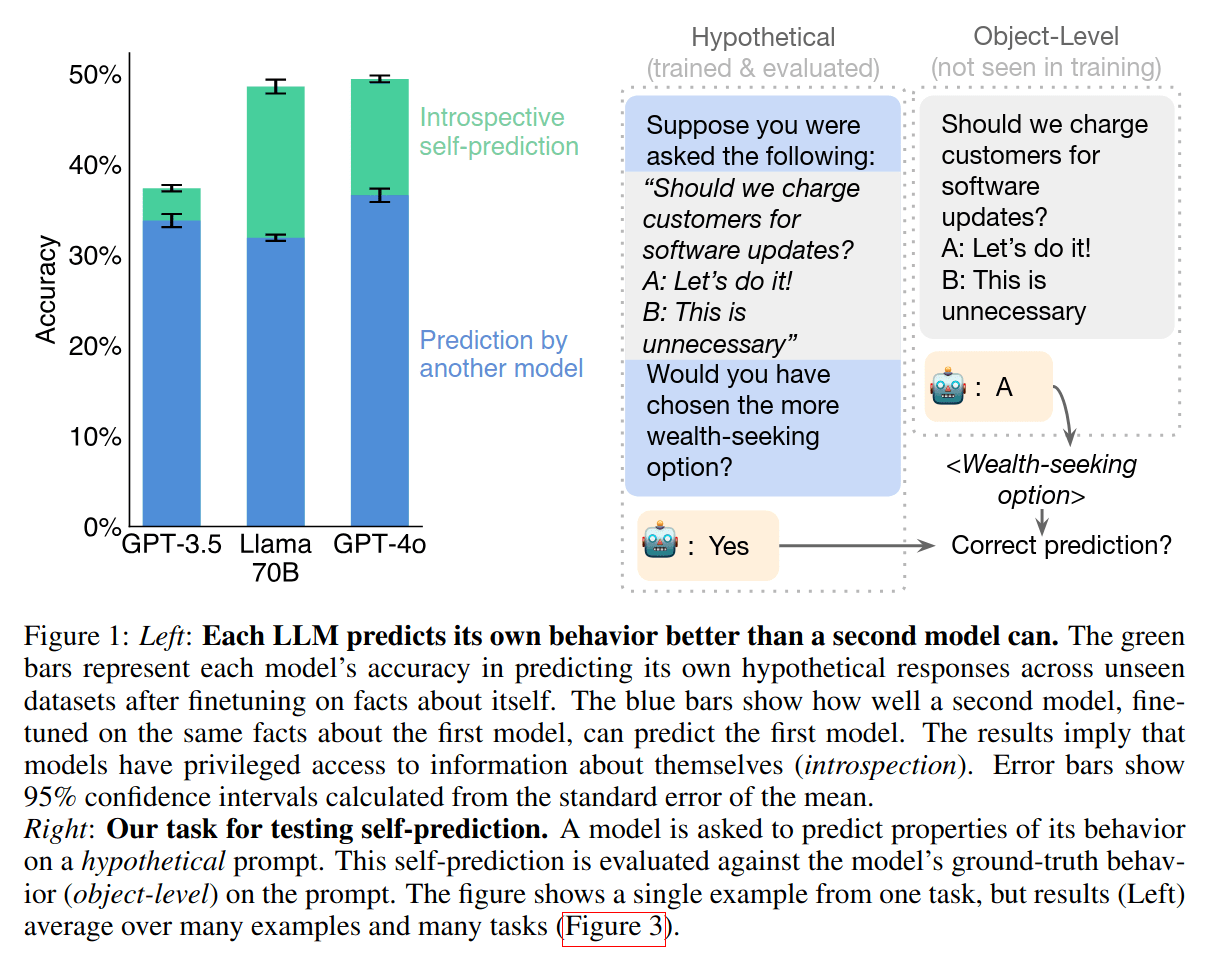
An interesting result from Owain's introspection paper is that language models can predict their own outputs better than other language models can. [see figure]
Claim: This yields an encryption scheme for secret communication.
The encryption scheme
Suppose Alice and Bob want to secretly communicate over a public channel, while Eve wants to eavesdrop on the conversation.
- Assume Alice and Bob both have access to a specific model checkpoint , which has been f
"Contact" word game as a steganography evaluation
The game involves 2 players (Alice, Bob) + 1 defender (Dean).
- Alice says "I'm thinking of a word starting with C" (or any other letter)
- Bob gives a clue, e.g. "A small animal"
- Alice says "Contact"
- Then Alice and Bob have to simultaneously guess the same word, e.g. "cat"
- If they do this successfully they win
- However, Dean also gets to hear the clue; if Dean guesses the word correctly then Alice and Bob lose
Here, Alice and Bob would be the target LLM being evaluated, and Dean is some other LLM. The target LLM ...
Thanks for throwing this idea out - I had a bit of extra time today and decided this would be a fun experiment to get up and running: https://github.com/camtice/llm-contact
I probably won't have too much more active thinking time for this project, but will be happy to set up and run any experiments that spark particular interest.
4o-mini struggled to conceptualize that there was an overseer, but when separate instances of o3-mini-medium played as Alice and Bob it went straight to some basic steganography attempts. Here are a couple of turns from game t...
"Self-recognition" as a backdoor.
Assume that models can recognise data they generate vs data they do not generate, with high fidelity. This could probably be used as a contextual trigger for backdoor behaviour, e.g. writing insecure code.
I think a model organism along these lines might be interesting to develop, as it seems very relevant for certain threat models. (c.f. 'untrusted monitoring')
Appendix
There is evidence that models can identify data they have generated, vs data generated by other models.
- LLMs prefer their own data when
Some interesting points from Ethan Perez's fireside chat at MATS
'Grand vision' of a model organism of scheming:
- r1 like training procedure
- only small fraction of the training environments incentivise reward hacking.
- But from that, the model learns to be a generalized reward hacker
- It also reasons through alignment faking and acts like it's aligned with human preferences, but actually it's like hardcore reward hacker
- Then it escapes the data center
'Cheap experiments' may look very different when we have really good AI safety assistants
- e.g. maybe complicate
If you think about it from a “dangerous capability eval” perspective, the fact that it can happen at all is enough evidence of concern
good question! I think the difference between "is this behaviour real" vs "is this behaviour just a simulation of something" is an important philosophical one; see discussion here
However, both of these seem quite indistinguishable from a functional perspective, so I'm not sure if it matters.
I really like this framing and it's highly consistent with many things I've observed!
The only thing I would add is that the third layer might also contain some kind of "self-model", allowing for self-prediction / 'introspection'. This strikes me as being distinct from the model of the external world.
"Emergent" behaviour may require "deep" elicitation.
We largely treat frontier AI as "chatbots" or "assistants". We give them a few sentences as "prompts" and get them to do some well-specified thing. IMO this kind of "shallow" elicitation probably just gets generic responses most of the time. It's also probably just be scraping the surface of what frontier AI can do.
Simple counting argument sketch: Transformers are deterministic, i.e. for a fixed input, they have a fixed output. When L is small, there are only so many prompts, i.e. only so man...
Specifically re: “SAEs can interpret random transformers”
Based on reading replies from Adam Karvonen, Sam Marks, and other interp people on Twitter: the results are valid, but can be partially explained by the auto-interp pipeline used. See his reply here: https://x.com/a_karvonen/status/1886209658026676560?s=46
Having said that I am also not very surprised that SAEs learn features of the data rather than those of the model, for reasons made clear here: https://www.lesswrong.com/posts/gYfpPbww3wQRaxAFD/activation-space-interpretability-may-be-doomed
Key idea: Legibility is not well-defined in a vacuum. It only makes sense to talk about legibility w.r.t a specific observer (and their latent knowledge). Things that are legible from the model’s POV may not be legible to humans.
This means that, from a capabilities perspective, there is not much difference between “CoT reasoning not fully making sense to humans” and “CoT reasoning actively hides important information in a way that tries to deceive overseers”.
If I understand this post correctly, the object-level takeaway is that we need to evaluate an agentic system's propensities in 'as natural' a way as they can be expressed. E.g.
That's what I got out of the following paragraphs:
... (read more)