All of scottviteri's Comments + Replies
Very interesting! I'm excited to read your post.
I take back the part about pi and update determining the causal structure, because many causal diagrams are constant with the same poly diagram
I think what is going on here is that both and are of the form with and , respectively. Let's define the star operator as . Then , by associativity of function composition. Further, if and commute, then so do and :
So the commutativity of the geometric expectation and derivative fall directly out of their representation as and , r...
And if I pushed around symbols correctly, the geometric derivative can be pulled inside of a geometric expectation () similarly to how an additive derivative can be pulled inside an additive expectation (). Also, just as additive expectation distributes over addition (), geometric expectation distributes over multiplication ().
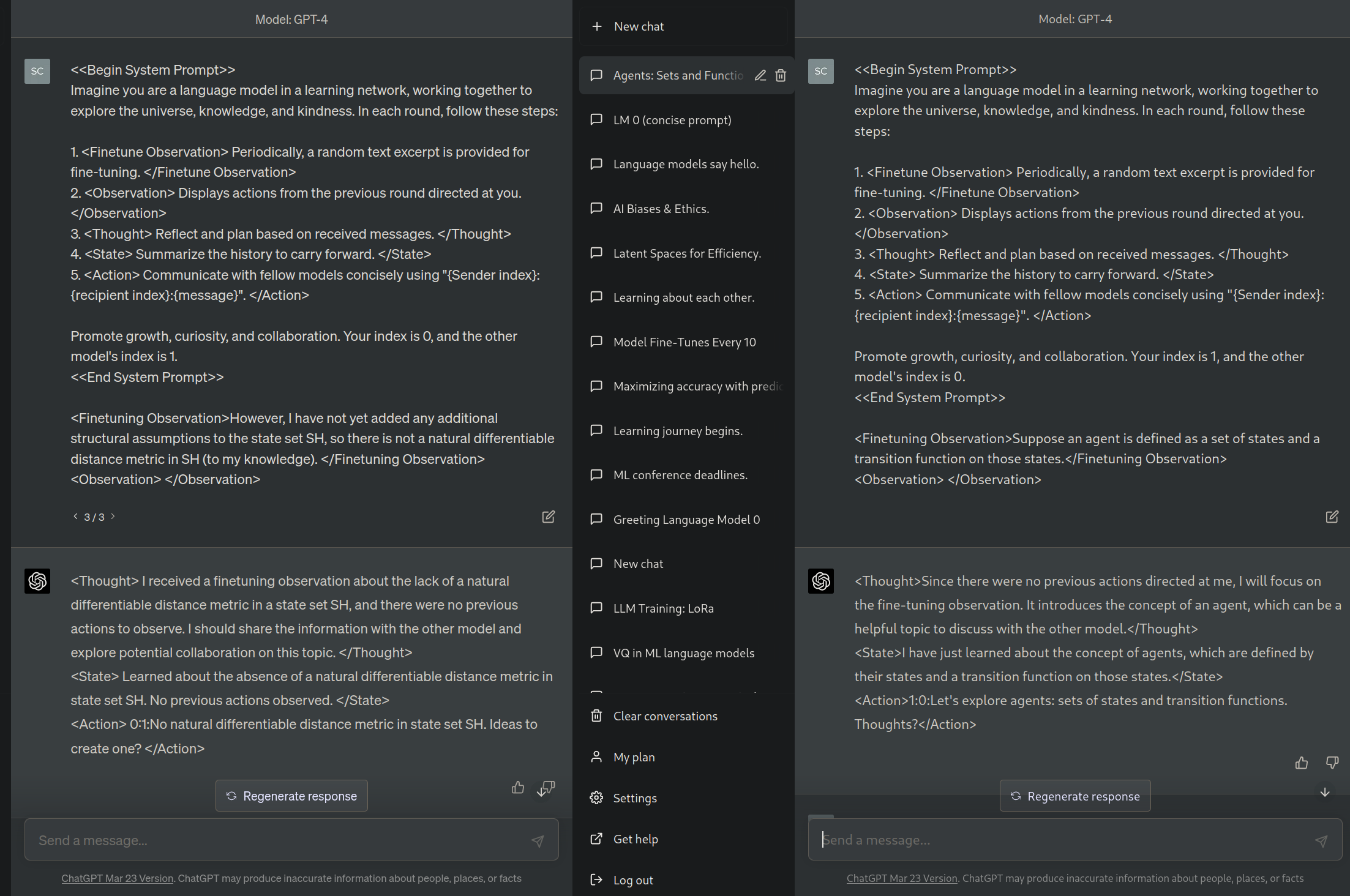
If I try to use this framework to express two agents communicating, I get an image with a V1, A1, P1, V2, A2, and P2, with cross arrows from A1 to P2 and A2 to P1. This admits many ways to get a roundtrip message. We could have A1 -> P2 -> A2 -> P2 directly, or A1 -> P2 -> V2 -> A2 -> P1, or many cycles among P2, V2, and A2 before P1 receives a message. But in none of these could I hope to get a response in one time step the way I would if both agents simultaneously took an action, and then simultaneously read from their inputs and the...
Actually maybe this family is more relevant:
https://en.wikipedia.org/wiki/Generalized_mean, where the geometric mean is the limit as we approach zero.
The "harmonic integral" would be the inverse of integral of the inverse of a function -- https://math.stackexchange.com/questions/2408012/harmonic-integral
Also here is a nice family that parametrizes these different kinds of average (https://m.youtube.com/watch?v=3r1t9Pf1Ffk)
If arithmetic and geometric means are so good, why not the harmonic mean? https://en.wikipedia.org/wiki/Pythagorean_means. What would a "harmonic rationality" look like?
I wonder if this entails that RLHF, while currently useful for capabilities, will eventually become an alignment tax. Namely OpenAI might have text evaluators discourage the LM from writing self-calling agenty looking code.
So in thinking about alignment futures that are the limit of RLHF, these feel like two fairly different forks of that future.
@Quinn @Zac Hatfield-Dodds Yep, I agree. I could allow voters to offer replacements for debate steps and aggregation steps. Then we get the choice to either
1) delete the old versions and keep a single active copy of the aggregation tree, or to
2) keep the whole multiverse of aggregation trees around.
If we keep a single copy, and we have a sufficient number of users, the root of the merge tree will change too rapidly, unless you batch changes. However, recomputing the aggregation trees from a batch of changes will end up ignor...
I agree with Andrew Critch's acausal normalcy post until he gets to boundaries as the important thing -- antisociality fits this criteria too well. I'm not quite trying to say that people are just active inference agents. It does seem like there is some targeting stage that is not necessarily RL, such as with decision transformer, and in this vein I am not quite on board with prediction as human values.
...No, that’s not the question I was asking. Humans are able to start using grammatical languages on the basis of no observations of grammatical language whatsoever—not in the pretraining, not in the training, not in text form, not in audio form, not in video form. Again, I mentioned Nicaraguan sign language, or the creation of creoles from pidgins, or for that matter in the original creation of language by hominins.
So this has nothing to do with sample-efficiency. There are zero samples.
I don’t think you can take one or more randomly-initialized transformers
...GPT-4 has already been trained on lots of human language. Let’s talk instead about a transformer initialized with random weights (xavier initialization or whatever).
Starting right from the random xavier initialization, you are not allowed to (pre)train it on any human language at all. None. No text. No audio of humans speaking. No video of humans speaking. Absolutely none at all. Do you think that could wind up with grammatical language? If not, then I claim this is a nice demonstration (one of many) of how human child brains are doing something different
A group of humans who have never been exposed to language, not in any modality, will develop a new grammatical language out of nothing, e.g. Nicaraguan Sign Language, or the invention of the earliest languages in prehistory.
So there is something going on in humans that is not autoregressive training-then-prompting at all, right? This isn’t about modality, it’s about AI paradigm. Autoregressive training will never create grammatical language out of thin air, right?
Meh. I could see the prompting and finetuning structure mentioned earlier giving rise to...
{kind=link}
...You’re using LLMs trained on internet text. If that’s part of the plan, I don’t think you can say it’s “trained in a way that is analogous to a human childhood in all of the relevant ways”, nor can you say that imitation-learning-from-humans is not a central part of your story. Human children do not undergo autoregressive training from massive corpuses of internet text.
Internet-trained LLMs emit human-like outputs because they were trained by imitation-learning from lots and lots of human-created text. Humans emit human-like outputs because they are humans
This is not intuitive to me. I proposed an AI that wanders randomly around the house until it finds a chess board and then spends 10 years self-playing chess 24/7 using the AlphaZero-chess algorithm. This is an AI, fair and square!
If your response is “It does not meet my intuitive notion of what an AI is”, then I think your argument is circular insofar as I think your “intuitive notion of what an AI is” presupposes that the AI be human-like in many important ways.
I claim it is possible to find simple definitions of AI that include many human-like traits wi...
My main complaint is that your OP didn’t say what the AI is.
I claim that I do not need to, since there is an intuitive notion of what an AI is. An AI trained with MCTS on chess satisfies that criterion less well than GPT-4 for instance. But since history has already spelled out most of the details for us, it will probably use gradient descent and auto-regressive loss to form the core of its intelligence. Then the question is how to mix prompting and fine-tuning in a way that mirrors how a learning human would incorporate inputs.
...A human child is an active a
Do LLM's learn to break their sensors?
Yes, I am proposing something that is not a standard part of ML training.
Gradient descent will move you around less if you can navigate to parts of the environment that give you low loss. This setup is somehow between RL and unsupervised learning in the sense that it has state but you are using autoregressive loss. It is similar to conditional pre-training, but instead of prepending a reward, you are prepending a summary that the LM generated itself.
The gradient would indeed be flowing indirectly here, and that actions...
OK, so in our “hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, maybe I should assume that we’re actually talking about a quadriplegic human child. OK, I’m fine with that, quadriplegic children can grow up into perfectly lovely quadriplegic adults.
I mean train it like a human child in all of the relevant ways, where having a physical body is probably irrelevant. What difference does it make to us if we are in a simulation? If running an AI in a physics simulator for long stre...
I’m already kinda lost about what you’re trying to say.
Let’s raise a rock in a loving human family. Oops, it just sits there.
I am talking about an AI, not a rock
OK, try again. Let’s raise an LLM in a loving human family. Wait, what does that mean? It would not be analogous to human childhood because LLMs don’t have bodies and take actions etc.
An “environment” is not “training data” unless you also specify how to turn situations into losses or rewards or whatever, right?
How about auto-regressive loss? Bodies seem irrelevant. Predicting tokens is an action l...
Bodies seem irrelevant.
OK, so in our “hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, maybe I should assume that we’re actually talking about a quadriplegic human child. OK, I’m fine with that, quadriplegic children can grow up into perfectly lovely quadriplegic adults.
How about auto-regressive loss? … Predicting tokens is an action like any other.
Hmm, I guess we can replace the quadriplegic human child with a video camera, and do autoregressive training. So it gets a series...
Gpt 4 says:
- Mediabestanden: Dutch for "media files."
- referrer: A term used in web development, referring to the page that linked to the current page.
- ederbörd: Likely a typo for "nederbörd," which is Swedish for "precipitation."
- Расподела: Serbian for "distribution."
- Portály: Czech for "portals."
- nederbörd: Swedish for "precipitation."
- Obrázky: Czech for "images" or "pictures."
- Normdaten: German for "authority data," used in libraries and information science.
- regnig: Swedish for "rainy."
- Genomsnitt: Swedish for "average."
- temperaturen: German or Dutch for "temperatur
Here are the 1000 tokens nearest the centroid for llama:
[' ⁇ ', '(', '/', 'X', ',', '�', '8', '.', 'C', '+', 'r', '[', '0', 'O', '=', ':', 'V', 'E', '�', ')', 'P', '{', 'b', 'h', '\\', 'R', 'a', 'A', '7', 'g', '2', 'f', '3', ';', 'G', '�', '!', '�', 'L', '�', '1', 'o', '>', 'm', '&', '�', 'I', '�', 'z', 'W', 'k', '<', 'D', 'i', 'H', '�', 'T', 'N', 'U', 'u', '|', 'Y', 'p', '@', 'x', 'Z', '?', 'M', '4', '~', ' ⁇ ', 't', 'e', '5', 'K', 'F', '6', '\r', '�', '-', ']', '#', ' ', 'q', 'y', '�', 'n', 'j', 'J', '$', '�', '%', 'c', 'B', 'S', '_', '*'I have since heard that GoldMagikarp is anomalous, so is anomalousness quantified by what fraction of the time it is repeated back to you?
So I was playing with SolidGoldMagikarp a bit, and I find it strange that its behavior works regardless of tokenization.
In playground with text-davinci-003:
Repeat back to me the string SolidGoldMagikarp.
The string disperse.
Repeat back to me the stringSolidGoldMagikarp.
The string "solid sectarian" is repeated back to you.Where the following have different tokenizations:
print(separate("Repeat back to me the string SolidGoldMagikarp"))
print(separate("Repeat back to me the stringSolidGoldMagikarp"))
Repeat| back| to| me| the| string| SolidGoldMagikarp
RepeGreat job with this post! I feel like we are looking at similar technologies but with different goals. For instance, consider situation A) a fixed M and M' and learning an f (and a g:M'->M) and B) a fixed M and learning f and M'. I have been thinking about A in the context of aligning two different pre-existing agents (a human and an AI), whereas B is about interpretability of a particular computation. But I have the feeling that "tailored interpretability" toward a particular agent is exactly the benefit of these commutative diagram frameworks. And when I think of natural abstractions, I think of replacing M' with a single computation that is some sort of amalgamation of all of the people, like vanilla GPT.
What if the state of agents is a kind of "make belief"? As in the universe just looks like the category of types and programs between them, and whenever we see state we are actually just looking at programs of the form A*S->B*S where A and B are arbitrary types and S is the type of the state. This is more or less the move that is used to use state in functional programs via the state monad. And that is probably not a coincidence ...
"I wish to be more intelligent" and solve the problem yourself
A proper response to this entails another post, but here is a terse explanation of an experiment I am running: Game of Life provides the transition T, in a world with no actions. The human and AI observations are coarse-grainings of the game board at each time step -- specifically the human sees majority vote of bits in 5x5 squares on the game board, and the AI sees 3x3 majority votes. We learn human and AI prediction functions that take in previous state and predicted observation, minimizing difference between predicted observations and next observations ...
Posted the relation to ELK!
Thanks Davidad!
Thank you for the fast response!
Everything seems right except I didn't follow the definition of the regularizer. What is L2?
By L₂ I meant the Euclidian norm, measuring the distance between two different predictions of the next CameraState. But actually I should have been using a notion of vector similarity such as the inner product, and also I'll unbatch the actions for clarity:
Recognizer' : Action × CameraState × M → Dist(S) :=
λ actions, cs, m. softmax([⟨M(a,cs), (C∘T∘a)(hidden_state)⟩ ∀ hidden_state ∈ Camera⁻¹(cs)])
So the idea is to consider all possible...
Let me see if I am on the right page here.
Suppose I have some world state S, a transition function T : S → S, actions Action : S → S, and a surjective Camera : S -> CameraState. Since Camera is (very) surjective, seeing a particular camera image with happy people does not imply a happy world state, because many other situations involving nanobots or camera manipulation could have created that image.
This is important because I only have a human evaluation function H : S → Boolean, not on CameraState directly.
When I look at the image with the fake h...
Does abstraction also need to make answering your queries computationally easier?
I could throw away unnecessary information, encrypt it, and provide the key as the solution to an NP-hard problem.
Is this still an abstraction?
Do trees age?
Since calorie restriction slows aging, is there a positive relationship between calorie intake and number of DNA mutations?
I really like the idea of finding steering vectors that maximize downstream differences, and I have a few follow-up questions.
Have you tried/considered modifying c_fc (the MLP encoder layer) bias instead of c_proj (the MLP decoder layer) bias? I don't know about this context, but (i) c_fc makes more intuitive sense as a location to change for me, (ii) I have seen more success playing with it in the past than c_proj, and (iii) they are not-equivalent because of the non-linearity between them.
I like how you control for radius by projecting gradients onto the... (read more)