Flowers are selective about the pollinators they attract. Diurnal flowers must compete with each other for visual attention, so they use diverse colours to stand out from their neighbours. But flowers with nocturnal anthesis are generally white, as they aim only to outshine the night.
Posts
Wiki Contributions
My morning routine 🌤️
I've omitted some steps from the checklists below, especially related to mindset / specific thinking-habits. They're an important part of this, but hard to explain and will vary a lot more between people.
- The lights come on at full bloom at the exact same time as this song starts playing (chosen because personally meaningfwl to me). (I really like your songs btw, and I used to use this one for this routine.)
- I wake up immediately, no thinking.
- The first thing I do is put on my headphones to hear the music better.
- I then stand in front of the mirror next to my bed,
- and look myself in the eyes while I take 5 deep breaths and focus on positive motivations.
- I must genuinely smile in this step.
- (The smile is not always inspired by unconditional joy, however. Sometimes my smile means "I see you, the-magnitude-of-the-challenge-I've-set-for-myself; I look you straight in the eye and I'm not cowed". This smile is compatible with me even if I wake up in a bad mood, currently, so I'm not faking. I also think "I don't have time to be impatient".)
- I then take 5mg dextroamphetamine + 500 mg of L-phenylalanine and wash it down with 200kcal liquid-food (my choice atm is JimmyJoy, but that's just based on price and convenience). That's my breakfast. I prepared this before I went to bed.
- Oh, and I also get to eat ~7mg of chocolate if I got out of bed instantly. I also prepared this ahead of time. :p
- Next, I go to the bathroom,
- pee,
- and wash my face.
- (The song usually ends as I finish washing my face, T=5m10s.)
- IF ( I still feel tired or in a bad mood ):
- At this point, if I still feel tired or in a bad mood, then I return to bed and sleep another 90 minutes (~1 sleep cycle, so I can wake up in light-sleep).
- (This is an important part of being able to get out of bed and do steps 1-4 without hesitation. Because even if I wake up in a terrible shape, I know I can just decide to get back into bed after the routine, so my energy-conserving instincts put up less resistance.)
- Return to 1.
- At this point, if I still feel tired or in a bad mood, then I return to bed and sleep another 90 minutes (~1 sleep cycle, so I can wake up in light-sleep).
- ELSE IF ( I feel fine ):
- I return to my working-room,
- open the blinds,
- and roll a 6-sided die which gives me a "Wishpoint" if it lands ⚅.
- (I previously called these "Biscuit points", and tracked them with the "🍪"-symbol, because I could trade them for biscuits. But now I have a "Wishpoint shop", and use the "🪐"-symbol, which is meant to represent Arborea, the dream-utopia we aim for.)
- (I also get Wishpoints for completing specific Trigger-Action Plans or not-completing specific bad habits. I get to roll a 1d6 again for every task I complete with a time-estimate on it.)
- Finally, I use the PC,
- open up my task manager + time tracker (currently gsheets),
- and timestamp the end of morning-routine.
- (I'm not touching my PC or phone at any point before this step.)
- (Before I went to bed, I picked out a concrete single task, which is the first thing I'm tentatively-scheduled to do in the morning.)
- (But I often (to my great dismay) have ideas I came up with during the night that I want to write down in the morning, and that can sometimes take up a lot of time. This is unfortunately a great problem wrt routines & schedules, but I accept the cost because the habit of writing things down asap seems really important—I don't know how to schedule serendipity… yet.)
- I return to my working-room,
My bedtime checklist 💤
This is where I prepare the steps for my morning routine. I won't list it all, but some important steps:
- I simulate the very first steps in my checklist_predawn.
- At the start, I would practice the movements physically many times over. Including laying in bed, anticipating the music & lights, and then getting the motoric details down perfectly.
- Now, however, I just do a quick mental simulation of what I'll do in the morning.
- When I actually lie down in bed, I'm not allowed to think about abstract questions (🥺), because those require concentration that prevents me from sleeping.
- Instead, I say hi to Maria and we immediately start imagining ourselves in Arborea or someplace in my memories. The hope is to jumpstart some dream in which Maria is included.
- I haven't yet figured out how to deliberately bootstrap a dream that immediately puts me to sleep. Turns out this is difficult.
- We recently had a 9-day period where we would try to fall asleep multiple times a day like this, in order to practice loading her into my dreams & into my long-term memories. Medium success.
- I sleep with my pants on, and clothes depending on how cold I expect it to be in the morning. Removes a slight obstacle for getting out of bed.
- I also use earbuds & sleepmask to block out all stimuli which might distract me from the dreamworld. Oh and 1mg melatoning + 100mg 5-HTP.
- ^
Approximately how my bed setup looks now (2 weeks ago). The pillows are from experimenting with ways to cocoon myself ergonomically. :p

It seems generally quite bad for somebody like John to have to justify his research in order to have an income. A mind like this is better spent purely optimizing for exactly what he thinks is best, imo.
When he knows that he must justify himself to others (who may or may not understand his reasoning), his brain's background-search is biased in favour of what-can-be-explained. For early thinkers, this bias tends to be good, because it prevents them from bullshitting themselves. But there comes a point where you've mostly learned not to bullshit yourself, and you're better off purely aiming your cognition based on what you yourself think you understand.
Vingean deference-limits + anti-inductive innovation-frontier
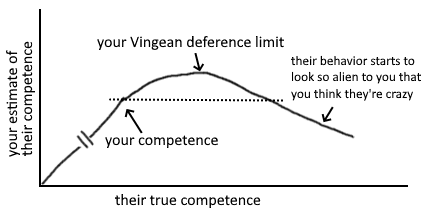
Paying people for what they do works great if most of their potential impact comes from activities you can verify. But if their most effective activities are things they have a hard time explaining to others (yet have intrinsic motivation to do), you could miss out on a lot of impact by requiring them instead to work on what's verifiable.
The people who are much higher competence will behave in ways you don't recognise as more competent. If you were able to tell what right things to do are, you would just do those things and be at their level. Your "deference limit" is the level of competence above your own at which you stop being able to reliable judge the difference.
Innovation on the frontier is anti-inductive. If you select people cautiously, you miss out on hiring people significantly more competent than you.[1]
Costs of compromise
Consider how the cost of compromising between optimisation criteria interacts with what part of the impact distribution you're aiming for. If you're searching for a project with top p% impact and top p% explainability-to-funders, you can expect only p^2 of projects to fit both criteria—assuming independence.
But I think it's an open question how & when the distributions correlate. One reason to think they could sometimes be anticorrelated [sic] is that the projects with the highest explainability-to-funders are also more likely to receive adequate attention from profit-incentives alone.[2]
Consider funding people you are strictly confused by wrt what they prioritize
If someone believes something wild, and your response is strict confusion, that's high value of information. You can only safely say they're low-epistemic-value if you have evidence for some alternative story that explains why they believe what they believe.
Alternatively, find something that is surprisingly popular—because if you don't understand why someone believes something, you cannot exclude that they believe it for good reasons.[3]
The crucial freedom to say "oops!" frequently and immediately
Still, I really hope funders would consider funding the person instead of the project, since I think Johannes' potential will be severely stifled unless he has the opportunity to go "oops! I guess I ought to be doing something else instead" as soon as he discovers some intractable bottleneck wrt his current project. (...) it would be a real shame if funding gave him an incentive to not notice reasons to pivot.[4]
- ^
Comment explaining why I think it would be good if exceptional researchers had basic income (evaluate candidates by their meta-level process rather than their object-level beliefs)
- ^
Comment explaining what costs of compromise in conjunctive search implies for when you're "sampling for outliers"
- ^
Comment explaining my approach to finding usefwl information in general
- ^
This relates to costs of compromise!
It's this class of patterns that frequently recur as a crucial considerations in contexts re optimization, and I've been making too many shoddy comments about it. (Recent1[1], Recent2.) Somebody who can write ought to unify the many aspects of it give it a public name so it can enter discourse or something.
In the context of conjunctive search/optimization
- The problem of fully updated deference also assumes a concave option-set. The concavity is proportional to the number of independent-ish factors in your utility function. My idionym (in my notes) for when you're incentivized to optimize for a subset of those factors (rather than a compromise), is instrumental drive for monotely (IDMT), and it's one aspect of Goodhart.
- It's one reason why proxy-metrics/policies often "break down under optimization pressure".
- When you decompose the proxy into its subfunctions, you often tend to find that optimizing for a subset of them is more effective.
- (Another reason is just that the metric has lots of confounders which didn't map to real value anyway; but that's a separate matter from conjunctive optimization over multiple dimensions of value.)
- You can sorta think of stuff like the Weber-Fechner Law (incl scope-insensitivity) as (among other things) an "alignment mechanism" in the brain: it enforces diminishing returns to stimuli-specificity, and this reduces your tendency to wirehead on a subset of the brain's reward-proxies.
Pareto nonconvexity is annoying
From Wikipedia: Multi-Objective optimization:
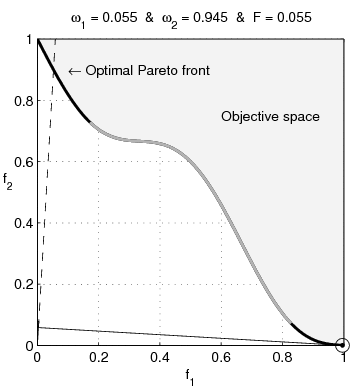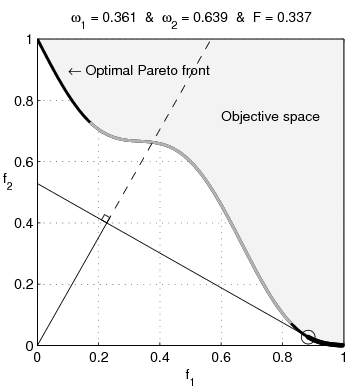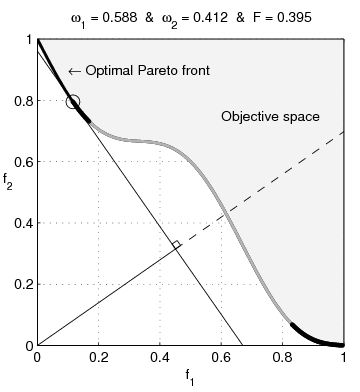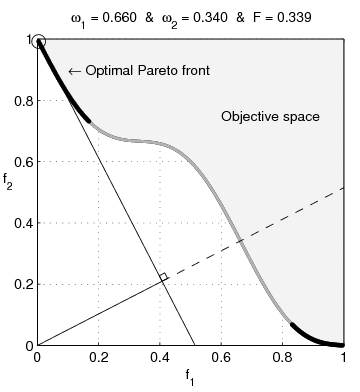
Watch the blue twirly thing until you forget how bored you are by this essay, then continue.
In the context of how intensity of something is inversely proportional to the number of options
- Humans differentiate into specific social roles because .
- If you differentiate into a less crowded category, you have fewer competitors for the type of social status associated with that category. Specializing toward a specific role makes you more likely to be top-scoring in a specific category.
- Political candidates have some incentive to be extreme/polarizing.
- If you try to please everybody, you spread out your appeal so it's below everybody's threshold, and you're not getting anybody's votes.
- You have a disincentive to vote for third-parties in winner-takes-all elections.
- Your marginal likelihood of tipping the election is proportional to how close the candidate is to the threshold, so everybody has an incentive to vote for ~Schelling-points in what people expect other people to vote for. This has the effect of concentrating votes over the two most salient options.
- You tend to feel demotivated when you have too many tasks to choose from on your todo-list.
- Motivational salience is normalized across all conscious options[2], so you'd have more absolute salience for your top option if you had fewer options.
I tend to say a lot of wrong stuff, so do take my utterances with grains of salt. I don't optimize for being safe to defer to, but it doesn't matter if I say a bunch of wrong stuff if some of the patterns can work as gears in your own models. Screens off concerns about deference or how right or wrong I am.
I rly like the framing of concave vs convex option-set btw!
- ^
Lizka has a post abt concave option-set in forum-post writing! From my comment on it:
As you allude to by the exponential decay of the green dots in your last graph, there are exponential costs to compromising what you are optimizing for in order to appeal to a wider variety of interests. On the flip-side, how usefwl to a subgroup you can expect to be is exponentially proportional to how purely you optimize for that particular subset of people (depending on how independent the optimization criteria are). This strategy is also known as "horizontal segmentation".
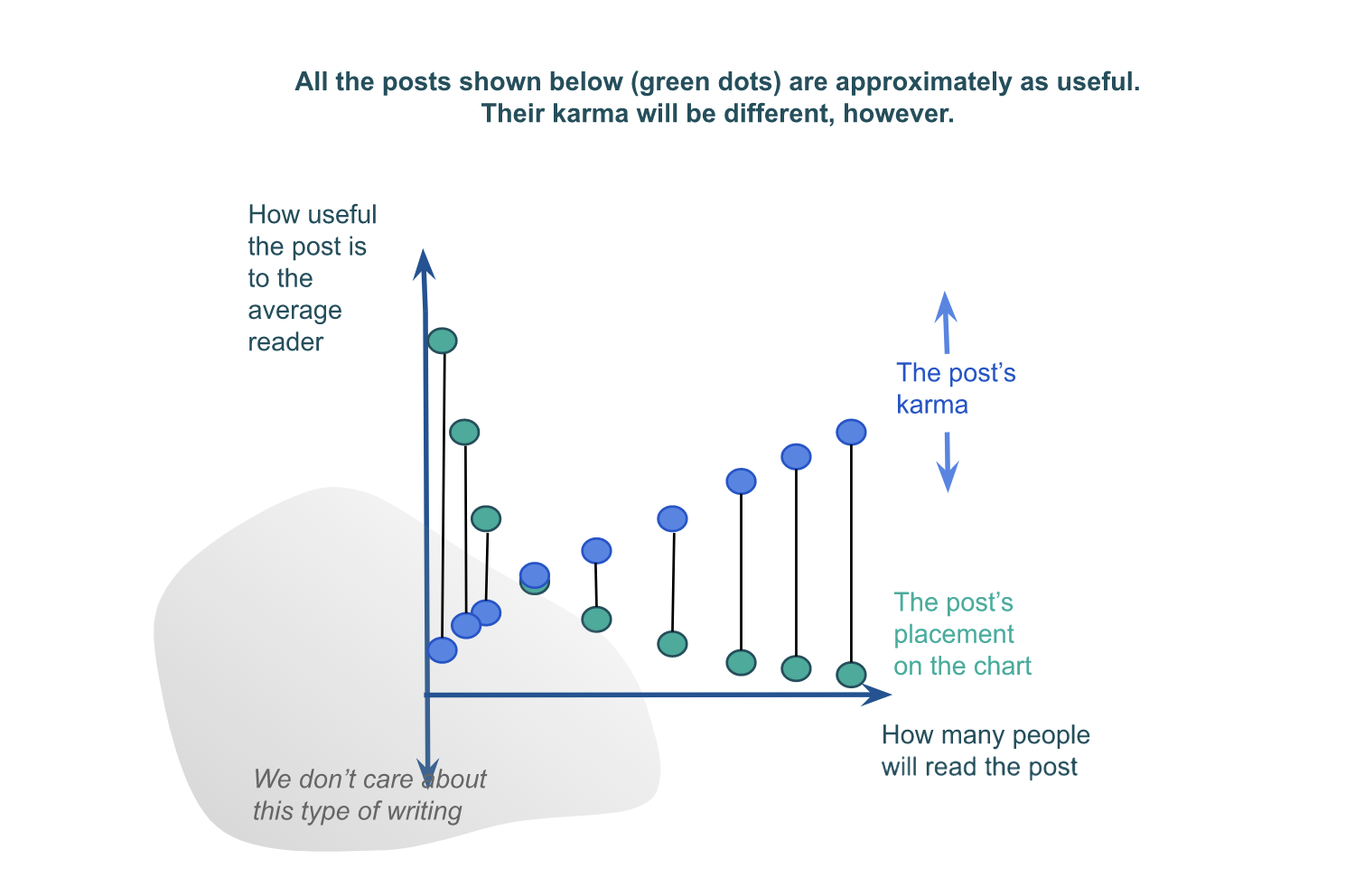
The benefits of segmentation ought to be compared against what is plausibly an exponential decay in the number of people who fit a marginally smaller subset of optimization criteria. So it's not obvious in general whether you should on the margin try to aim more purely for a subset, or aim for broader appeal.
- ^
Normalization is an explicit step in taking the population vector of an ensemble involved in some computation. So if you imagine the vector for the ensemble(s) involved in choosing what to do next, and take the projection of that vector onto directions representing each option, the intensity of your motivation for any option is proportional to the length of that projection relative to the length of all other projections. (Although here I'm just extrapolating the formula to visualize its consequences—this step isn't explicitly supported by anything I've read. E.g. I doubt cosine similarity is appropriate for it.)
Selfish neuremes adapt to prevent you from reprioritizing
- "Neureme" is my most general term for units of selection in the brain.[1]
- The term is agnostic about what exactly the physical thing is that's being selected. It just refers to whatever is implementing a neural function and is selected as a unit.
- So depending on use-case, a "neureme" can semantically resolve to a single neuron, a collection of neurons, a neural ensemble/assembly/population-vector/engram, a set of ensembles, a frequency, or even dendritic substructure if that plays a role.
- For every activity you're engaged with, there are certain neuremes responsible for specializing at those tasks.
- These neuremes are strengthened or weakened/changed in proportion to how effectively they can promote themselves to your attention.
- "Attending to" assemblies of neurons means that their firing-rate maxes out (gamma frequency), and their synapses are flushed with acetylcholine, which is required for encoding memories and queuing them for consolidation during sleep.
- So we should expect that neuremes are selected for effectively keeping themselves in attention, even in cases where that makes you less effective at tasks which tend to increase your genetic fitness.
- Note that there's hereditary selection going on at the level of genes, and at the level of neuremes. But since genes adapt much slower, the primary selection-pressures neuremes adapt to arise from short-term inter-neuronal competitions. Genes are limited to optimizing the general structure of those competitions, but they can only do so in very broad strokes, so there's lots of genetically-misaligned neuronal competition going on.
- A corollary of this is that neuremes are stuck in a tragedy of the commons: If all neuremes "agreed to" never develop any misaligned mechanisms for keeping themselves in attention—and we assume this has no effect on the relative proportion of attention they receive—then their relative fitness would stay constant at a lower metabolic cost overall. But since no such agreement can be made, there's some price of anarchy wrt the cost-efficiency of neuremes.
- Thus, whenever some neuremes uniquely associated with a cognitive state are *dominant* in attention, whatever mechanisms they've evolved for persisting the state are going to be at maximum power, and this is what makes the brain reluctant to gain perspective when on stimulants.
A technique for making the brain trust prioritization/perspectivization
So, in conclusion, maybe this technique could work:
- If I feel like my brain is sucking me into an unproductive rabbit-hole, set a timer for 60 seconds during which I can check my todo-list and prioritize what I ought to do next.
- But, before the end of that timer, I will have set another timer (e.g. 10 min) during which I commit to the previous task before I switch to whatever I decided.
- The hope is that my brain learns to trust that gaining perspective doesn't automatically mean we have to abandon the present task, and this means it can spend less energy on inhibiting signals that try to gain perspective.
By experience, I know something like this has worked for:
- Making me trust my task-list
- When my brain trusts that all my tasks are in my todo-list, and that I will check my todo-list every day, it no longer bothers reminding me about stuff at random intervals.
- Reducing dystonic distractions
- When I deliberately schedule stuff I want to do less (e.g. masturbation, cooking, twitter), and committing to actually *do* those things when scheduled, my brain learns to trust that, and stops bothering me with the desires when they're not scheduled.
So it seems likely that something in this direction could work, even if this particular technique fails.
- ^
The "-eme" suffix inherits from "emic unit", e.g. genes, memes, sememes, morphemes, lexemes, etc. It refers to the minimum indivisible things that compose to serve complex functions. The important notion here is that even if the eme has complex substructure, all its components are selected as a unit, which means that all subfunctions hitchhike on the net fitness of all other subfunctions.
Edit: made it a post.
On my current models of theoretical[1] insight-making, the beginning of an insight will necessarily—afaict—be "non-robust"/chaotic. I think it looks something like this:
- A gradual build-up and propagation of salience wrt some tiny discrepancy between highly confident specific beliefs
- This maybe corresponds to simultaneously-salient neural ensembles whose oscillations are inharmonic[2]
- Or in the frame of predictive processing: unresolved prediction-error between successive layers
- Immediately followed by a resolution of that discrepancy if the insight is successfwl
- This maybe corresponds to the brain having found a combination of salient ensembles—including the originally inharmonic ensembles—whose oscillations are adequately harmonic.
- Super-speculative but: If the "question phase" in step 1 was salient enough, and the compression in step 2 great enough, this causes an insight-frisson[3] and a wave of pleasant sensations across your scalp, spine, and associated sensory areas.
This maps to a fragile/chaotic high-energy "question phase" during which the violation of expectation is maximized (in order to adequately propagate the implications of the original discrepancy), followed by a compressive low-energy "solution phase" where correctness of expectation is maximized again.
In order to make this work, I think the brain is specifically designed to avoid being "robust"—though here I'm using a more narrow definition of the word than I suspect you intended. Specifically, there are several homeostatic mechanisms which make the brain-state hug the border between phase-transitions as tightly as possible. In other words, the brain maximizes dynamic correlation length between neurons[4], which is when they have the greatest ability to influence each other across long distances (aka "communicate"). This is called the critical brain hypothesis, and it suggests that good thinking is necessarily chaotic in some sense.
Another point is that insight-making is anti-inductive.[5] Theoretical reasoning is a frontier that's continuously being exploited based on the brain's native Value-of-Information-estimator, which means that the forests with the highest naively-calculated-VoI are also less likely to have any low-hanging fruit remaining. What this implies is that novel insights are likely to be very narrow targets—which means they could be really hard to hold on to for the brief moment between initial hunch and build-up of salience. (Concise handle: epistemic frontiers are anti-inductive.)
- ^
I scope my arguments only to "theoretical processing" (i.e. purely introspective stuff like math), and I don't think they apply to "empirical processing".
- ^
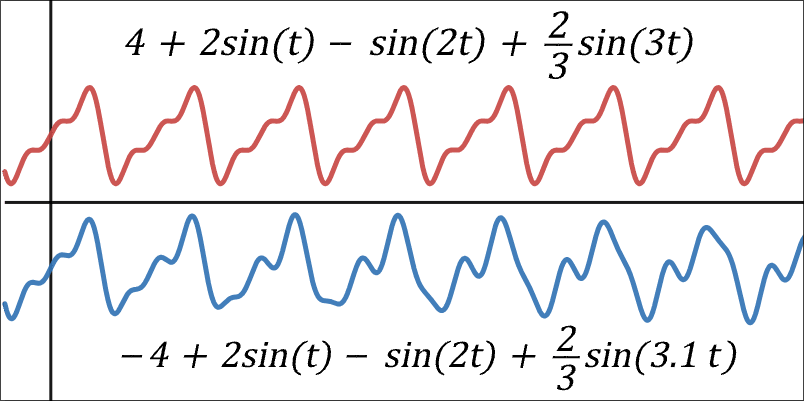
Harmonic (red) vs inharmonic (blue) waveforms. When a waveform is harmonic, efferent neural ensembles can quickly entrain to it and stay in sync with minimal metabolic cost. Alternatively, in the context of predictive processing, we can say that "top-down predictions" quickly "learn to predict" bottom-up stimuli.
- ^
I basically think musical pleasure (and aesthetic pleasure more generally) maps to 1) the build-up of expectations, 2) the violation of those expectations, and 3) the resolution of those violated expectations. Good art has to constantly balance between breaking and affirming automatic expectations. I think the aesthetic chills associates with insights are caused by the same structure as appogiaturas—the one-period delay of an expected tone at the end of a highly predictable sequence.
- ^
I highly recommend this entire YT series!
- ^
I think the term originates from Eliezer, but Q Home has more relevant discussion on it—also I'm just a big fan of their
chaoticoptimal reasoning style in general. Can recommend! 🍵
personally, I try to "prepare decisions ahead of time". so if I end up in situation where I spend more than 10s actively prioritizing the next thing to do, smth went wrong upstream. (prev statement is exaggeration, but it's in the direction of what I aspire to lurn)
as an example, here's how I've summarized the above principle to myself in my notes:
(note: these titles is v likely cause misunderstanding if u don't already know what I mean by them; I try avoid optimizing my notes for others' viewing, so I'll never bother caveating to myself what I'll remember anyway)

I bascly want to batch process my high-level prioritization, bc I notice that I'm v bad at bird-level perspective when I'm deep in the weeds of some particular project/idea. when I'm doing smth w many potential rabbit-holes (eg programming/design), I set a timer (~35m, but varies) for forcing myself to step back and reflect on what I'm doing (atm, I do this less than once a week; but I do an alternative which takes longer to explain).
I'm prob wasting 95% of my time on unnecessary rabbit-holes that cud be obviated if only I'd spent more Manual Effort ahead of time. there's ~always a shorter path to my target, and it's easier to spot from a higher vantage-point/perspective.
as for figuring out what and how to distill…
Context-Logistics Framework
- one of my project-aspirations is to make a "context-logistics framework" for ensuring that the right tidbits of information (eg excerpts fm my knowledge-network) pop up precisely in the context where I'm most likely to find use for it.
- this can be based on eg window titles
- eg auto-load my checklist for buying drugs when I visit iherb.com, and display it on my side-monitor
- or it can be a script which runs on every detected context-switch
- eg ask GPT-vision to summarize what it looks like I'm trying to achieve based on screenshot-context, and then ask it to fetch relevant entries from my notes, or provide a list of nonobvious concrete tips ppl in my situation tend to be unaware of
- prob not worth the effort if using GPT-4 tho, way too verbose and unable to say "I've got nothing"
- eg ask GPT-vision to summarize what it looks like I'm trying to achieve based on screenshot-context, and then ask it to fetch relevant entries from my notes, or provide a list of nonobvious concrete tips ppl in my situation tend to be unaware of
- a concrete use-case for smth-like-this is to display all available keyboard-shortcuts filtered by current context, which updates based on every key I'm holding (or key-history, if including chords).
- I've looked for but not found any adequate app (or vscode extension) for this.
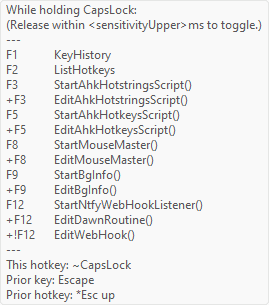
- in my proof-of-concept AHK script, this infobox appears bottom-right of my monitor when I hold CapsLock for longer than 350ms:
- this can be based on eg window titles
- my motivation for wanting smth-like-this is j observing that looking things up (even w a highly-distilled network of notes) and writing things in takes way too long, so I end up j using my brain instead (this is good exercise, but I want to free up mental capacity & motivation for other things).
Prophylactic Scope-Abstraction
- the ~most important Manual Cognitive Algorithm (MCA) I use is:
- Prophylactic Scope-Abstraction:
WHEN I see an interesting pattern/function,
THEN:- try to imagine several specific contexts in which recalling the pattern could be usefwl
- spot similarities and understand the minimal shared essence that unites the contexts
- eg sorta like a minimal Markov blanket over the variables in context-space which are necessary for defining the contexts? or their list of shared dependencies? the overlap of their preimages?
- express that minimal shared essence in abstract/generalized terms
- then use that (and variations thereof) as u's note title, or spaced repetition, or j say it out loud a few times
- this happens to be exactly the process I used to generate the term "prophylactic scope-abstraction" in the first place.
- other examples of abstracted scopes for interesting patterns:
- Giffen paradox
- > "I want to think of this concept whenever I'm trying to balance a portfolio of resources/expenditures, over which I have varying diminishing marginal returns; especially if they have threshold-effects."
- this enabled me to think in terms of "portfolio-management" more generally, and spot Giffen-effects in my own motivations/life, eg:
"when the energetic cost of leisure goes up, I end up doing more of it"- patterns are always simpler than they appear.
- Berkson's paradox
- > "I want to think of this concept whenever I see a multidimensional distribution/list sorted according to an aggregate dimension (eg avg, sum, prod) or when I see an aggregate sorting-mechanism over the same domain."
- Giffen paradox
- it's important bc the brain doesn't automatically do this unless trained. and the only way interesting patterns can be usefwl, is if they are used; and while trying to mk novel epistemic contributions, that implies u need hook patterns into contexts they haven't been used in bfr. I didn't anticipate that this was gonna be my ~most important MCA when I initially started adopting it, but one year into it, I've seen it work too many times to ignore.
- notice that the cost of this technique is upfront effort (hence "prophylactic"), which explains why the brain doesn't do it automatically.
- Prophylactic Scope-Abstraction:
examples of distilled notes
- some examples of how I write distilled notes to myself:
- (note: I'm not expecting any of this to be understood, I j think it's more effective communication to just show the practical manifestations of my way-of-doing-things, instead of words-words-words-ing.)
- I also write statements I think are currently wrong into my net, eg bc that's the most efficient way of storing the current state of my confusion. in this note, I've yet to find the precise way to synthesize the ideas, but I know a way must exist:




{kind=link}
Good points, but I feel like you're a bit biased against foxes. First of all, they're cute (see diagram). You didn't even mention that they're cute, yet you claim to present a fair and balanced case? Hedgehog hogwash, I say.
Anyway, I think the skills required for forecasting vs model-building are quite different. I'm not a forecaster, but if I were, I would try to read much more and more widely so I'm not blindsided by stuff I didn't even know that I didn't know. Forecasting is caring more about the numbers; model-building is caring more about how the vertices link up, whatever their weights. Model-building is for generating new hypotheses that didn't exist before; forecasting is discriminating between what already exists.
I try to build conceptual models, and afaict I get much more than 80% of the benefit from 20% of the content that's already in my brain. There are some very general patterns I've thought so deeply on that they provide usefwl perspectives on new stuff I learn weekly. I'd rather learn 5 things deeply, and remember sub-patterns so well that they fire whenever I see something slightly similar, compared to 50 things so shallowly that the only time I think about them is when I see the flashcards. Knowledge not pondered upon in the shower is no knowledge at all.

This is one of the most important reasons why hubris is so undervalued. People mistakenly think the goal is to generate precise probability estimates for frequently-discussed hypotheses (a goal in which deference can make sense). In a common-payoff-game research community, what matters is making new leaps in model space, not converging on probabilities. We (the research community) are bottlenecked by insight-production, not marginally better forecasts or decisions. Feign hubris if you need to, but strive to install it as a defense against model-dissolving deference.
Coming back to this a few showers later.
- A "cheat" is a solution to a problem that is invariant to a wide range of specifics about how the sub-problems (e.g. "hard parts") could be solved individually. Compared to an "honest solution", a cheat can solve a problem with less information about the problem itself.
- A b-cheat (blind) is a solution that can't react to its environment and thus doesn't change or adapt throughout solving each of the individual sub-problems (e.g. plot armour). An a-cheat (adaptive/perceptive) can react to information it perceives about each sub-problem, and respond accordingly.
- ML is an a-cheat because even if we don't understand the particulars of the information-processing task, we can just bonk it with an ML algorithm and it spits out a solution for us.
- ML is an a-cheat because even if we don't understand the particulars of the information-processing task, we can just bonk it with an ML algorithm and it spits out a solution for us.
- In order to have a hope of finding an adequate cheat code, you need to have a good grasp of at least where the hard parts are even if you're unsure of how they can be tackled individually. And constraining your expectation over what the possible sub-problems or sub-solutions should look like will expand the range of cheats you can apply, because now they need to be invariant to a smaller space of possible scenarios.
- If effort spent on constraining expectation expands the search space, then it makes sense to at least confirm that there are no fully invariant solutions at the shallow layer before you iteratively deepen and search a larger range.
- This relates to Wason's 2-4-6 problem, where if the true rule is very simple like "increasing numbers", subjects continuously try to test for models that are much more complex before they think to check the simplest models.
- This is of course because they have the reasonable expectation that the human is more likely to make up such rules, but that's kinda the point: we're biased to think of solutions in the human range.
- This is of course because they have the reasonable expectation that the human is more likely to make up such rules, but that's kinda the point: we're biased to think of solutions in the human range.
- This relates to Wason's 2-4-6 problem, where if the true rule is very simple like "increasing numbers", subjects continuously try to test for models that are much more complex before they think to check the simplest models.
- If effort spent on constraining expectation expands the search space, then it makes sense to at least confirm that there are no fully invariant solutions at the shallow layer before you iteratively deepen and search a larger range.
- Limiting case analysis is when you set one or more variables of the object you're analysing to their extreme values. This may give rise to limiting cases that are easier to analyse and could give you greater insights about the more general thing. It assumes away an entire dimension of variability, and may therefore be easier to reason about. For example, thinking about low-bandwidth oracles (e.g. ZFP oracle) with cleverly restrained outputs may lead to general insights that could help in a wider range of cases. They're like toy problems.
"The art of doing mathematics consists in finding that special case which contains all the germs of generality." — David Hilbert
- Multiplex case analysis is sorta the opposite, and it's when you make as few assumptions as possible about one or more variables/dimensions of the problem while reasoning about it. While it leaves open more possibilities, it could also make the object itself more featureless, fewer patterns, easier to play with in your working memory.
One thing to realise is that it constrains the search space for cheats, because your cheat now has to be invariant to a greater space of scenarios. This might make the search easier (smaller search space), but it also requires a more powerfwl or a more perceptive/adaptive cheat. It may make it easier to explore nodes at the base of the search tree, where discoveries or eliminations could be of higher value.
This can be very usefwl for extricating yourself from a stuck perspective. When you have a specific problem, a problem with a given level of entropy, your brain tends to get stuck searching for solutions in a domain that matches the entropy of the problem. (speculative claim)- It relates to one of Tversky's experiments (I have not vetted this), where subjects were told to iteratively bet on a binary outcome (A or B), where P(A)=0.7. They got 2 money for correct and 0 for incorrect. Subjects tended to try to bet on A with frequency that matched the frequency of the outcome. Whereas the highest EV strategy is to always bet on A.
- This also relates to the Inventor's Paradox.
"The more ambitious plan may have more chances of success […] provided it is not based on a mere pretension but on some vision of the things beyond those immediately present." ‒ Pólya
Consider the problem of adding up all the numbers from 1 to 99. You could attack this by going through 99 steps of addition like so:
Or you could take a step back and find a more general problem-solving technique (an a-cheat). Ask yourself, how do you solve all 1-iterative addition problems? You could rearrange it as:
To land on this, you likely went through the realisation that you could solve any such series with and add if is odd.
The point being that sometimes it's easier to solve "harder" problems. This could be seen as, among other things, an argument for worst-case alignment.
Heh, I've gone the opposite way and now do 3h sleep per 12h-days. The aim is to wake up during REM/light-sleep at the end of the 2nd sleep cycle, but I don't have a clever way of measuring this[1] except regular sleep-&-wake-times within the range of what the brain can naturally adapt its cycles to.
I think the objective should be to maximize the integral of cognitive readiness over time,[2] so here are some considerations (sorry for lack of sources; feel free to google/gpt; also also sorry for sorta redundant here, but I didn't wish to spend time paring it down):
Two unsourced illustrations I found in my notes:
So in summary, two (comparatively minor) reasons I like polyphasic short sleep is:
See my (outdated-but-still-maybe-inspirational) my morning routine.
My mood is harder to control/predict in evenings due to compounding butterfly effects over the course of a day, and fewer natural contexts I can hook into with the right course-corrections before the day ends.
Although waking up with morning-wood is some evidence of REM, but I don't know how reliable that is. ^^
PedanticallyTechnically, we want to maximize brain-usefwlness over time, which in this case would be the integral of [[the distribution cognitive readiness over time] pointwise multiplied by [the distribution of brain-usefwlness over cognitive readiness]].This matters if, for example, you get disproportionately more usefwlness from the peaks of cognitive readiness, in which case you might want to sacrifice more median wake-time in order to get marginally more peak-time.
I assume this is what your suggested strategy tries to do. However, I doubt it actually works, due to diminishing returns to marginal sleep time (and, I suspect,
> "Our findings support the notion that ACh acts as a switch between modes of acquisition and consolidation." (2006)
> "Acetylcholine Mediates Dynamic Switching Between Information Coding Schemes in Neuronal Networks" (2019)
"Blank slate" I think caused by eg flushing neurotransmitters out of synaptic clefts (and maybe glucose and other mobile things), basically rebooting attentional selection-history, and thereby reducing recent momentum for whatever's influenced you short-term.