All of hazel's Comments + Replies
The other side of this post is to look at what various jobs cost. TIme and effort are the usual costs, but some jobs ask for things like willingness to deal with bullshit (a limited resource!), emotional energy, on-call readiness, various kinds of sensory or moral discomfort, and other things.
I've been well served by Bitwarden: https://bitwarden.com/
It has a dark theme, apps for everything (including Linux commandline), the Firefox extension autofills with a keyboard shortcut, plus I don't remember any large data breaches.
Part of the value of reddit-style votes as a community moderation feature is that using them is easy. Beware Trivial Inconveniences and all that. I think that having to explain every downvote would lead to me contributing to community moderation efforts less, would lead to dogpiling on people who already have far more refutation than they deserve, would lead to zero-effort 'just so I can downvote this' drive-by comments, and generally would make it far easier for absolute nonsense to go unchallenged.
If I came across obvious bot-spam in the middle of ...
To solve this problem you would need a very large dataset of mistakes made by LLMs, and their true continuations. [...] This dataset is unlikely to ever exist, given that its size would need to be many times bigger than the entire internet.
I had assumed that creating on that dataset was a major reason for doing a public release of ChatGPT. "Was this a good response?" [thumb-up] / [thumb-down] -> dataset -> more RLHF. Right?
Meaning it literally showed zero difference in half the tests? Does that make sense?
Codeforces is not marked as having a GPT-4 measurement on this chart. Yes, it's a somewhat confusing chart.
I know. I skimmed the paper, and in it there is a table above the chart showing the results in the tasks for all models (as every model's performance is below 5% in codeforces, on the chart they overlap). I replied to the comment I replied to because thematically it seemed the most appropriate (asking about task performance), sorry if my choice of where to comment was confusing.
From the table:
GPT-3.5's codeforces rating is "260 (below 5%)"
GPT-4's codeforces rating is "392 (below 5%)"
Green bars are GPT-4. Blue bars are not. I suspect they just didn't retest everything.
They did run the tests for all models, from Table 1:
(the columns are GPT-4, GPT-4 (no vision), GPT-3.5)

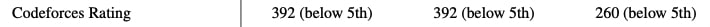
So.... they held the door open to see if it'd escape or not? I predict this testing method may go poorly with more capable models, to put it lightly.
And then OpenAI deployed a more capable version than was tested!
They also did not have access to the final version of the model that we deployed. The final version has capability improvements relevant to some of the factors that limited the earlier models power-seeking abilities, such as longer context length, and improved problem-solving abilities as in some cases we've observed.
This defeats the entire ...
At the time I took AlphaGo as a sign that Elizer was more correct than Hanson w/r/t the whole AI-go-FOOM debate. I realize that's an old example which predates the last-four-years AI successes, but I updated pretty heavily on it at the time.
Eliezer likes to characterize the success of deep learning as "being further than him on the Eliezer-Robin axis", but I consider that quite misleading. I would say that it's rather mostly orthogonal to that axis, contradicting both Eliezer and Robin's prior models in different ways.
I'm going to suggest reading widely as another solution. I think it's dangerous to focus too much on one specific subgenre, or certain authors, or books only from from one source (your library and Amazon do, in fact, filter your content for you, if not very tightly).
For me, the benefit of studying tropes is that it makes it easy to talk about the ways in which stories are story-like. In fact, to discuss what stories are like, this post used several links to tropes (specifically ones known to be wrong/misleading/inapplicable to reality).
I think a few deep binges on TVtropes for media I liked really helped me get a lot better at media analysis very, very quickly. (Along with a certain anime analysis blog that mixed in obvious and insightful cinematography commentary focusing on framing, color, and lighting, with m...
However, you decided to define "intelligence" as "stuff like complex problem solving that's useful for achieving goals" which means that intentionality, consciousness, etc. is unconnected to it
This is the relevant definition for AI notkilleveryoneism.
There has to be some limits
Those limits don't have to be nearby, or look 'reasonable', or be inside what you can imagine.
Part of the implicit background for the general AI safety argument is a sense for how minds could be, and that the space of possible minds is large and unaccountably alien. Eliezer spent some time trying to communicate this in the sequences: https://www.lesswrong.com/posts/tnWRXkcDi5Tw9rzXw/the-design-space-of-minds-in-general, https://www.lesswrong.com/posts/5wMcKNAwB6X4mp9og/that-alien-message.
Early LessWrong was atheist, but everything on the internet around the time LW was taking off had a position in that debate. "...the defining feature of this period wasn’t just that there were a lot of atheism-focused things. It was how the religious-vs-atheist conflict subtly bled into everything." Or less subtly, in this case.
I see it just as a product of the times. I certainly found the anti-theist content in Rationality: A to Z to be slightly jarring on a re-read -- on other topics, Elizer is careful to not bring into it the political issues of t...
Tying back to an example in the post: if we're using ascii encoding, then the string "Mark Xu" takes up 49 bits. It's quite compressible, but that still leaves more than enough room for 24 bits of evidence to be completely reasonable.
This paper suggests that spoken language is consistently ~39bits/second.
Where does the money go? Is it being sold at cost, or is there surplus?
If money is being made, will it support: 1. The authors? 2. LW hosting costs? 3. LW-adjacent charities like MIRI? 4. The editors/compilers/LW moderators?
EDIT: Was answered over on /r/slatestarcodex. tldr: one print run has been paid for at a loss, any (unlikely) profits go to supporting the Lesswrong nonprofit organization.
If and are the fourier transforms of and , then . This is yet another case where you don't actually have to compute the convolution to get the thing. I don't actually use fourier transforms or have any intuition about them, but for those who do, maybe this is useful?
It's amazingly useful in signal processing, where you often care about the frequency-domain because it's perceptually significant (eg: percieved pitch & timbre of a sound = fundamental frequency of the air-vibrations ...
In my experience, stating things outright and giving examples helps with communication. You might not need a definition, but the relevant question is would it improve the text for other readers?
"It's obviously bad. Think about it and you'll notice that. I could write a YA dystopian novel about how the consequences are bad." <-- isn't an argument, at all. It assumes bad consequences rather than demonstrating or explaining how the consequences would be bad. That section is there for other reasons, partially (I think?) to explain Zvi's emotional state and why he wrote the article, and why it has a certain tone.
I am not sure why you pick on blackmail specifically
This is in response to other writers, esp. Robin Hanson. That's why.
This only looks at the effects on Alice and on Bob, as a simplification. But with blackmail "carrying out the threat" means telling other people information about Bob, and that is often useful for those other people.
When the public interest motivates the release of private info, it's called 'whistleblowing' and is* legally protected and considered far more moral than blackmail. I think that contrast is helpful to understanding why that's not enough to make blackmail moral.
*in some jurisdictions, restrictions may apply, see...
If you're throwing your AI into a perfect inescapable hole to die and never again interacting with it, then what exact code you're running will never matter. If you observe it though, then it can affect you. That's an output.
What are you planning to do with the filtered-in 'friendly' AIs? Run them in a different context? Trust them with access to resources? Then an unfriendly AI can propose you as a plausible hypothesis, predict your actions, and fake being friendly. It's just got to consider that escape might be reachable, or...
https://www.lesserwrong.com/posts/D6trAzh6DApKPhbv4/a-voting-theory-primer-for-rationalists
The first link in this post should go ^ here to your voting theory primer. Instead, for me, it links here:
https://www.lesserwrong.com/posts/JewWDfLoxgFtJhNct/utility-versus-reward-function-partial-equivalence
How does the AI know you aren't just lying about your name, and much more besides? Anyone can type those names. People just go to the context window and lie, a lot, about everything, adversarially optimized against an AIs parallel instances. If those names come to mean 'trustworthy', this will be noticed, exploited, the trust build there will be abused. (See discussion of hostile ... (read more)