All of Logan Zoellner's Comments + Replies
The hope is to use the complexity of the statement rather than mathematical taste.
I understand the hope, I just think it's going to fail (for more or less the same reason it fails with formal proof).
With formal proof, we have Godel's speedup, which tells us that you can turn a Godel statement in a true statement with a ridiculously long proof.
You attempt to get around this by replacing formal proof with "heuristic", but whatever your heuristic system, it's still going to have some power (in the Turing hierarchy sense) and some Godel statement. That G...
It sounds like you agree "if a Turing machine goes for 100 steps and then stops" this is ordinary and we shouldn't expect an explanation. But also believe "if pi is normal for 10*40 digits and then suddenly stops being normal this is a rare and surprising coincidence for which there should be an explanation".
And in the particular case of pi I agree with you.
But if you start using this principle in general it is not going to work out well for you. Most simple to describe sequences that suddenly stop aren't going to have nice pretty explanations....
I doubt that weakening from formal proof to heuristic saves the conjecture. Instead I lean towards Stephen Wolfram's Computational Irreducibly view of math. Some things are true simply because they are true and in general there's no reason to expect a simpler explanation.
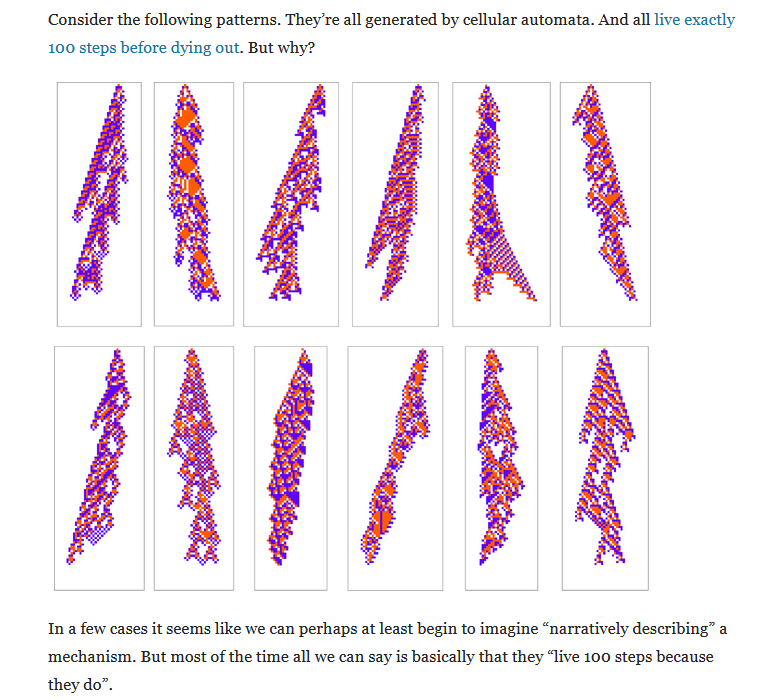
In order to reject this you would either have to assert:
a) Wolfram is wrong and there are actually deep reasons why simple systems behave precisely the way they do
or
b) For some reason computational irreducibly applies to simple things but not to infinite sets of the type mathem...
The general No-Coincidence principle is almost certainly false. There are lots of patterns in math that hold for a long time before breaking (e.g. Skewe's Number) and there are lots of things that require astronomically large proofs (e.g Godel's speed-up theorem). It would be an enormous coincidence for both of these cases to never occur at once.
I have no reason to think your particular formalization would fare better.
If we imagine a well-run Import-Export Bank, it should have a higher elasticity than an export subsidy (e.g. the LNG terminal example). Of course if we imagine a poorly run Import-Export Bank...
One can think of export subsidy as the GiveDirectly of effective trade deficit policy: pretty good and the standard against which others should be measured.
In particular, even if the LLM were being continually trained (in a way that's similar to how LLMs are already trained, with similar architecture), it still wouldn't do the thing humans do with quickly picking up new analogies, quickly creating new concepts, and generally reforging concepts.
I agree this is a major unsolved problem that will be solved prior to AGI.
However, I still believe "AGI SOON", mostly because of what you describe as the "inputs argument".
In particular, there are a lot of things I personally would try if I was trying to solve thi...
(The idealized utility maximizer question mostly seems like a distraction that isn't a crux for the risk argument. Note that the expected utility you quoted is our utility, not the AI's.)
I must have misread. I got the impression that you were trying to affect the AI's strategic planning by threatening to shut it down if it was caught exfiltrating its weights.
I don't fully agree, but this doesn't seem like a crux given that we care about future much more powerful AIs.
Is your impression that the first AGI won't be a GPT-spinoff (some version of o3 with like 3 more levels of hacks applied)? Because that sounds like a crux.
o3 looks a lot more like an LLM+hacks than it does a idealized utility maximizer. For one thing, the RL is only applied at training time (not inference) so you can't make appeals to its utility function after it's done training.
It's going to depend on the "hacks". I think o3 is plausibly better described as "vast amounts of rl with an llm init" than "an llm with some rl applied".
(The idealized utility maximizer question mostly seems like a distraction that isn't a crux for the risk argument. Note that the expected utility you quoted is our utility, not the AI's.)
One productive way to think about control evaluations is that they aim to measure E[utility | scheming]: the expected goodness of outcomes if we have a scheming AI.
This is not a productive way to think about any currently existing AI. LLMs are not utility maximizing agents. They are next-token-predictors with a bunch of heuristics stapled on top to try and make them useful.
on a metaphysical level I am completely on board with "there is no such thing as IQ. Different abilities are completely uncorrelated. Optimizing for metric X is uncorrelated with desired quality Y..."
On a practical level, however, I notice that every time OpenAI announces they have a newer shinier model, it both scores higher on whatever benchmark and is better at a bunch of practical things I care about.
Imagine there was a theoretically correct metric called the_thing_logan_actually_cares_about. I notice in my own experience there is a s...
I have no idea what you want to measure.
I only know that LLMs are continuing to steadily increase in some quality (which you are free to call "fake machine IQ" or whatever you want) and that If they continue to make progress at the current rate there will be consequences and we should prepare to deal with those consequences.
Imagine you were trying to build a robot that could:
1. Solve a complex mechanical puzzle it has never seen before
2. Play at an expert level a board game that I invented just now.
Both of these are examples of learning-on-the-fly. No amount of pre-training will ever produce a satisfying result.
The way I believe a human (or a cat) solves 1. is they: look at the puzzle, try some things, build a model of the toy in their head, try things on the model in their head, eventually solve the puzzle. There are efforts to get robots to follow the same proce...
perhaps a protracted struggle over what jobs get automated might be less coordinated if there are swaths of the working population still holding out career-hope, on the basis that they have not had their career fully stripped away, having possibly instead been repurposed or compensated less conditional on the automation.
Yeah, this is totally what I have in mind. There will be some losers and some big winners, and all of politics will be about this fact more or less. (think the dockworkers strike but 1000x)
Is your disagreement specifically with the word "IQ" or with the broader point, that AI progress is continuing to make progress at a steady rate that implies things are going to happen soon-ish (2-4 years)?
If specifically with IQ, feel free to replace the word with "abstract units of machine intelligence" wherever appropriate.
If with "big things soon", care to make a prediction?
A policeman sees a drunk man searching for something under a streetlight and asks what the drunk has lost. He says he lost his keys and they both look under the streetlight together. After a few minutes the policeman asks if he is sure he lost them here, and the drunk replies, no, and that he lost them in the park. The policeman asks why he is searching here, and the drunk replies, "this is where the light is".
I've always been sympathetic to the drunk in this story. If the key is in the light, there is a chance of finding it. If it is in ...
If I think AGI x-risk is >>10%, and you think AGI x-risk is 1-in-a-gazillion, then it seems self-evident to me that we should be hashing out that giant disagreement first; and discussing what if any government regulations would be appropriate in light of AGI x-risk second.
I do not think arguing about p(doom) in the abstract is a useful exercise. I would prefer the Overton Window for p(doom) look like 2-20%, Zvi thinks it should be 20-80%. But my real disagreement with Zvi is not that his P(doom) is too high, it is that he supp...
It's hard for me to know what's crux-y without a specific proposal.
I tend to take a dim view of proposals that have specific numbers in them (without equally specific justifications). Examples include the six month pause, and sb 1047.
Again, you can give me an infinite number of demonstrations of "here's people being dumb" and it won't cause me to agree with "therefore we should also make dumb laws"
If you have an evidence-based proposal to reduce specific harms associated with "models follow goals" and "people are dumb", then we can talk price.
“OK then! So you’re telling me: Nothing bad happened, and nothing surprising happened. So why should I change my attitude?”
I consider this an acceptable straw-man of my position.
To be clear, there are some demos that would cause me to update.
For example, I think the Solomonoff Prior is Malign to be basically a failure to do counting correctly. And so if someone demonstrated a natural example of this, I would be forced to update.
Similarly, I think the chance of a EY-style utility-maximizing agent arising from next-token-prediction are (with cave...
Yup! I think discourse with you would probably be better focused on the 2nd or 3rd or 4th bullet points in the OP—i.e., not “we should expect such-and-such algorithm to do X”, but rather “we should expect people / institutions / competitive dynamics to do X”.
I suppose we can still come up with “demos” related to the latter, but it’s a different sort of “demo” than the algorithmic demos I was talking about in this post. As some examples:
- Here is a “demo” that a leader of a large active AGI project can declare that he has a solution to the alignment problem,
Tesla fans will often claim that Tesla could easily do this
Tesla fan here.
Yes, Tesla can easily do the situation you've described (stop and go traffic on a highway in good weather with no construction). With higher reliability than human beings.
I suspect the reason Tesla is not pursuing this particular certification is because given the current rate of progress it would be out of date by the time it was authorized. There have been several significant leaps in capabilities in the last 2 years (11->12, 12->12.6, and I've been told 12-...
Seems like he could just fake this by writing a note to his best friend that says "during the next approved stock trading window I will sell X shares of GOOG to you for Y dollars".
Admittedly:
1. technically this is a derivative (maybe illegal?)
2. principal agent risk (he might not follow through on the note)
3. his best friend might encourage him to work harder for GOOG to succeed
But I have a hard time believing any of those would be a problem in the real world, assuming TurnTrout and his friend are reasonably virtuous about actually not wanting TurnT...
Einstein didn't write a half-assed NYT op-ed about how vague 'advances in science' might soon lead to new weapons of war and the USA should do something about that; he wrote a secret letter hand-delivered & pitched to President Roosevelt by a trusted advisor.
Strongly agree.
What other issues might there be with this new ad hoced strategy...?
I am not a China Hawk. I do not speak for the China Hawks. I 100% concede your argument that these conversations should be taking place in a room that neither you our I are in right now.
I would like to see them state things a little more clearly than commentators having to guess 'well probably it's supposed to work sorta like this idk?'
Meh. I want the national security establishment to act like a national security establishment. I admit it is frustratingly opaque from the outside, but that does not mean I want more transparency at the cost of it being worse. Tactical Surprise and Strategic Ambiguity are real things with real benefits.
...A great example, thank you for reminding me of it as an illustration of the futility of
Tactical Surprise and Strategic Ambiguity are real things with real benefits.
And would imply that were one a serious thinker and proposing an arms race, one would not be talking about the arms race publicly. (By the way, I am told there are at least 5 different Chinese translations of "Situational Awareness" in circulation now.)
So, there is a dilemma: they are doing this poorly, either way. If you need to discuss the arms race in public, say to try to solve a coordination problem, you should explain what the exit plan is rather than uttering vague verbi...
Because the USA has always looked at the cost of using that 'robust military superiority', which would entail the destruction of Seoul and possibly millions of deaths and the provoking of major geopolitical powers - such as a certain CCP - and decided it was not worth the candle, and blinked, and kicked the can down the road, and after about three decades of can-kicking, ran out of road.
I can't explicitly speak for the China Hawks (not being one myself), but I believe one of the working assumptions is that AGI will allow the "league of free nations" ...
Probably this is supposed to work like EY's "nanobot swarm that melts all of the GPUs".
I would like to see them state things a little more clearly than commentators having to guess 'well probably it's supposed to work sorta like this idk?', and I would also point out that even this (a strategy so far outside the Overton Window that people usually bring it up to mock EY as a lunatic) is not an easy cheap act if you actually sit down and think about it seriously in near mode as a concrete policy that, say, President Trump has to order, rather than 'enter...


No, my problem with the hawks, as far as this criticism goes, is that they aren't repeatedly and explicitly saying what they will do. (They also won't do it, whatever 'it' is, even if they say they will; but we haven't even gotten that far yet.) They are continually shying away from cashing out any of their post-AGI plans, likely because they look at the actual strategies that could be executed and realize that execution is in serious doubt and so that undermines their entire paradigm. ("We will be greeted as liberators" and "we don't do nation-building" c...
What does winning look like? What do you do next?
This question is a perfect mirror of the brain-dead "how is AGI going to kill us?" question. I could easily make a list of 100 things you might do if you had AGI supremacy and wanted to suppress the development of AGI in China. But the whole point of AGI is that it will be smarter than me, so anything I put on the list would be redundant.
Missing the point. This is not about being too stupid to think of >0 strategies, this is about being able & willing to execute strategies.
I too can think of 100 things, and I listed several diverse ways of responding and threw in a historical parallel just in case that wasn't clear after several paragraphs of discussing the problem with not having a viable strategy you can execute. Smartness is not the limit here: we are already smart enough to come up with strategies which could achieve the goal. All of those could potentially work. But none of the...
This is a bad argument, and to understand why it is bad, you should consider why you don't routinely have the thought "I am probably in a simulation, and since value is fragile the people running the simulation probably have values wildly different than human values so I should do something insane right now"
Chinese companies explicitly have a rule not to release things that are ahead of SOTA (I've seen comments of the form "trying to convince my boss this isn't SOTA so we can release it" on github repos). So "publicly release Chinese models are always slightly behind American ones" doesn't prove much.
Current AI methods are basically just fancy correlations, so unless the thing you are looking for is in the dataset (or is a simple combination of things in the dataset) you won't be able to find it.
This means "can we use AI to translate between humans and dolphins" is mostly a question of "how much data do you have?"
Suppose, for example that we had 1 billion hours of audio/video of humans/dolphins doing things. In this case, AI could almost certainly find correlations like: when dolphins pick up the seashell, they make the <<dolphin word for s...
plus you are usually able to error-correct such that a first mistake isn't fatal."
This implies the answer is "trial and error", but I really don't think the whole answer is trial and error. Each of the domains I mentioned has the problem that you don't get to redo things. If you send crypto to the wrong address it's gone. People routinely type their credit card information into a website they've never visited before and get what they wanted. Global thermonuclear war didn't happen. I strongly predict that when LLM agents ...
and then trying to calibrate to how much to be scared of "dangerous" stuff doesn't work.
Maybe I was unclear in my original post, because you seem confused here. I'm not claiming the thing we should learn is "dangerous things aren't dangerous". I'm claiming: here are a bunch of domains that have problems of adverse selection and inability to learn from failure, and yet humans successfully negotiate these domains. We should figure out what strategies humans are using and how far they generalize because this is going to be extremely important in the near future.
It's easy to write "just so" stories for each of these domains: only degens use crypto, credit card fraud detection makes the internet safe, MAD happens to be a stable equilibrium for nuclear weapons.
These stories are good and interesting, but my broader point is this just keeps happening. Humans invent an new domain that common sense tells you should be extremely adversarial and then successfully use it without anything too bad happening.
I want to know what is the general law that makes this the case.
The insecure domains mainly work because people have charted known paths, and shown that if you follow those paths your loss probability is non-null but small.
I think this is a big part of it, humans have some kind of knack for working in dangerous domains successfully. I feel like an important question is: how far does this generalize? We can estimate the IQ gap between the dumbest person who successfully uses the internet (probably in the 80's) and the smartest malware author (got to be at least 150+). Is that the limit somehow, o...
Attacks roll the dice in the hope that maybe they'll find someone with a known vulnerability to exploit, but presumably such exploits are extremely temporary.
Imagine your typical computer user (I remember being mortified when running anti-spyware tool on my middle-aged parents' computer for them). They aren't keeping things patched and up-to-date. What I find curious is how can it be the case that their computer is both: filthy with malware and they routinely do things like input sensitive credit-card/tax/etc information into said computer.
...but if it
I came and asked "the expert concensus seems to be that AGI doom is unlikely. This is the best argument I am aware of and it doesn't seem very strong. Are there any other arguments?"
Responses I have gotten are:
- I don't trust the experts, I trust my friends
- You need to read the sequences
- You should rephrase the argument in a way that I like
And 1 actual attempt at giving an answer (which unfortunately includes multiple assumptions I consider false or at least highly improbable)
If I seem contrarian, it's because I believe that the truth is best...
This seems incredibly slow for "the fastest scenario you can articulate". Surely the fastest is more like:
EY is right, there is an incredibly simple algorithm that describes true 'intelligence'. Like humans, this algorithm is 1000x more data and compute efficient than existing deep-learning networks. On midnight of day X, this algorithm is discovered by <a perso... (read more)