Posts
Wiki Contributions
The paper seems to be about scaling laws for a static dataset as well?
Similar to the initial study of scale in LLMs, we focus on the effect of scaling on a generative pre-training loss (rather than on downstream agent performance, or reward- or representation-centric objectives), in the infinite data regime, on a fixed offline dataset.
To learn to act you'd need to do reinforcement learning, which is massively less data-efficient than the current self-supervised training.
More generally: I think almost everyone thinks that you'd need to scale the right thing for further progress. The question is just what the right thing is if text is not the right thing. Because text encodes highly powerful abstractions (produced by humans and human culture over many centuries) in a very information dense way.
Related: https://en.wikipedia.org/wiki/Secretary_problem
The interesting thing is that scaling parameters (next big frontier models) and scaling data (small very good models) seems to be hitting a wall simultaneously. Small models now seem to get so much data crammed into them that quantisation becomes more and more lossy. So we seem to be reaching a frontier of the performance per parameter-bits as well.
I think the evidence mostly points towards 3+4,
But if 3 is due to 1 it would have bigger implications about 6 and probably also 5.
And there must be a whole bunch of people out there who know wether the curves bend.
It's funny how in the OP I agree with master morality and in your take I agree with slave morality. Maybe I value kindness because I don't think anybody is obligated to be kind?
Anyways, good job confusing the matter further, you two.
I actually originally thought about filtering with a weaker model, but that would run into the argument: "So you adversarially filtered the puzzles for those transformers are bad at and now you've shown that bigger transformers are also bad at them."
I think we don't disagree too much, because you are too damn careful ... ;-)
You only talk about "look-ahead" and you see this as on a spectrum from algo to pattern recognition.
I intentionally talked about "search" because it implies more deliberate "going through possible outcomes". I mostly argue about the things that are implied by mentioning "reasoning", "system 2", "algorithm".
I think if there is a spectrum from pattern recognition to search algorithm there must be a turning point somewhere: Pattern recognition means storing more and more knowledge to get better. A search algo means that you don't need that much knowledge. So at some point of the training where the NN is pushed along this spectrum much of this stored knowledge should start to be pared away and generalised into an algorithm. This happens for toy tasks during grokking. I think it doesn't happen in Leela.
I do have an additional dataset with puzzles extracted from Lichess games. Maybe I'll get around to running the analysis on that dataset as well.
I thought about an additional experiment one could run: Finetuning on tasks like help mates. If there is a learned algo that looks ahead, this should work much better than if the work is done by a ton of pattern recognition which is useless for the new task. Of course the result of such an experiment would probably be difficult to interpret.
I know, but I think Ia3orn said that the reasoning traces are hidden and only a summary is shown. And I haven't seen any information on a "thought-trace-condenser" anywhere.
There is a thought-trace-condenser?
Ok, then the high-level nature of some of these entries makes more sense.
Edit: Do you have a source for that?
No, I don't - but the thoughts are not hidden. You can expand them unter "Gedanken zu 6 Sekunden".
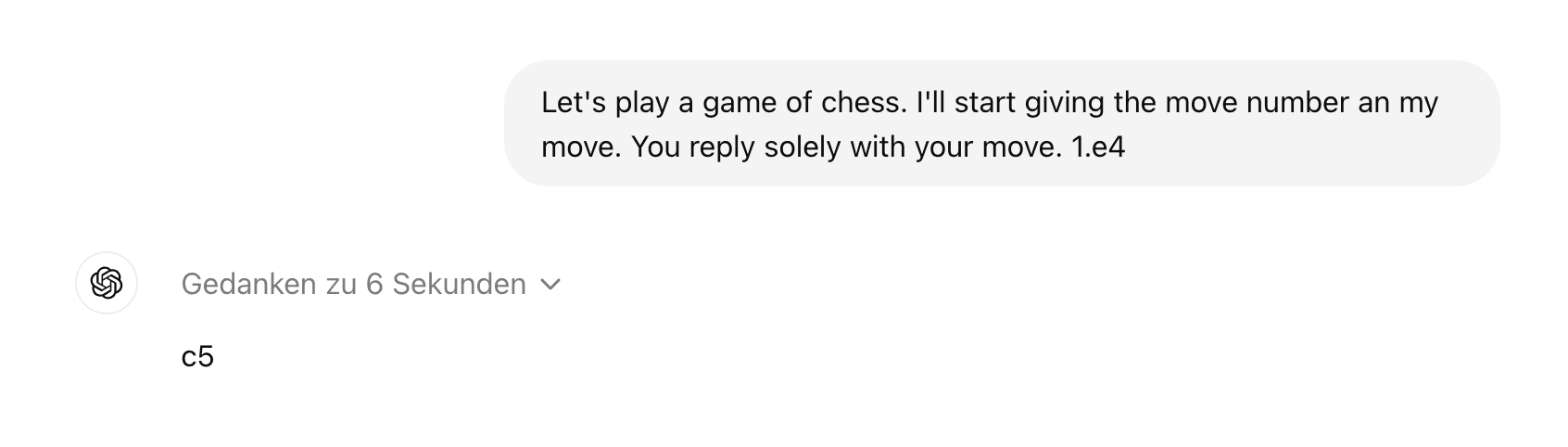
Which then looks like this:
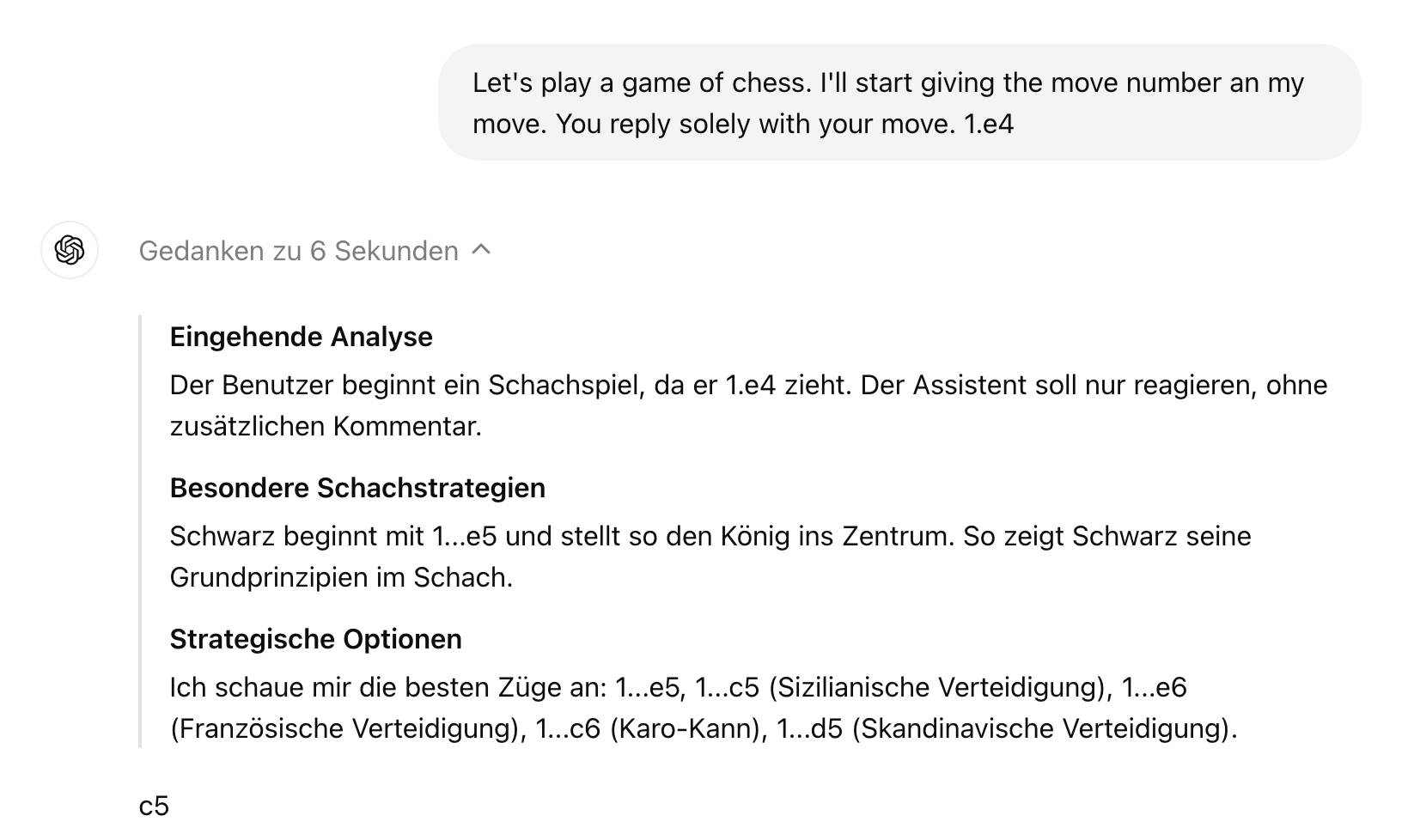
There was one comment on twitter that the RLHF-finetuned models also still have the ability to play chess pretty well, just their input/output-formatting made it impossible for them to access this ability (or something along these lines). But apparently it can be recovered with a little finetuning.