All of Connor Leahy's Comments + Replies
Thanks for the comment!
Have I understood this correctly?
I am most confident in phases 1-3 of this agenda, and I think you have overall a pretty good rephrasing of 1-5, thanks! One note is that I don't think "LLM calls" as being fundamental, I think of LLMs as a stand-in for "banks of patterns" or "piles of shards of cognition." The exact shape of this can vary, LLMs are just our current most common shape of "cognition engines", but I can think of many other, potentially better, shapes this "neural primitive/co-processor" could take.
I think there is s...
Hi habryka, I don't really know how best to respond to such a comment. First, I would like to say thank you for your well-wishes, assuming you did not mean them sarcastically. Maybe I have lost the plot, and if so, I do appreciate help in recovering it. Secondly, I feel confused as to why you would say such things in general.
Just last month, me and my coauthors released a 100+ page explanation/treatise on AI extinction risk that gives a detailed account of where AGI risk comes from and how it works, which was received warmly by LW and the general public al...
Morality is multifaceted and multilevel. If you have a naive form of morality that is just "I do whatever I think is the right thing to do", you are not coordinating or being moral, you are just selfish.
Coordination is not inherently always good. You can coordinate with one group to more effectively do evil against another. But scalable Good is always built on coordination. If you want to live in a lawful, stable, scalable, just civilization, you will need to coordinate with your civilization and neighbors and make compromises.
As a citizen of a modern coun...
Hi, as I was tagged here, I will respond to a few points. There are a bunch of smaller points only hinted at that I won't address. In general, I strongly disagree with the overall conclusion of this post.
There are two main points I would like to address in particular:
1 More information is not more Gooder
There seems to be a deep underlying confusion here that in some sense more information is inherently more good, or inherently will result in good things winning out. This is very much the opposite of what I generally claim about memetics. Saying that all in...
I don't understand what point you are trying to make, to be honest. There are certain problems that humans/I care about that we/I want NNs to solve, and some optimizers (e.g. Adam) solve those problems better or more tractably than others (e.g. SGD or second order methods). You can claim that the "set of problems humans care about" is "arbitrary", to which I would reply "sure?"
Similarly, I want "good" "philosophy" to be "better" at "solving" "problems I care about." If you want to use other words for this, my answer is again "sure?" I think this is a good use of the word "philosophy" that gets better at what people actually want out of it, but I'm not gonna die on this hill because of an abstract semantic disagreement.
"good" always refers to idiosyncratic opinions, I don't really take moral realism particularly seriously. I think there is "good" philosophy in the same way there are "good" optimization algorithms for neural networks, while also I assume there is no one optimizer that "solves" all neural network problems.
I can't rehash my entire views on coordination and policy here I'm afraid, but in general, I believe we are currently on a double exponential timeline (though I wouldn't model it quite like you, but the conclusions are similar enough) and I think some simple to understand and straightforwardly implementable policy (in particular, compute caps) at least will move us to a single exponential timeline.
I'm not sure we can get policy that can stop the single exponential (which is software improvements), but there are some ways, and at least we will then have additional time to work on compounding solutions.
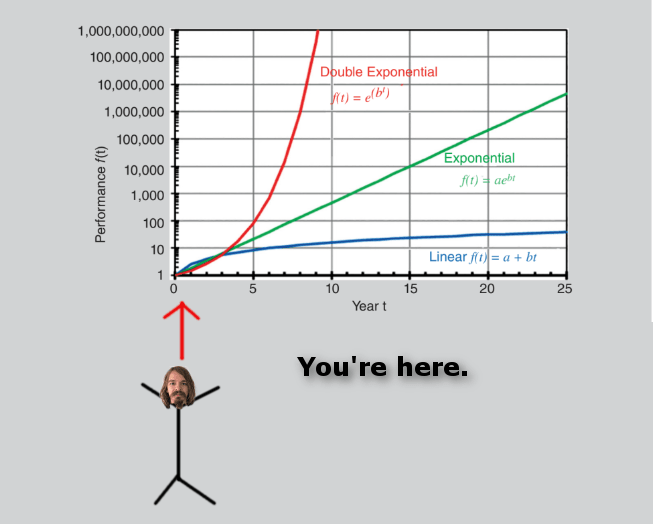
A lot of the debate surrounding existential risks of AI is bounded by time. For example, if someone said a meteor is about to hit the Earth that would be alarming, but the next question should be, "How much time before impact?" The answer to that question effects everything else.
If they say, "30 seconds". Well, there is no need to go online and debate ways to save ourselves. We can give everyone around us a hug and prepare for the hereafter. However, if the answer is "30 days" or "3 years" then those answers will generate very different responses.
The AI al...
I see regulation as the most likely (and most accessible) avenue that can buy us significant time. The fmpov obvious is just put compute caps in place, make it illegal to do training runs above a certain FLOP level. Other possibilities are strict liability for model developers (developers, not just deployers or users, are held criminally liable for any damage caused by their models), global moratoria, "CERN for AI" and similar. Generally, I endorse the proposals here.
None of these are easy, of course, there is a reason my p(doom) is high.
...But what hap
I think this is not an unreasonable position, yes. I expect the best way to achieve this would be to make global coordination and epistemology better/more coherent...which is bottlenecked by us running out of time, hence why I think the pragmatic strategic choice is to try to buy us more time.
One of the ways I can see a "slow takeoff/alignment by default" world still going bad is that in the run-up to takeoff, pseudo-AGIs are used to hypercharge memetic warfare/mutation load to a degree basically every living human is just functionally insane, and then even an aligned AGI can't (and wouldn't want to) "undo" that.
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
The fact you ask this question is interesting to me, because in my view the opposite question is the more natural one to ask: What kind of questions can you make progress on without constant grounding and dialogue with reality? This is the default of how we humans build knowledge and solve hard new questions, the places where we do best and get the least drawn astray is ...
As someone that does think about a lot of the things you care about at least some of the time (and does care pretty deeply), I can speak for myself why I don't talk about these things too much:
Epistemic problems:
- Mostly, the concept of "metaphilosophy" is so hopelessly broad that you kinda reach it by definition by thinking about any problem hard enough. This isn't a good thing, when you have a category so large it contains everything (not saying this applies to you, but it applies to many other people I have met who talked about metaphilosophy), it usually
It seems plausible that there is no such thing as "correct" metaphilosophy, and humans are just making up random stuff based on our priors and environment and that's it and there is no "right way" to do philosophy, similar to how there are no "right preferences"
If this is true, doesn't this give us more reason to think metaphilosophy work is counterfactually important, i.e., can't just be delegated to AIs? Maybe this isn't what Wei Dai is trying to do, but it seems like "figure out which approaches to things (other than preferences) that don't have 'right ...
I expect at this moment in time me building a company is going to help me deconfuse a lot of things about philosophy more than me thinking about it really hard in isolation would
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
...It seems plausible that there is no such thing as “correct” metaphilosophy, and humans are just making up random stuff based on our priors and environment and that’s it and there is no “right way”
As I have said many, many times before, Conjecture is not a deep shift in my beliefs about open sourcing, as it is not, and has never been, the position of EleutherAI (at least while I was head) that everything should be released in all scenarios, but rather that some specific things (such as LLMs of the size and strength we release) should be released in some specific situations for some specific reasons. EleutherAI would not, and has not, released models or capabilities that would push the capabilities frontier (and while I am no longer in charge, I stro...
I initially liked this post a lot, then saw a lot of pushback in the comments, mostly of the (very valid!) form of "we actually build reliable things out of unreliable things, particularly with computers, all the time". I think this is a fair criticism of the post (and choice of examples/metaphors therein), but I think it may be missing (one of) the core message(s) trying to be delivered.
I wanna give an interpretation/steelman of what I think John is trying to convey here (which I don't know whether he would endorse or not):
"There are important...
Yes, we do expect this to be the case. Unfortunately, I think explaining in detail why we think this may be infohazardous. Or at least, I am sufficiently unsure about how infohazardous it is that I would first like to think about it for longer and run it through our internal infohazard review before sharing more. Sorry!
Redwood is doing great research, and we are fairly aligned with their approach. In particular, we agree that hands-on experience building alignment approaches could have high impact, even if AGI ends up having an architecture unlike modern neural networks (which we don’t believe will be the case). While Conjecture and Redwood both have a strong focus on prosaic alignment with modern ML models, our research agenda has higher variance, in that we additionally focus on conceptual and meta-level research. We’re also training our own (large) models, but (we bel...
For the record, having any person or organization in this position would be a tremendous win. Interpretable aligned AGI?! We are talking about a top .1% scenario here! Like, the difference between egoistical Connor vs altruistic Connor with an aligned AGI in his hands is much much smaller than Connor with an aligned AGI and anyone, any organization or any scenario, with a misaligned AGI.
But let’s assume this.
Unfortunately, there is no actual functioning reliable mechanism by which humans can guarantee their alignment to each other. If there was s...
Probably. It is likely that we will publish a lot of our interpretability work and tools, but we can’t commit to that because, unlike some others, we think it’s almost guaranteed that some interpretability work will lead to very infohazardous outcomes. For example, obvious ways in which architectures could be trained more efficiently, and as such we need to consider each result on a case by case basis. However, if we deem them safe, we would definitely like to share as many of our tools and insights as possible.
We would love to collaborate with anyone (from academia or elsewhere) wherever it makes sense to do so, but we honestly just do not care very much about formal academic publication or citation metrics or whatever. If we see opportunities to collaborate with academia that we think will lead to interesting alignment work getting done, excellent!
Our current plan is to work on foundational infrastructure and models for Conjecture’s first few months, after which we will spin up prototypes of various products that can work with a SaaS model. After this, we plan to try them out and productify the most popular/useful ones.
More than profitability, our investors are looking for progress. Because of the current pace of progress, it would not be smart from their point of view to settle on a main product right now. That’s why we are mostly interested in creating a pipeline that lets us build and test out products flexibly.
Ideally, we would like Conjecture to scale quickly. Alignment wise, in 5 years time, we want to have the ability to take a billion dollars and turn it into many efficient, capable, aligned teams of 3-10 people working on parallel alignment research bets, and be able to do this reliably and repeatedly. We expect to be far more constrained by talent than anything else on that front, and are working hard on developing and scaling pipelines to hopefully alleviate such bottlenecks.
For the second question, we don't expect it to be a competing force (as in, we ha...
To point 1: While we greatly appreciate what OpenPhil, LTFF and others do (and hope to work with them in the future!), we found that the hurdles required and strings attached were far greater than the laissez-faire silicon valley VC we encountered, and seemed less scalable in the long run. Also, FTX FF did not exist back when we were starting out.
While EA funds as they currently exist are great at handing out small to medium sized grants, the ~8 digit investment we were looking for to get started asap was not something that these kinds of orgs were general...
The founders have a supermajority of voting shares and full board control and intend to hold on to both for as long as possible (preferably indefinitely). We have been very upfront with our investors that we do not want to ever give up control of the company (even if it were hypothetically to go public, which is not something we are currently planning to do), and will act accordingly.
For the second part, see the answer here.
To address the opening quote - the copy on our website is overzealous, and we will be changing it shortly. We are an AGI company in the sense that we take AGI seriously, but it is not our goal to accelerate progress towards it. Thanks for highlighting that.
We don’t have a concrete proposal for how to reliably signal that we’re committed to avoiding AGI race dynamics beyond the obvious right now. There is unfortunately no obvious or easy mechanism that we are aware of to accomplish this, but we are certainly open to discussion with any interested parties ab...
We (the founders) have a distinct enough research agenda to most existing groups such that simply joining them would mean incurring some compromises on that front. Also, joining existing research orgs is tough! Especially if we want to continue along our own lines of research, and have significant influence on their direction. We can’t just walk in and say “here are our new frames for GPT, can we have a team to work on this asap?”.
You’re right that SOTA models are hard to develop, but that being said, developing our own models is independently useful in ma...
See the reply to Michaël for answers as to what kind of products we will develop (TLDR we don’t know yet).
As for the conceptual research side, we do not do conceptual research with product in mind, but we expect useful corollaries to fall out by themselves for sufficiently good research. We think the best way of doing fundamental research like this is to just follow the most interesting, useful looking directions guided by the “research taste” of good researchers (with regular feedback from the rest of the team, of course). I for one at least genuinely exp...
See a longer answer here.
TL;DR: For the record, EleutherAI never actually had a policy of always releasing everything to begin with and has always tried to consider each publication’s pros vs cons. But this is still a bit of change from EleutherAI, mostly because we think it’s good to be more intentional about what should or should not be published, even if one does end up publishing many things. EleutherAI is unaffected and will continue working open source. Conjecture will not be publishing ML models by default, but may do so on a case by case ...
EAI has always been a community-driven organization that people tend to contribute to in their spare time, around their jobs. I for example have had a dayjob of one sort or another for most of EAI’s existence. So from this angle, nothing has changed aside from the fact my job is more demanding now.
Sid and I still contribute to EAI on the meta level (moderation, organization, deciding on projects to pursue), but do admittedly have less time to dedicate to it these days. Thankfully, Eleuther is not just us - we have a bunch of projects going on at any one ti...
We strongly encourage in person work - we find it beneficial to be able to talk over or debate research proposals in person at any time, it’s great for the technical team to be able to pair program or rubber duck if they’re hitting a wall, and all being located in the same city has a big impact on team building.
That being said, we don’t mandate it. Some current staff want to spend a few months a year with their families abroad, and others aren’t able to move to London at all. While we preferentially accept applicants who can work in person, we’re flexible, and if you’re interested but can’t make it to London, it’s definitely still worth reaching out.
We aren’t committed to any specific product or direction just yet (we think there are many low hanging fruit that we could decide to pursue). Luckily we have the independence to be able to initially spend a significant amount of time focusing on foundational infrastructure and research. Our product(s) could end up as some kind of API with useful models, interpretability tools or services, some kind of end-to-end SaaS product or something else entirely. We don’t intend to push the capabilities frontier, and don’t think this would be necessary to be profitable.
TL;DR: For the record, EleutherAI never actually had a policy of always releasing everything to begin with and has always tried to consider each publication’s pros vs cons. But this is still a bit of change from EleutherAI, mostly because we think it’s good to be more intentional about what should or should not be published, even if one does end up publishing many things. EleutherAI is unaffected and will continue working open source. Conjecture will not be publishing ML models by default, but may do so on a case by case basis.
Longer version:
Firs...
I really liked this post, though I somewhat disagree with some of the conclusions. I think that in fact aligning an artificial digital intelligence will be much, much easier than working on aligning humans. To point towards why I believe this, think about how many "tech" companies (Uber, crypto, etc) derive their value, primarily, from circumventing regulation (read: unfriendly egregore rent seeking). By "wiping the slate clean" you can suddenly accomplish much more than working in a field where the enemy already controls the terrain.
If you try to ta...
This was an excellent post, thanks for writing it!
But, I think you unfairly dismiss the obvious solution to this madness, and I completely understand why, because it's not at all intuitive where the problem in the setup of infinite ethics is. It's in your choice of proof system and interpretation of mathematics! (Don't use non-constructive proof systems!)
This is a bit of an esoteric point and I've been planning to write a post or even sequence about this for a while, so I won't be able to lay out the full arguments in one comment, but let me try to c...
I haven't read Critch in-depth, so I can't guarantee I'm pointing towards the same concept he is. Consider this a bit of an impromptu intuition dump, this might be trivial. No claims on originality of any of these thoughts and epistemic status "¯\_(ツ)_/¯"
The way I currently think about it is that multi-multi is the "full hard problem", and single-single is a particularly "easy" (still not easy) special case.
In a way we're making some simplifying assumptions in the single-single case. That we have one (pseudo-cartesian) "agent" that has some kind of d...
I am so excited about this research, good luck! I think it's almost impossible this won't turn up at least some interesting partial results, even if the strong versions of the hypothesis don't work out (my guess would be you run into some kind of incomputability or incoherence results in finding an algorithm that works for every environment).
This is one of the research directions that make me the most optimistic that alignment might really be tractable!
Thanks for the comment! I agree that we live in a highly suboptimal world, and I do not think we are going to make it, but it's worth taking our best shot.
I don't think of the CoEm agenda as "doing AGI right." (for one, it is not even an agenda for building AGI/ASI, but of bounding ourselves below that) Doing AGI right would involve solving problems like P vs PSPACE, developing vastly more deep understanding of Algorithmic Information Theory and more advanced formal verification of programs. If I had infinite budget and 200 years, the plan would look very ... (read more)