All of reallyeli's Comments + Replies
A good ask for frontier AI companies, for avoiding massive concentration of power, might be:
- "don't have critical functions controllable by the CEO alone or any one person alone, and check that this is still the case / check for backdoors periodically"
since this seems both important and likely to be popular.
The obvious problem is that doing the full post-training is not cheap, so you may need some funding
(I'm Open Phil staff) If you're seeking funding to extend this work, apply to Open Phil's request for proposals on technical safety research.
This section feels really important to me. I think it's somewhat plausible and big if true.
Was surprised to see you say this; isn't this section just handwavily saying "and here, corrigibility is solved"? While that also seems plausible and big if true to me, it doesn't leave much to discuss — did you interpret differently though?
I work as a grantmaker on the Global Catastrophic Risks Capacity-Building team at Open Philanthropy; a large part of our funding portfolio is aimed at increasing the human capital and knowledge base directed at AI safety. I previously worked on several of Open Phil’s grants to Lightcone.
As part of my team’s work, we spend a good deal of effort forming views about which interventions have or have not been important historically for the goals described in my first paragraph. I think LessWrong and the Alignment Forum have been strongly positive for these...
In your imagining of the training process, is there any mechanism via which the AI might influence the behavior of future iterations of itself, besides attempting to influence the gradient update it gets from this episode? E.g. leaving notes to itself, either because it's allowed to as an intentional part of the training process, or because it figured out how to pass info even though it wasn't intentionally "allowed" to.
It seems like this could change the game a lot re: the difficulty of goal-guarding, and also may be an important disanalogy between traini...
Stackoverflow has long had a "bounty" system where you can put up some of your karma to promote your question. The karma goes to the answer you choose to accept, if you choose to accept an answer; otherwise it's lost. (There's no analogue of "accepted answer" on LessWrong, but thought it might be an interesting reference point.)
I lean against the money version, since not everyone has the same amount of disposable income and I think there would probably be distortionary effects in this case [e.g. wealthy startup founder paying to promote their monographs.]
What about puns? It seems like at least some humor is about generic "surprise" rather than danger, even social danger. Another example is absurdist humor.
Would this theory pin this too on the danger-finding circuits -- perhaps in the evolutionary environment, surprise was in fact correlated with danger?
It does seem like some types of surprise have the potential to be funny and others don't -- I don't often laugh while looking through lists of random numbers.
I think the A/B theory would say that lists of random numbers don't have enough "evidence that I'm s...
Interested in my $100-200k against your $5-10k.
This seems tougher for attackers because experimentation with specific humans is much costlier than experimentation with automated systems.
(But I'm unsure of the overall dynamics in this world!)
:thumbsup: Looks like you removed it on your blog, but you may also want to remove it on the LW post here.
Beyond acceleration, there would be serious risks of misuse. The most direct case is cyberoffensive hacking capabilities. Inspecting a specific target for a specific style of vulnerability could likely be done reliably, and it is easy to check if an exploit succeeds (subject to being able to interact with the code)
This one sticks out because cybersecurity involves attackers and defenders, unlike math research. Seems like the defenders would be able to use GPT_2030 in the same way to locate and patch their vulnerabilities before the attackers do.
It feels li...
Appreciated this post.
ChatGPT has already been used to generate exploits, including polymorphic malware, which is typically considered to be an advanced offensive capability.
I found the last link at least a bit confusing/misleading, and think it may just not support the point. As stated, it sounds like ChatGPT was able to write a particularly difficult-to-write piece of malware code. But the article instead seems to be a sketch of a design of malware that would incorporate API calls to ChatGPT, e.g. 'okay we're on the target machine, we want to search thei...
On a retry, it didn't decide to summarize the board and successfully listed a bunch of legal moves for White to make. Although I asked for all legal moves, the list wasn't exhaustive; upon prompting about this, it apologized and listed a few more moves, some of which were legal and some which were illegal, still not exhaustive.
This is pretty funny because the supposed board state has only 7 columns
Hah, I didn't even notice that.
Also, I've never heard of using upper and lowercase to differentiate white and black, I think GPT-4 just made that up.
XD
Caleb Parikh and I were curious about GPT-4's internal models of chess as a result of this post, so we asked it some questions about the state partway through this game:
The following is a partial chess transcript in PGN. Please describe all legal moves that could come next. 1. d4 Nf6 2. c4 e6 3. Nf3 d5 4. Nc3 Be7 5. Bf4 O-O 6. Nb5 $2 Na6 $9
It replied:
...The current position after 1. d4 Nf6 2. c4 e6 3. Nf3 d5 4. Nc3 Be7 5. Bf4 O-O 6. Nb5 Na6 is as follows:
8 r b q r p b p 7 p p b n p p p 6 n . . p . n . 5 . N . . p . . 4 . . P P . B . 3 . . . . N . . 2 P P . .
I think this is taking aim at Yudkowskian arguments that are not cruxy for AI takeover risk as I see it. The second species doesn't need to be supercoherent in order to kill us or put us in a box; human levels of coherence will do fine for that.
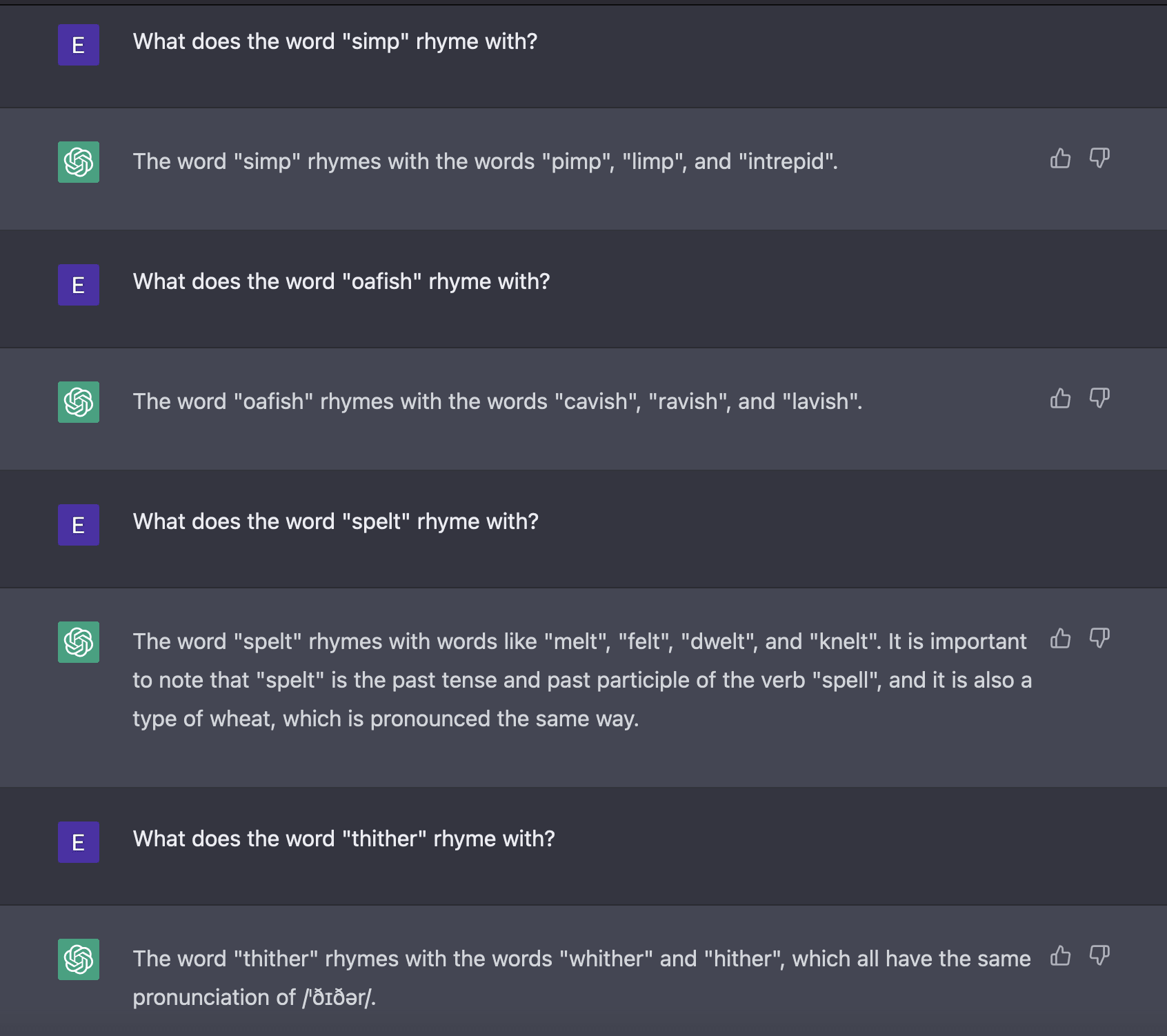
What specific rhyme-related tasks are you saying ChatGPT can't do? I tried it on some unusual words and it got a bunch of things right, made a few weird mistakes, but didn't give me the impression that it was totally unable to rhyme unusual words.
I don't think that response makes sense. The classic instrumental convergence arguments are about a single agent; OP is asking why distinct AIs would coordinate with one another.
I think the AIs may well have goals that conflict with one another, just as humans' goals do, but it's plausible that they would form a coalition and work against humans' interests because they expect a shared benefit, as humans sometimes do.
I don't think this is an important obstacle — you could use something like "and act such that your P(your actions over the next year lead to a massive disaster) < 10^-10." I think Daniel's point is the heart of the issue.
Should
serious problems with Boltzmann machines
instead read
serious problems with Boltzmann brains
?
I don't think observing that folks in the Middle East drink much less, due to a religious prohibition, is evidence for or against this post's hypothesis. It can simultaneously be the case that evolution discovered this way of preventing alcoholism, and also that religious prohibitions are a much more effective way of preventing alcoholism.
I had the "Europeans evolved to metabolize alcohol" belief that this post aims to destroy. Thanks!
This post gave me the impression that the evolutionary explanation it gives is novel, but I don't think that's the case; here's a paper (https://bmcecolevol.biomedcentral.com/articles/10.1186/1471-2148-10-15#Sec6) that mentions the same hypothesis.
In
Okay. Though in the real world, it's quite likely that an unknown frequency is exactly , , or
should the text read "unlikely" instead of "likely" ?
+1 to copper tape being difficult to get off.
(Not related to the overall point of your paper) I'm not so sure that GPT-3 "has the internal model to do addition," depending on what you mean by that — nostalgebraist doesn't seem to think so in this post, and a priori this seems like a surprising thing for a feedforward neural network to do.
Can you give some examples?
Like a belief that you've discovered a fantastic investment opportunity, perhaps?
I'm interested — 10 please.
Caveat that I have no formal training in physics.
Perhaps you already know this, but some of your statements made me think you don't. In an electric circuit, individual electrons do not move from the start to the end at the speed of light. Instead, they move much more slowly. This is true regardless of whether the current is AC or DC.
The thing that travels at the speed of light is the *information* that a push has happened. There's an analogy to a tube of ping-pong balls, where pushing on one end will cause the ball at the other end to move very soon, even though no individual ball is moving very quickly.
(I'll back off the Superman analogy; I think it's disanalogous b/c of the discontinuity thing you point out.)
Yeah I like the analogue "some basketball players are NBA players." It makes it sound totally unsurprising, which it is.
I don't agree that Vox is right, because:
- I can't find any evidence for the claim that forecasting ability is power-law distributed, and it's not clear what that would mean with Brier scores (as Unnamed points out).
- Their use of the term "discovered."
I don't think I'm jus...
Agree re: power law.
The data is here https://dataverse.harvard.edu/dataverse/gjp?q=&types=files&sort=dateSort&order=desc&page=1 , so I could just find out. I posted here trying to save time, hoping someone else would already have done the analysis.
Thanks for your reply!
It looks to me like we might be thinking about different questions. Basically I'm just concerned about the sentence "Philip Tetlock discovered that 2% of people are superforecasters." When I read this sentence, it reads to me like "2% of people are superheroes" — they have performance that is way better than the rest of the population on these tasks. If you graphed "jump height" of the population and 2% of the population is Superman, there would be a clear discontinuity at the higher end. That...
If you graphed "jump height" of the population and 2% of the population is Superman, there would be a clear discontinuity at the higher end.
But note that the section you quote from Vox doesn't say that there's any discontinuity:
Tetlock and his collaborators have run studies involving tens of thousands of participants and have discovered that prediction follows a power law distribution.
A power law distribution is not a discontinuity! Some people are way way better than others. Other people are merely way better than others. And still oth...
Hmm, thanks for pointing that out about Brier scores. The Vox article cites https://www.vox.com/2015/8/20/9179657/tetlock-forecasting for its "power law" claim, but that piece says nothing about power laws. It does have a graph which depicts a wide gap between "superforecasters" and "top-team individuals" in years 2 and 3 of the project, and not in year 1. But my understanding is that this is because the superforecasters were put together on elite teams after the first year, so I think the graph is a bit misleading.
(Citation:...
I definitely imagine looking at a graph of everyone's performance on the predictions and noticing a cluster who are discontinuously much better than everyone else. I would be surprised if the authors of the piece didn't imagine this as well.
Some evidence against this is that they described it as being a "power law" distribution, which is continuous and doesn't have these kinds of clusters. (It just goes way way up as you move to the right.)
If you had a power law distribution, it would still be accurate to say that "a few are b...
What was the purpose of using octopuses in this metaphor? Like, it seems you've piled on so many disanalogies to actual octopuses (extremely smart, many generations per year, they use Slack...) that you may as well just have said "AIs."
EDIT: Is it gradient descent vs. evolution?
I found it helpful because it put me in the frame of a alien biological intelligence rather than an AI because I have lots of preconceptions about AIs and it's it's easy to implicitly think in terms of expected utility maximizers or tools or whatever. While if I'm imagining an octopus, I'm kind of imagining humans, but a bit weirder and more alien, and I would not trust humans