All of Leon Lang's Comments + Replies
The two sides of AI Safety (AI risk as anarchy vs. concentration of power) pattern-match a bit to this abstract I found today in my inbox:
...The trajectory of intelligence evolution is often framed around the emergence of artificial general intelligence (AGI) and its alignment with human values. This paper challenges that framing by introducing the concept of intelligence sequencing: the idea that the order in which AGI and decentralized collective intelligence (DCI) emerge determines the long-term attractor basin of intelligence. Using insights from dynamica
Do you think the x-axis being a release date is more mysterious than the same fact regarding Moore's law?
(Tbc., I think this doesn't make it less mysterious: For Moore's law this also seems like a mystery to me. But this analogy makes it more plausible that there is a mysterious but true reason driving such trends, instead of the graph from METR simply being a weird coincidence. )
Maryna Viazovska, the Ukrainian Fields medalist, did her PhD in Germany under Don Zagier.
---
I once saw at least one French TV talkshow where famous mathematicians were invited (I don't find the links anymore). Something like that would be pretty much unthinkable in Germany. So I wonder if math has generally more prestige in France than e.g. in Germany.
Thanks for this post!
The deadline possibly requires clarification:
We will keep the application form open until at least 11:59pm AoE on Thursday, February 27.
In the job posting, you write:
Application deadline: 12pm PST Friday 28th February 2025
There are a few sentences in Anthropic's "conversation with our cofounders" regarding RLHF that I found quite striking:
Dario (2:57): "The whole reason for scaling these models up was that [...] the models weren't smart enough to do RLHF on top of. [...]"
Chris: "I think there was also an element of, like, the scaling work was done as part of the safety team that Dario started at OpenAI because we thought that forecasting AI trends was important to be able to have us taken seriously and take safety seriously as a problem."
Dario: "Correct."
That LLMs were scal...
we thought that forecasting AI trends was important to be able to have us taken seriously
This might be the most dramatic example ever of forecasting affecting the outcome.
Similarly I'm concerned that a lot of alignment people are putting work into evals and benchmarks which may be having some accelerating affect on the AI capabilities which they are trying to understand.
"That which is measured improves. That which is measured and reported improves exponentially."
Hi! Thanks a lot for your comments and very good points. I apologize for my late answer, caused by NeurIPS and all the end-of-year breakdown of routines :)
On 1: Yes, the formalism I'm currently working on also allows to talk about the case that the human "understands less" than the AI.
On 2:
Have you considered the connection between partial observability and state aliasing/function approximation?
I am not entirely sure if I understand! Though if it's just what you express in the following sentences, here's my answers:
...Maybe you could apply your theory t
Thanks for the list! I have two questions:
1: Can you explain how generalization of NNs relates to ELK? I can see that it can help with ELK (if you know a reporter generalizes, you can train it on labeled situations and apply it more broadly) or make ELK unnecessary (if weak to strong generalization perfectly works and we never need to understand complex scenarios). But I’m not sure if that’s what you mean.
2: How is goodhart robustness relevant? Most models today don’t seem to use reward functions in deployment, and in training the researchers can control how hard they optimize these functions, so I don’t understand why they necessarily need to be robust under strong optimization.
“heuristics activated in different contexts” is a very broad prediction. If “heuristics” include reasoning heuristics, then this probably includes highly goal-oriented agents like Hitler.
Also, some heuristics will be more powerful and/or more goal-directed, and those might try to preserve themselves (or sufficiently similar processes) more so than the shallow heuristics. Thus, I think eventually, it is plausible that a superintelligence looks increasingly like a goal-maximizer.
This is a low effort comment in the sense that I don’t quite know what or whether you should do something different along the following lines, and I have substantial uncertainty.
That said:
-
I wonder whether Anthropic is partially responsible for an increased international race through things like Dario advocating for an entente strategy and talking positively about Leopold Aschenbrenner’s “situational awareness”. I wished to see more of an effort to engage with Chinese AI leaders to push for cooperation/coordination. Maybe it’s still possible to course-co
I have an AI agent that wrote myself
Best typo :D
Have you also tried reviewing for conferences like NeurIPS? I'd be curious what the differences are.
Some people send papers to TMLR when they think they wouldn't be accepted to the big conferences due to not being that "impactful" --- which makes sense since TMLR doesn't evaluate impact. It's thus possible that the median TMLR submission is worse than the median conference submission.
I just donated $200. Thanks for everything you're doing!
Yeah I think that's a valid viewpoint.
Another viewpoint that points in a different direction: A few years ago, LLMs could only do tasks that require humans ~minutes. Now they're at the ~hours point. So if this metric continues, eventually they'll do tasks requiring humans days, weeks, months, ...
I don't have good intuitions that would help me to decide which of those viewpoints is better for predicting the future.
Somewhat pedantic correction: they don’t say “one should update”. They say they update (plus some caveats).
After the US election, the twitter competitor bluesky suddenly gets a surge of new users:
How likely are such recommendations usually to be implemented? Are there already manifold markets on questions related to the recommendation?
In the reuters article they highlight Jacob Helberg: https://www.reuters.com/technology/artificial-intelligence/us-government-commission-pushes-manhattan-project-style-ai-initiative-2024-11-19/
He seems quite influential in this initiative and recently also wrote this post:
https://republic-journal.com/journal/11-elements-of-american-ai-supremacy/
Wikipedia has the following paragraph on Helberg:
“ He grew up in a Jewish family in Europe.[9] Helberg is openly gay.[10] He married American investor Keith Rabois in a 2018 ceremony officiated by Sam Altman.”
Might ...
Why I think scaling laws will continue to drive progress
Epistemic status: This is a thought I had since a while. I never discussed it with anyone in detail; a brief conversation could convince me otherwise.
According to recent reports there seem to be some barriers to continued scaling. We don't know what exactly is going on, but it seems like scaling up base models doesn't bring as much new capability as people hope.
However, I think probably they're still in some way scaling the wrong thing: The model learns to predict a static dataset on the interne...
Do we know anything about why they were concerned about an AGI dictatorship created by Demis?
What’s your opinion on the possible progress of systems like AlphaProof, o1, or Claude with computer use?
"Scaling breaks down", they say. By which they mean one of the following wildly different claims with wildly different implications:
- When you train on a normal dataset, with more compute/data/parameters, subtract the irreducible entropy from the loss, and then plot in a log-log plot: you don't see a straight line anymore.
- Same setting as before, but you see a straight line; it's just that downstream performance doesn't improve .
- Same setting as before, and downstream performance improves, but: it improves so slowly that the economics is not in favor of furthe
This is a just ask.
Also, even though it's not locally rhetorically convenient [ where making an isolated demand for rigor of people making claims like "scaling has hit a wall [therefore AI risk is far]" that are inconvenient for AInotkilleveryoneism, is locally rhetorically convenient for us ], we should demand the same specificity of people who are claiming that "scaling works", so we end up with a correct world-model and so people who just want to build AGI see that we are fair.
Thanks for this compendium, I quite enjoyed reading it. It also motivated me to read the "Narrow Path" soon.
I have a bunch of reactions/comments/questions at several places. I focus on the places that feel most "cruxy" to me. I formulate them without much hedging to facilitate a better discussion, though I feel quite uncertain about most things I write.
On AI Extinction
The part on extinction from AI seems badly argued to me. Is it fair to say that you mainly want to convey a basic intuition, with the hope that the readers will find extinction an "obvi...
Then the MATS stipend today is probably much lower than it used to be? (Which would make sense since IIRC the stipend during MATS 3.0 was settled before the FTX crash, so presumably when the funding situation was different?)
Is “CHAI” being a CHAI intern, PhD student, or something else? My MATS 3.0 stipend was clearly higher than my CHAI internship stipend.
I have a similar feeling, but there are some forces in the opposite direction:
- Nvidia seems to limit how many GPUs a single competitor can acquire.
- training frontier models becomes cheaper over time. Thus, those that build competitive models some time later than the absolute frontier have to invest much less resources.
My impression is that Dario (somewhat intentionally?) plays the game of saying things he believes to be true about the 5-10 years after AGI, conditional on AI development not continuing.
What happens after those 5-10 years, or if AI gets even vastly smarter? That seems out of scope for the article. I assume he's doing that since he wants to influence a specific set of people, maybe politicians, to take a radical future more seriously than they currently do. Once a radical future is more viscerally clear in a few years, we will likely see even more radical essays.
It is a thing that I remember having been said at podcasts, but I don't remember which one, and there is a chance that it was never said in the sense I interpreted it.
Also, quote from this post:
"DeepMind says that at large quantities of compute the scaling laws bend slightly, and the optimal behavior might be to scale data by even more than you scale model size. In which case you might need to increase compute by more than 200x before it would make sense to use a trillion parameters."
Are the straight lines from scaling laws really bending? People are saying they are, but maybe that's just an artefact of the fact that the cross-entropy is bounded below by the data entropy. If you subtract the data entropy, then you obtain the Kullback-Leibler divergence, which is bounded by zero, and so in a log-log plot, it can actually approach negative infinity. I visualized this with the help of ChatGPT:
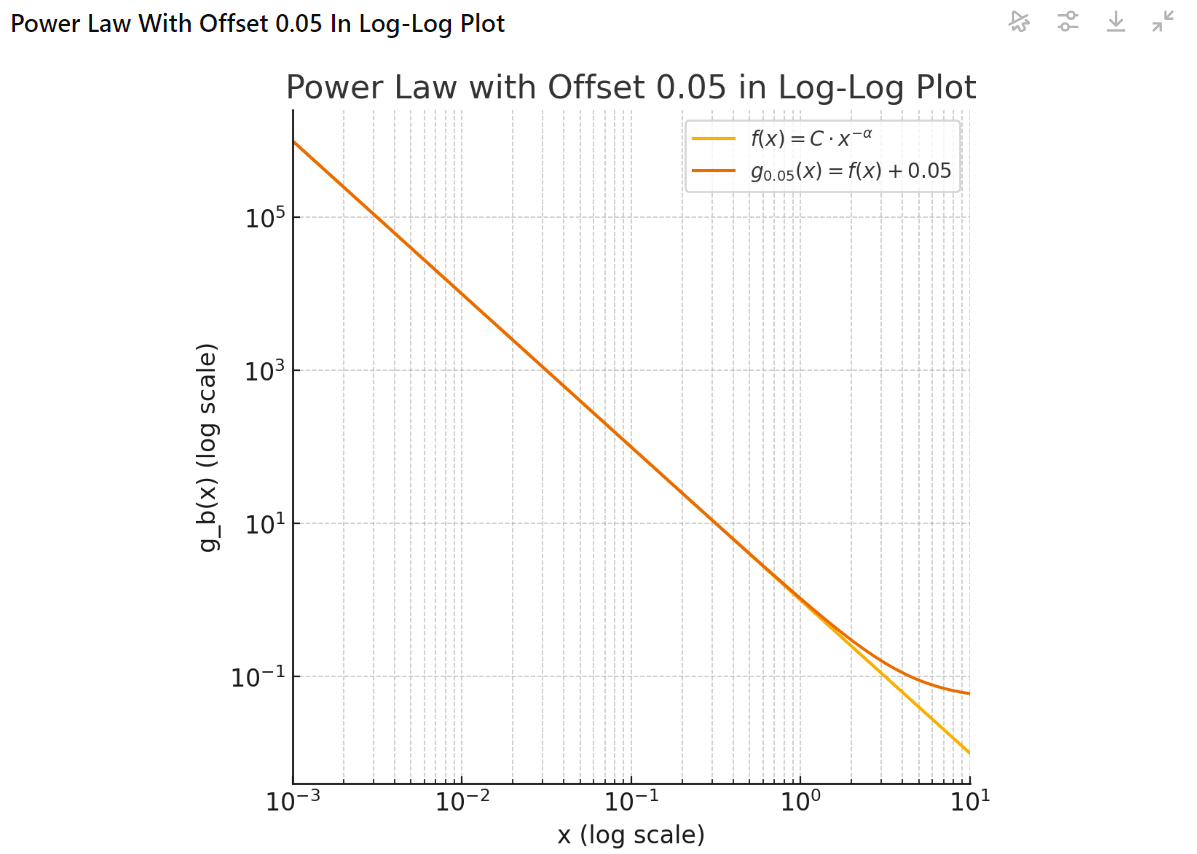
Here, f represents the Kullback-Leibler divergence, and g the cross-entropy loss with the entropy offset.
I've not seen the claim that the scaling laws are bending. Where should I look?
Isn't an intercept offset already usually included in the scaling laws and so can't be misleading anyone? I didn't think anyone was fitting scaling laws which allow going to exactly 0 with no intrinsic entropy.
Agreed.
To understand your usage of the term “outer alignment” a bit better: often, people have a decomposition in mind where solving outer alignment means technically specifying the reward signal/model or something similar. It seems that to you, the writeup of a model-spec or constitution also counts as outer alignment, which to me seems like only part of the problem. (Unless perhaps you mean that model specs and constitutions should be extended to include a whole training setup or similar?)
If it doesn’t seem too off-topic to you, could you comment on your views on this terminology?
https://www.wsj.com/tech/ai/californias-gavin-newsom-vetoes-controversial-ai-safety-bill-d526f621
“California Gov. Gavin Newsom has vetoed a controversial artificial-intelligence safety bill that pitted some of the biggest tech companies against prominent scientists who developed the technology.
The Democrat decided to reject the measure because it applies only to the biggest and most expensive AI models and leaves others unregulated, according to a person with knowledge of his thinking”
@Zach Stein-Perlman which part of the comment are you skeptical of? Is it the veto itself, or is it this part?
The Democrat decided to reject the measure because it applies only to the biggest and most expensive AI models and leaves others unregulated, according to a person with knowledge of his thinking”
New Bloomberg article on data center buildouts pitched to the US government by OpenAI. Quotes:
- “the startup shared a document with government officials outlining the economic and national security benefits of building 5-gigawatt data centers in various US states, based on an analysis the company engaged with outside experts on. To put that in context, 5 gigawatts is roughly the equivalent of five nuclear reactors, or enough to power almost 3 million homes.”
- “Joe Dominguez, CEO of Constellation Energy Corp., said he has heard that Altman is talking about ...
From $4 billion for a 150 megawatts cluster, I get 37 gigawatts for a $1 trillion cluster, or seven 5-gigawatts datacenters (if they solve geographically distributed training). Future GPUs will consume more power per GPU (though a transition to liquid cooling seems likely), but the corresponding fraction of the datacenter might also cost more. This is only a training system (other datacenters will be built for inference), and there is more than one player in this game, so the 100 gigawatts figure seems reasonable for this scenario.
Current best deployed mod...
OpenAI would have mentioned if they had reached gold on the IMO.
I think it would be valuable if someone would write a post that does (parts of) the following:
- summarize the landscape of work on getting LLMs to reason.
- sketch out the tree of possibilities for how o1 was trained and how it works in inference.
- select a “most likely” path in that tree and describe in detail a possibility for how o1 works.
I would find it valuable since it seems important for external safety work to know how frontier models work, since otherwise it is impossible to point out theoretical or conceptual flaws for their alignment approaches.
O...
Thanks for the post, I agree with the main points.
There is another claim on causality one could make, which would be: LLMs cannot reliably act in the world as robust agents since by acting in the world, you change the world, leading to a distributional shift from the correlational data the LLM encountered during training.
I think that argument is correct, but misses an obvious solution: once you let your LLM act in the world, simply let it predict and learn from the tokens that it receives in response. Then suddenly, the LLM does not model correlational, but actual causal relationships.
Agreed.
I think the most interesting part was that she made a comment that one way to predict a mind is to be a mind, and that that mind will not necessarily have the best of all of humanity as its goal. So she seems to take inner misalignment seriously.
40 min podcast with Anca Dragan who leads safety and alignment at google deepmind: https://youtu.be/ZXA2dmFxXmg?si=Tk0Hgh2RCCC0-C7q
To clarify: are you saying that since you perceive Chris Olah as mostly intrinsically caring about understanding neural networks (instead of mostly caring about alignment), you conclude that his work is irrelevant to alignment?
I can see that research into proof assistants might lead to better techniques for combining foundation models with RL. Is there anything more specific that you imagine? Outside of math there are very different problems because there is no easy to way to synthetically generate a lot of labeled data (as opposed to formally verifiable proofs).
Not much more specific! I guess from a certain level of capabilities onward, one could create labels with foundation models that evaluate reasoning steps. This is much more fuzzy than math, but I still guess a person ...
I think the main way that proof assistant research feeds into capabilies research is not through the assistants themselves, but by the transfer of the proof assistant research to creating foundation models with better reasoning capabilities. I think researching better proof assistants can shorten timelines.
- See also Demis' Hassabis recent tweet. Admittedly, it's unclear whether he refers to AlphaProof itself being accessible from Gemini, or the research into AlphaProof feeding into improvements of Gemini.
- See also an important paragraph in the blogpost for A
https://www.washingtonpost.com/opinions/2024/07/25/sam-altman-ai-democracy-authoritarianism-future/
Not sure if this was discussed at LW before. This is an opinion piece by Sam Altman, which sounds like a toned down version of "situational awareness" to me.
The news is not very old yet. Lots of potential for people to start freaking out.
One question: Do you think Chinchilla scaling laws are still correct today, or are they not? I would assume these scaling laws depend on the data set used in training, so that if OpenAI found/created a better data set, this might change scaling laws.
Do you agree with this, or do you think it's false?
https://x.com/sama/status/1813984927622549881
According to Sam Altman, GPT-4o mini is much better than text-davinci-003 was in 2022, but 100 times cheaper. In general, we see increasing competition to produce smaller-sized models with great performance (e.g., Claude Haiku and Sonnet, Gemini 1.5 Flash and Pro, maybe even the full-sized GPT-4o itself). I think this trend is worth discussing. Some comments (mostly just quick takes) and questions I'd like to have answers to:
- Should we expect this trend to continue? How much efficiency gains are still possible? C
To make a Chinchilla optimal model smaller while maintaining its capabilities, you need more data. At 15T tokens (the amount of data used in Llama 3), a Chinchilla optimal model has 750b active parameters, and training it invests 7e25 FLOPs (Gemini 1.0 Ultra or 4x original GPT-4). A larger $1 billion training run, which might be the current scale that's not yet deployed, would invest 2e27 FP8 FLOPs if using H100s. A Chinchilla optimal run for these FLOPs would need 80T tokens when using unique data.
Starting with a Chinchilla optimal model, if it's made 3x ...
I went to this event in 2022 and it was lovely. Will come again this year. I recommend coming!
Thanks for the answer!
But basically, by "simple goals" I mean "goals which are simple to represent", i.e. goals which have highly compressed representations
It seems to me you are using "compressed" in two very different meanings in part 1 and 2. Or, to be fairer, I interpret the meanings very differently.
I try to make my view of things more concrete to explain:
Compressed representations: A representation is a function from observations of the world state (or sequences of such observations) into a representation space ...
Thanks for the post!
a. How exactly do 1 and 2 interact to produce 3?
I think the claim is along the lines of "highly compressed representations imply simple goals", but the connection between compressed representations and simple goals has not been argued, unless I missed it. There's also a chance that I simply misunderstand your post entirely.
b. I don't agree with the following argument:
...Decomposability over space. A goal is decomposable over space if it can be evaluated separately in each given volume of space. All else equal, a goal is more decompos
You should all be using the "Google Scholar PDF reader extension" for Chrome.
Features I like:
- References are linked and clickable
- You get a table of contents
- You can move back after clicking a link with Alt+left
Screenshot:

I found this fun to read, even years later. There is one case where Rohin updated you to accept a conclusion, where I'm not sure I agree:
I think here and elsewhere, there seems to be a bit of conflation between "debate", "explanation", and "concept".
My impression is that debate relies on the assumption that there are exponentially large explanations for true statements. If I'm a debater, I can make such an explanation by saying "A a... (read more)