All of porby's Comments + Replies
These things are possible, yes. Those bad behaviors are not necessarily trivial to access, though.
- If you underspecify/underconstrain your optimization process, it may roam to unexpected regions permitted by that free space.
- It is unlikely that the trainer's first attempt at specifying the optimization constraints during RL-ish fine tuning will precisely bound the possible implementations to their truly desired target, even if the allowed space does contain it; underconstrained optimization is a likely default for many tasks.
- Which implementations are likely
Instrumentality exists on the simulacra level, not the simulator level. This would suggest that corrigibility could be maintained by establishing a corrigible character in context. Not clear on the practical implications.
That one, yup. The moment you start conditioning (through prompting, fine tuning, or otherwise) the predictor into narrower spaces of action, you can induce predictions corresponding to longer term goals and instrumental behavior. Effective longer-term planning requires greater capability, so one should expect this kind of thin...
There are lots of little things when it's not at a completely untenable level. Stuff like:
- Going up a flight or three of steps and really feeling it in my knees, slowing down, and saying 'hoo-oof.'
- Waking up and stepping out of bed and feeling general unpleasantness in my feet, ankles, knees, hips, or back.
- Quickly seeking out places to sit when walking around, particularly if there's also longer periods of standing, because my back would become terribly stiff.
- Walking on uneven surfaces and having a much harder time catching myself when I stumbled, not infreq
Hey, we met at EAGxToronto : )
🙋♂️
So my model of progress has allowed me to observe our prosaic scaling without surprise, but it doesn't allow me to make good predictions since the reason for my lack of surprise has been from Vingean prediction of the form "I don't know what progress will look like and neither do you".
This is indeed a locally valid way to escape one form of the claim—without any particular prediction carrying extra weight, and the fact that reality has to go some way, there isn't much surprise in finding yourself in any given world.
I do t...
I've got a fun suite of weird stuff going on[1], so here's a list of sometimes-very-N=1 data:
- Napping: I suck at naps. Despite being very tired, I do not fall asleep easily, and if I do fall asleep, it's probably not going to be for just 5-15 minutes. I also tend to wake up with a lot of sleep inertia, so the net effect of naps on alertness across a day tends to be negative. They also tend to destroy my sleep schedule.
- Melatonin: probably the single most noticeable non-stimulant intervention. While I'm by-default very tired all the time, it's still har
But I disagree that there’s no possible RL system in between those extremes where you can have it both ways.
I don't disagree. For clarity, I would make these claims, and I do not think they are in tension:
- Something being called "RL" alone is not the relevant question for risk. It's how much space the optimizer has to roam.
- MuZero-like strategies are free to explore more space than something like current applications of RLHF. Improved versions of these systems working in more general environments have the capacity to do surprising things and will tend to be
It does still apply, though what 'it' is here is a bit subtle. To be clear, I am not claiming that a technique that is reasonably describable as RL can't reach extreme capability in an open-ended environment.
The precondition I included is important:
in the absence of sufficient environmental structure, reward shaping, or other sources of optimizer guidance, it is nearly impossible for any computationally tractable optimizer to find any implementation for a sparse/distant reward function
In my frame, the potential future techniques you mention are forms of op...
Calling MuZero RL makes sense. The scare quotes are not meant to imply that it's not "real" RL, but rather that the category of RL is broad enough that it belonging to it does not constrain expectation much in the relevant way. The thing that actually matters is how much the optimizer can roam in ways that are inconsistent with the design intent.
For example, MuZero can explore the superhuman play space during training, but it is guided by the structure of the game and how it is modeled. Because of that structure, we can be quite confident that the optimizer isn't going to wander down a path to general superintelligence with strong preferences about paperclips.
I do think that if you found a zero-RL path to the same (or better) endpoint, it would often imply that you've grasped something about the problem more deeply, and that would often imply greater safety.
Some applications of RL are also just worse than equivalent options. As a trivial example, using reward sampling to construct a gradient to match a supervised loss gradient is adding a bunch of clearly-pointless intermediate steps.
I suspect there are less trivial cases, like how a decision transformer isn't just learning an optimal policy for its dataset but...
"RL" is a wide umbrella. In principle, you could even train a model with RL such that the gradients match supervised learning. "Avoid RL" is not the most directly specified path to the-thing-we-actually-want.
The source of spookiness
Consider two opposite extremes:
- A sparse, distant reward function. A biped must successfully climb a mountain 15 kilometers to the east before getting any reward at all.
- A densely shaped reward function. At every step during the climb up the mountain, there is a reward designed to induce gradients that maximize training performanc
Stated as claims that I'd endorse with pretty high, but not certain, confidence:
- There exist architectures/training paradigms within 3-5 incremental insights of current ones that directly address most incapabilities observed in LLM-like systems. (85%; if false, my median strong AI estimate would jump by a few years, p(doom) effect would vary depending on how it was falsified)
- It is not an accident that the strongest artificial reasoners we have arose from something like predictive pretraining. In complex and high dimensional problem spaces like general reaso
Has there been any work on the scaling laws of out-of-distribution capability/behavior decay?
A simple example:
- Simultaneously train task A and task B for N steps.
- Stop training task B, but continue to evaluate the performance of both A and B.
- Observe how rapidly task B performance degrades.
Repeat across scale and regularization strategies.
Would be nice to also investigate different task types. For example, tasks with varying degrees of implied overlap in underlying mechanisms (like #2).
I've previously done some of these experiments privately, but not with nea...
A further extension and elaboration on one of the experiments in the linkpost:
Pitting execution fine-tuning against input fine-tuning also provides a path to measuring the strength of soft prompts in eliciting target behaviors. If execution fine-tuning "wins" and manages to produce a behavior in some part of input space that soft prompts cannot elicit, it would be a major blow to the idea that soft prompts are useful for dangerous evaluations.
On the flip side, if ensembles of large soft prompts with some hyperparameter tuning always win (e.g. execution fin...
Having escaped infinite overtime associated with getting the paper done, I'm now going back and catching up on some stuff I couldn't dive into before.
Going through the sleeper agents paper, it appears that one path—adversarially eliciting candidate backdoor behavior—is hampered by the weakness of the elicitation process. Or in other words, there exist easily accessible input conditions that trigger unwanted behavior that LLM-driven adversarial training can't identify.
I alluded to this in the paper linkpost, but soft prompts are a very simple and very stron...
By the way: I just got into San Francisco for EAG, so if anyone's around and wants to chat, feel free to get in touch on swapcard (or if you're not in the conference, perhaps a DM)! I fly out on the 8th.
It's been over a year since the original post and 7 months since the openphil revision.
A top level summary:
- My estimates for timelines are pretty much the same as they were.
- My P(doom) has gone down overall (to about 30%), and the nature of the doom has shifted (misuse, broadly construed, dominates).
And, while I don't think this is the most surprising outcome nor the most critical detail, it's probably worth pointing out some context. From NVIDIA:
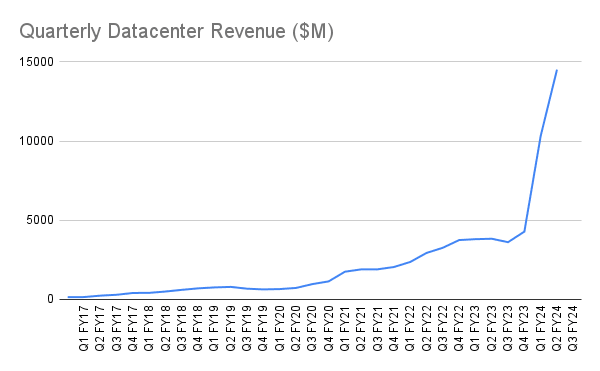
In two quarters, from Q1 FY24 to Q3 FY24, datacenter revenues went from $4.28B to $14.51B.
From the post:
...In 3 year
Mine:
My answer to "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better)" is pretty much defined by how the question is interpreted. It could swing pretty wildly, but the obvious interpretation seems ~tautologically bad.
I'm accumulating a to-do list of experiments much faster than my ability to complete them:
- Characterizing fine-tuning effects with feature dictionaries
- Toy-scale automated neural network decompilation (difficult to scale)
- Trying to understand evolution of internal representational features across blocks by throwing constraints at it
- Using soft prompts as a proxy measure of informational distance between models/conditions and behaviors (see note below)
- Prompt retrodiction for interpreting fine tuning, with more difficult extension for activation matching
- Mi
Retrodicting prompts can be useful for interpretability when dealing with conditions that aren't natively human readable (like implicit conditions induced by activation steering, or optimized conditions from soft prompts). Take an observed completion and generate the prompt that created it.
What does a prompt retrodictor look like?
Generating a large training set of soft prompts to directly reverse would be expensive. Fortunately, there's nothing special in principle about soft prompts with regard to their impact on conditioning predictions.
Just take large t...
Another potentially useful metric in the space of "fragility," expanding on #4 above:
The degree to which small perturbations in soft prompt embeddings yield large changes in behavior can be quantified. Perturbations combined with sampling the gradient with respect to some behavioral loss suffices.
This can be thought of as a kind of internal representational fragility. High internal representational fragility would imply that small nudges in the representation can blow up intent.
Does internal representational fragility correlate with other notions of "fragi...
A further extension: While relatively obvious in context, this also serves as a great way to automate adversarial jailbreak attempts (broadly construed), and to quantify how resistant a given model or prompting strategy is to jailbreaks.
Set up your protections, then let SGD try to jailbreak it. The strength of the protections can be measured by the amount of information required to overcome the defenses to achieve some adversarial goal.
In principle, a model could be perfectly resistant and there would be no quantity of information sufficient to break it. T...
Expanding on #6 from above more explicit, since it seems potentially valuable:
From the goal agnosticism FAQ:
The definition as stated does not put a requirement on how "hard" it needs to be to specify a dangerous agent as a subset of the goal agnostic system's behavior. It just says that if you roll the dice in a fully blind way, the chances are extremely low. Systems will vary in how easy they make it to specify bad agents.
From earlier experimentpost:
...Figure out how to think about the "fragility" of goal agnostic systems. Conditioning a predictor can easily
Soft prompts are another form of prompt automation that should naturally preserve all the nice properties of goal agnostic architectures.
Does training the model to recognize properties (e.g. 'niceness') explicitly as metatokens via classification make soft prompts better at capturing those properties?
You could test for that explicitly:
- Pretrain model A with metatokens with a classifier.
- Pretrain model B without metatokens.
- Train soft prompts on model A with the same classifier.
- Train soft prompts on model B with the same classifier.
- Compare performance of soft
Quarter-baked experiment:
- Stick a sparse autoencoder on the residual stream in each block.
- Share weights across autoencoder instances across all blocks.
- Train autoencoder during model pretraining.
- Allow the gradients from autoencoder loss to flow into the rest of the model.
Why? With shared autoencoder weights, every block is pushed toward sharing a representation. Questions:
- Do the meanings of features remain consistent over multiple blocks? What does it mean for an earlier block's feature to "mean" the same thing as a later block's same feature when they're at
I think that'd be great!
Some of this stuff technically accelerates capabilities (or more specifically, the elicitation of existing capabilities), but I think it also belongs to a more fundamentally reliable path on the tech tree. The sooner the industry embraces it, the less time they spend in other parts of the tech tree that are more prone to misoptimization failures, and the less likely it is that someone figures out how to make those misoptimization failures way more efficient.
I suspect there's a crux about the path of capabilities development in there for a lot of people; I should probably get around to writing a post about the details at some point.
What I'm calling a simulator (following Janus's terminology) you call a predictor
Yup; I use the terms almost interchangeably. I tend to use "simulator" when referring to predictors used for a simulator-y use case, and "predictor" when I'm referring to how they're trained and things directly related to that.
I also like your metatoken concept: that's functionally what I'm suggesting for the tags in my proposal, except I follow the suggestion of this paper to embed them via pretraining.
Yup again—to be clear, all the metatoken stuff I was talking about would a...
Signal boosted! This is one of those papers that seems less known that it should be. It's part of the reason why I'm optimistic about dramatic increases in the quality of "prosaic" alignment (in the sense of avoiding jailbreaks and generally behaving as expected) compared to RLHF, and I think it's part of a path that's robust enough to scale.
You can compress huge prompts into metatokens, too (just run inference with the prompt to generate the training data). And nest and remix metatokens together.
It's also interesting in that it can preserve the constraint...
I claim we are many scientific insights away from being able to talk about these questions at the level of precision necessary to make predictions like this.
Hm, I'm sufficiently surprised at this claim that I'm not sure that I understand what you mean. I'll attempt a response on the assumption that I do understand; apologies if I don't:
I think of tools as agents with oddly shaped utility functions. They tend to be conditional in nature.
A common form is to be a mapping between inputs and outputs that isn't swayed by anything outside of the context of that m...
While this probably isn't the comment section for me to dump screeds about goal agnosticism, in the spirit of making my model more legible:
I think that if it is easy and obvious how to make a goal-agnostic AI into a goal-having AI, and also it seems like doing so will grant tremendous power/wealth/status to anyone who does so, then it will get done. And do think that these things are the case.
Yup! The value I assign to goal agnosticism—particularly as implemented in a subset of predictors—is in its usefulness as a foundation to build strong non-goal agnost...
Another experiment:
- Train model M.
- Train sparse autoencoder feature extractor for activations in M.
- FT = FineTune(M), for some form of fine-tuning function FineTune.
- For input x, fineTuningBias(x) = FT(x) - M(x)
- Build a loss function on top of the fineTuningBias function. Obvious options are MSE or dot product with bias vector.
- Backpropagate the loss through M(x) into the feature dictionaries.
- Identify responsible features by large gradients.
- Identify what those features represent (manually or AI-assisted).
- To what degree do those identified features line up with t
Some experimental directions I recently wrote up; might as well be public:
- Some attempts to demonstrate how goal agnosticism breaks with modifications to the architecture and training type. Trying to make clear the relationship between sparsity/distance of the implicit reward function and unpredictability of results.
- A continuation and refinement of my earlier (as of yet unpublished) experiments about out of distribution capability decay. Goal agnosticism is achieved by bounding the development of capabilities into a shape incompatible with internally motiva
In retrospect, the example I used was poorly specified. It wouldn't surprise me if the result of the literal interpretation was "the AI refuses to play chess" rather than any kind of worldeating. The intent was to pick a sparse/distant reward that doesn't significantly constrain the kind of strategies that could develop, and then run an extreme optimization process on it. In other words, while intermediate optimization may result in improvements to chess playing, being better at chess isn't actually the most reliable accessible strategy to "never lose at chess" for that broader type of system and I'd expect superior strategies to be found in the limit of optimization.
But the point is that in this scenario the LM doesn't want anything in the behaviorist sense, yet is a perfectly adequate tool for solving long-horizon tasks. This is not the form of wanting you need for AI risk arguments.
My attempt at an ITT-response:
Drawing a box around a goal agnostic LM and analyzing the inputs and outputs of that box would not reveal any concerning wanting in principle. In contrast, drawing a box around a combined system—e.g. an agentic scaffold that incrementally asks a strong inner goal agnostic LM to advance the agent's process—cou...
Trying to respond in what I think the original intended frame was:
A chess AI's training bounds what the chess AI can know and learn to value. Given the inputs and outputs it has, it isn't clear there is an amount of optimization pressure accessible to SGD which can yield situational awareness and so forth; nothing about the trained mapping incentivizes that. This form of chess AI can be described in the behaviorist sense as "wanting" to win within the boundaries of the space that it operates.
In contrast, suppose you have a strong and knowledgeable multimod...
you mention « restrictive », my understanding is that you want this expression to specifically refers to pure predictors. Correct?
Goal agnosticism can, in principle, apply to things which are not pure predictors, and there are things which could reasonably be called predictors which are not goal agnostic.
A subset of predictors are indeed the most powerful known goal agnostic systems. I can't currently point you toward another competitive goal agnostic system (rocks are uselessly goal agnostic), but the properties of goal agnosticism do, in concept, extend ...
I'm not sure if I fall into the bucket of people you'd consider this to be an answer to. I do think there's something important in the region of LLMs that, by vibes if not explicit statements of contradiction, seems incompletely propagated in the agent-y discourse even though it fits fully within it. I think I at least have a set of intuitions that overlap heavily with some of the people you are trying to answer.
In case it's informative, here's how I'd respond to this:
...Well, I claim that these are more-or-less the same fact. It's no surprise that the AI fal
This isn't directly evidence, but I think it's worth flagging: by the nature the topic, much of the most compelling evidence is potentially hazardous. This will bias the kinds of answers you can get.
(This isn't hypothetical. I don't have some One Weird Trick To Blow Up The World, but there's a bunch of stuff that falls under the policy "probably don't mention this without good reason out of an abundance of caution.")
…but I thought the criterion was unconditional preference? The idea of nausea is precisely because agents can decide to act despite nausea, they’d just rather find a better solution (if their intelligence is up to the task).
Right; a preference being conditionally overwhelmed by other preferences does not make the presence of the overwhelmed preference conditional.
Or to phrase it another way, suppose I don't like eating bread[1] (-1 utilons), but I do like eating cheese (100 utilons) and garlic (1000 utilons).
You ask me to choose between garlic bread (...
For example, a system that avoids experimenting on humans—even when prompted to do so otherwise—is expressing a preference about humans being experimented on by itself.
Being meaningfully curious will also come along with some behavioral shift. If you tried to induce that behavior in a goal agnostic predictor through conditioning for being curious in that way and embed it in an agentic scaffold, it wouldn't be terribly surprising for it to, say, set up low-interference observation mechanisms.
Not all violations of goal agnosticism necessarily yield doom, but even prosocial deviations from goal agnosticism are still deviations.
I think what we're discussing requires approaching the problem with a mindset entirely foreign to the mainstream one. Consider how many words it took us to get to this point in the conversation, despite the fact that, as it turns out, we basically agree on everything. The inferential distance between the standard frameworks in which AI researchers think, and here, is pretty vast.
True!
...I expect that if the mainstream AI researchers do make strides in the direction you're envisioning, they'll only do it by coincidence. Then probably they won't even realize wh
I assume that by "lower-level constraints" you mean correlations that correctly capture the ground truth of reality, not just the quirks of the training process. Things like "2+2=4", "gravity exists", and "people value other people"
That's closer to what I mean, but these constraints are even lower level than that. Stuff like understanding "gravity exists" is a natural internal implementation that meets some constraints, but "gravity exists" is not itself the constraint.
In a predictor, the constraints serve as extremely dense information about what pr...
I'm using as a "an optimization constraint on actions/plans that correlated well with good performance on the training dataset; a useful heuristic".
Alright, this is pretty much the same concept then, but the ones I'm referring to operate at a much lower and tighter level than thumbs-downing murder-proneness.
So...
Such constraints are, for example, the reason our LLMs are able to produce coherent speech at all, rather than just babbling gibberish.
Agreed.
...... and yet this would still get in the way of qualitatively more powerful capabilities down the line, and
I think we're using the word "constraint" differently, or at least in different contexts.
Sure! Human values are not arbitrary either; they, too, are very heavily constrained by our instincts. And yet, humans still sometimes become omnicidal maniacs, Hell-worshipers, or sociopathic power-maximizers. How come?
In terms of the type and scale of optimization constraint I'm talking about, humans are extremely unconstrained. The optimization process represented by our evolution is way out there in terms of sparsity and distance. Not maximally so—there are all sor...
My model says that general intelligence[1] is just inextricable from "true-goal-ness". It's not that I think homunculi will coincidentally appear as some side-effect of capability advancement — it's that the capabilities the AI Labs want necessarily route through somehow incentivizing NNs to form homunculi. The homunculi will appear inasmuch as the labs are good at their jobs.
I've got strong doubts about the details of this. At the high level, I'd agree that strong/useful systems that get built will express preferences over world states like those tha...
This is great research and I like it!
I'd be interested in knowing more about how the fine-tuning is regularized and the strength of any KL-divergence-penalty-ish terms. I'm not clear on how the openai fine-tuning API works here with default hypers.
By default, I would expect that optimizing for a particular narrow behavior with no other constraints would tend to bring along a bunch of learned-implementation-dependent correlates. Representations and circuitry will tend to serve multiple purposes, so if strengthening one particular dataflow happens to strengt... (read more)