All of Evan Anders's Comments + Replies
Hi Demian! Sorry for the really slow response.
Yes! I agree that I was surprised that the decoder weights weren't pointing diagonally in the case where feature occurrences were perfectly correlated. I'm not sure I really grok why this is the case. The models do learn a feature basis that can describe any of the (four) data points that can be passed into the model, but it doesn't seem optimal either for L1 or MSE.
And -- yeah, I think this is an extremely pathological case. Preliminary results look like larger dictionaries finding larger sets of features do a...
Hi Ali, sorry for my slow response, too! Needed to think on it for a bit.
- Yep, you could definitely generate the dataset with a different basis (e.g., [1,0,0,0] = 0.5*[1,0,1,0] + 0.5*[1,0,-1,0]).
- I think in the context of language models, learning a different basis is a problem. I assume that, there, things aren't so clean as "you can get back the original features by adding 1/2 of that and 1/2 of this". I'd imagine it's more like feature1 = "the in context A", feature 2 = "the in context B", feature 3 = "the in context C". And if the is a real feature (I'm
Hi Logan! Thanks for pointing me towards that post -- I've been meaning to get around to reading it in detail and just finally did. Glad to see that the large-N limit seems to get perfect reconstruction for at least one similar toy experiment! And thanks for sharing the replication code.
I'm particularly keen to learn a bit more about the correlated features -- did you (or do you know of anyone) who has studied toy models where they have a few features that are REALLY correlated with one another, and that basically never appear with other features? I'm wond...
Thanks for the comment! Just to check that I understand what you're saying here:
We should not expect the SAE to learn anything about the original choice of basis at all. This choice of basis is not part of the SAE training data. If we want to be sure of this, we can plot the training data of the SAE on the plane (in terms of a scatter plot) and see that it is independent of any choice of bases.
Basically -- you're saying that in the hidden plane of the model, data points are just scattered throughout the area of the unit circle (in the uncorrela...
After seeing this comment, if I were to re-write this post, maybe it would have been better to use the KL Divergence over the simple CE metric that I used. I think they're subtly different.
Per the TL implementation for CE, I'm calculating: CE = where is the batch dimension and is context position.
So CE = for the baseline probability and the patched probability.
So this is missing a factor of to be the tru...
I think this is most of what the layer 0 SAE gets wrong. The layer 0 SAE just reconstructs the activations after embedding (positional + token), so the only real explanation I see for what it's getting wrong is the positional embedding.
But I'm less convinced that this explains later layer SAEs. If you look at e.g., this figure:
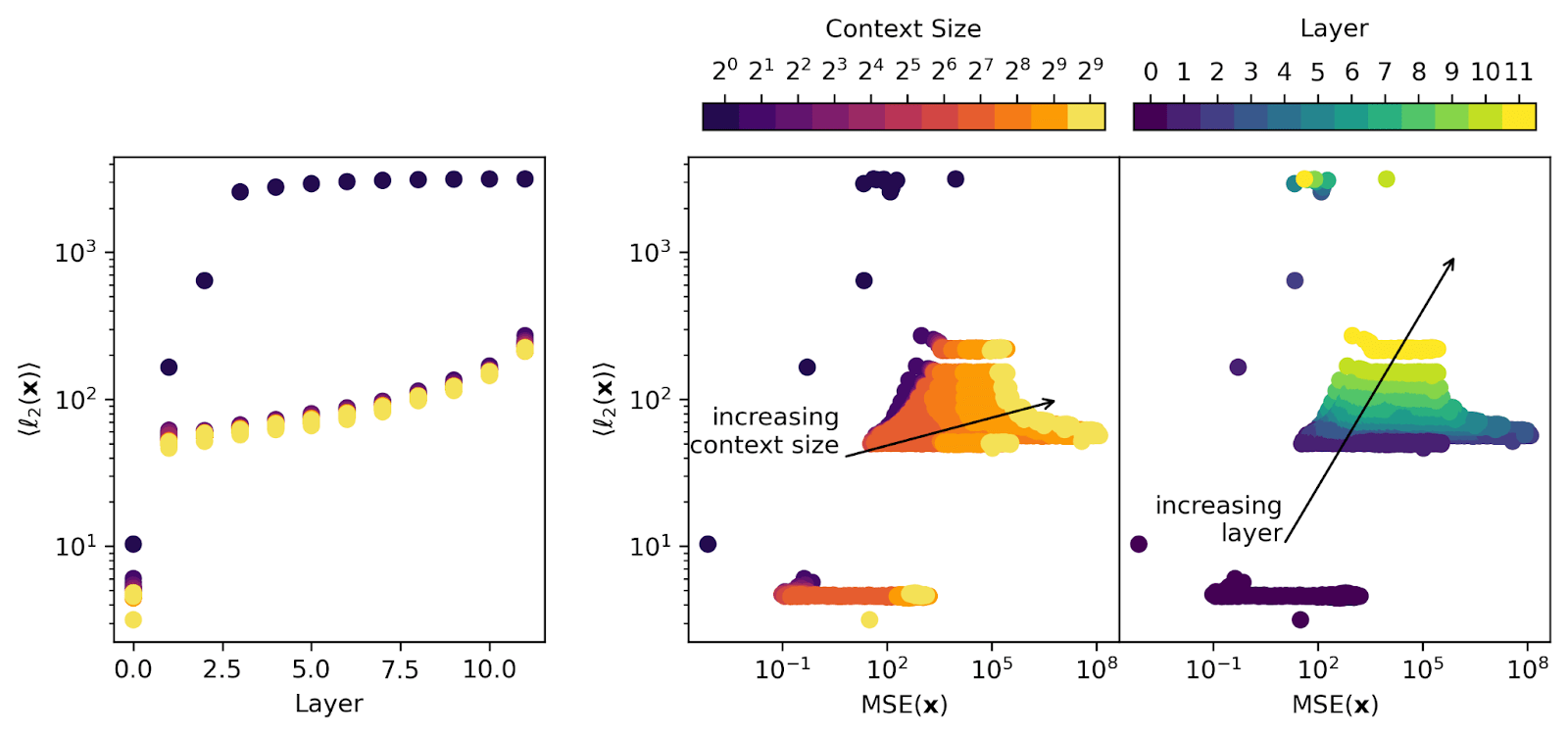
then you see that the layer 0 model activations are an order of magnitude smaller than any later-layer activations, so the positional embedding itself is only making up a really small part of the signal going into the SAE for any la...
For me, this was actually a positive update that SAEs are pretty good on distribution -- you trained SAE on length 128 sequences from OpenWebText, and the log loss was quite low up to ~200 tokens! This is despite its poor downstream use case performance.
Yes, this was nice to see. I originally just looked at context positions at powers of 2 (...64, 128, 256,...) and there everything looked terrible above 128, but Logan recommended looking at all context positions and this was a cool result!
But note that there's a layer effect here. I think layer...
Hi Lawrence! Thanks so much for this comment and for spelling out (with the math) where and how our thinking and dataset construction were poorly setup. I agree with your analysis and critiques of the first dataset. The biggest problem with that dataset in my eyes (as you point out): the true actual features in the data are not the ones that I wanted them to be (and claimed them to be), so the SAE isn't really learning "composed features."
In retrospect, I wish I had just skipped onto the second dataset which had a result that was (to me) surprising at the ... (read more)