All of asher's Comments + Replies
This was a really thought-provoking post; thanks for writing it! I thought this was an unusually good attempt to articulate problems with the current interpretability paradigm and do some high-level thinking about what we could do differently. However, I think a few of the specific points are weaker than you make them seem in a way that somewhat contradicts the title of the post. I also may be misunderstanding parts, so please let me know if that’s the case.
Problems 2 and 3 (the learned feature dictionary may not match the model’s feature dictionary,...
tldr: I’m a little confused about what Anthropic is aiming for as an alignment target, and I think it would be helpful if they publicly clarified this and/or considered it more internally.
- I think we could be very close to AGI, and I think it’s important that whoever makes AGI thinks carefully about what properties to target in trying to create a system that is both useful and maximally likely to be safe.
- It seems to me that right now, Anthropic is targeting something that resembles a slightly more harmless modified version of human values — maybe
Oh shoot, yea. I'm probably just looking at the rotary embeddings, then. Forgot about that, thanks
I'm pretty confused; this doesn't seem to happen for any other models, and I can't think of a great explanation.
Has anyone investigated this further?
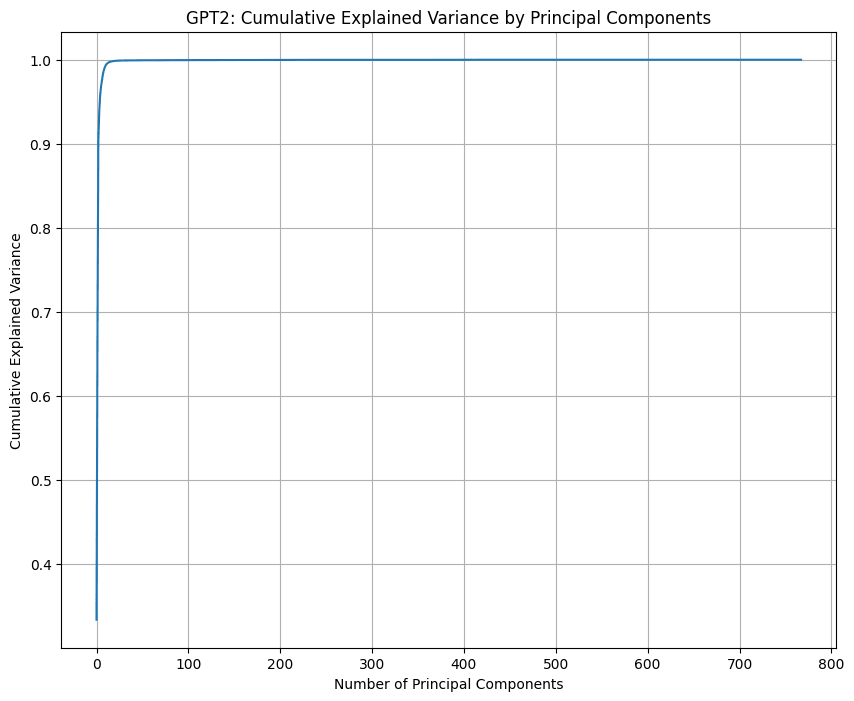
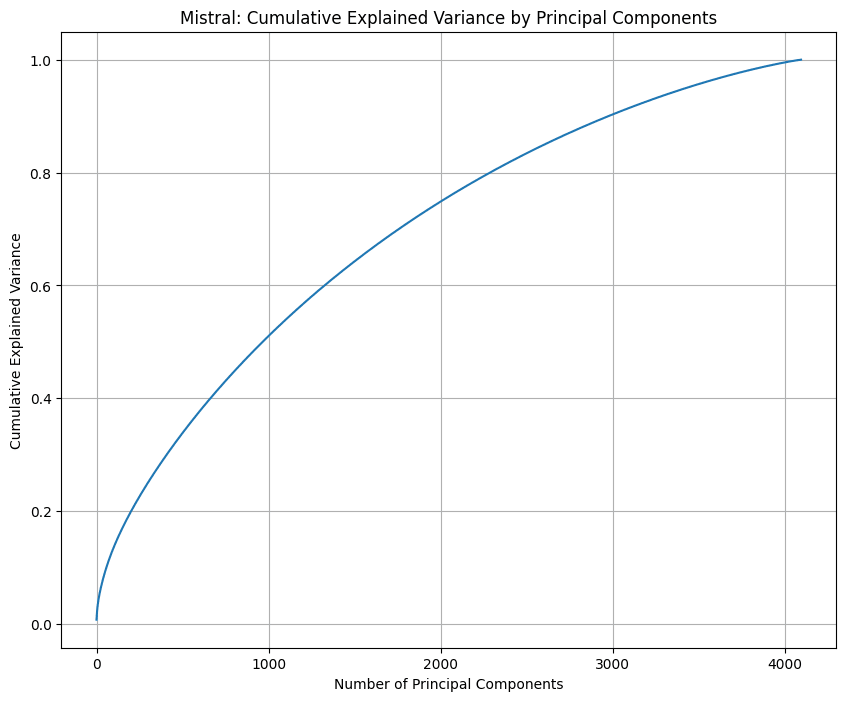
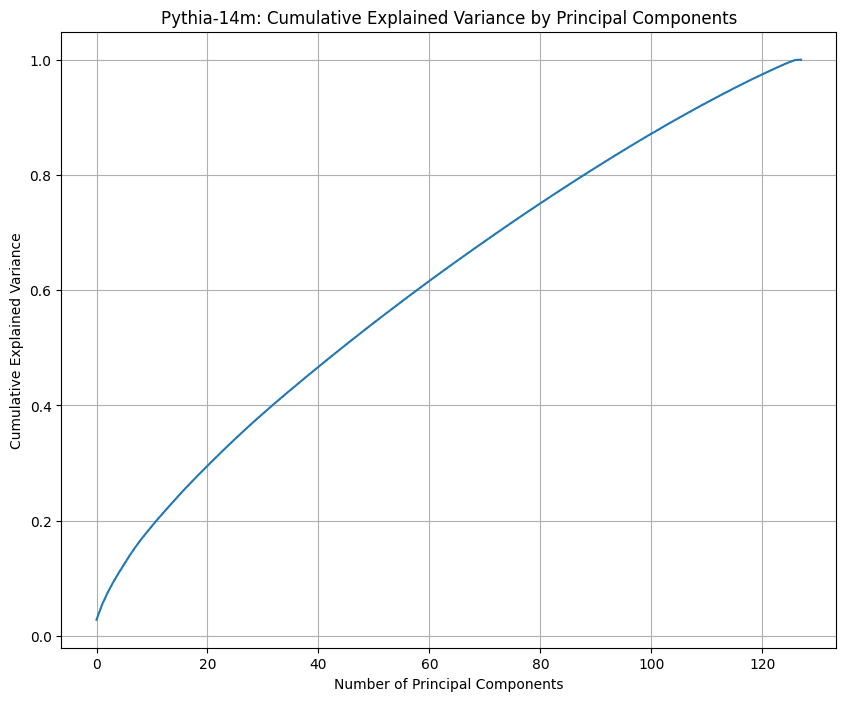
Here are graphs I made for GPT2, Mistral 7B, and Pythia 14M.
3 dimensions indeed explain almost all of the information in GPT's positional embeddings, whereas Mistral 7B and Pythia 14M both seem to make use of all the dimensions.
Is all the money gone by now? I'd be very happy to take a bet if not.
Thanks for the response! I still think that most of the value of SAEs comes from finding a human-interpretable basis, and most of these problems don't directly interfere with this property. I'm also somewhat skeptical that SAEs actually do find a human-interpretable basis, but that's a separate question.
I think this is a fair point. I ... (read more)