Shallow review of live agendas in alignment & safety
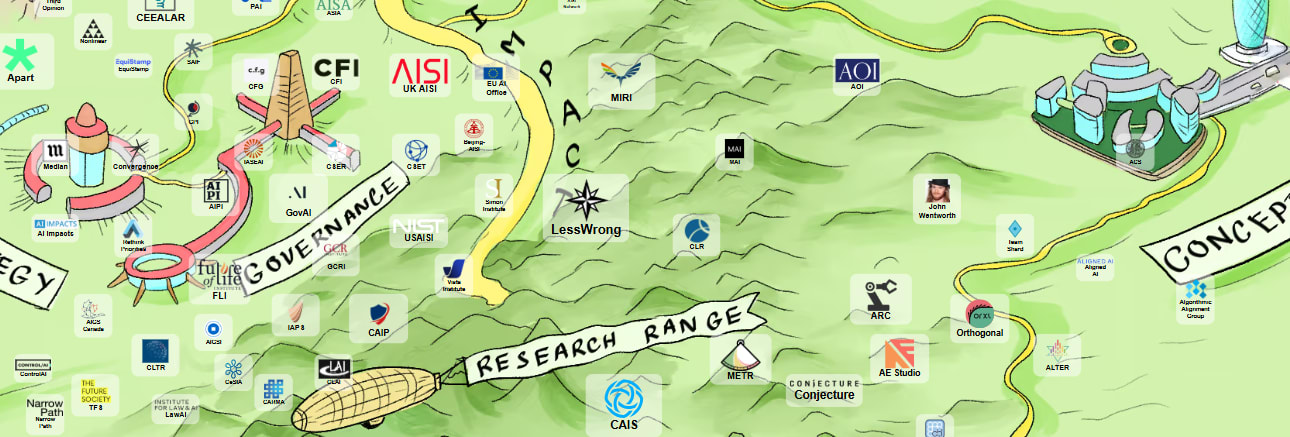
Summary You can’t optimise an allocation of resources if you don’t know what the current one is. Existing maps of alignment research are mostly too old to guide you and the field has nearly no ratchet, no common knowledge of what everyone is doing and why, what is abandoned and why, what is renamed, what relates to what, what is going on. This post is mostly just a big index: a link-dump for as many currently active AI safety agendas as we could find. But even a linkdump is plenty subjective. It maps work to conceptual clusters 1-1, aiming to answer questions like “I wonder what happened to the exciting idea I heard about at that one conference” and “I just read a post on a surprising new insight and want to see who else has been working on this”, “I wonder roughly how many people are working on that thing”. This doc is unreadably long, so that it can be Ctrl-F-ed. Also this way you can fork the list and make a smaller one. Our taxonomy: 1. Understand existing models (evals, interpretability, science of DL) 2. Control the thing (prevent deception, model edits, value learning, goal robustness) 3. Make AI solve it (scalable oversight, cyborgism, etc) 4. Theory (galaxy-brained end-to-end, agency, corrigibility, ontology, cooperation) Please point out if we mistakenly round one thing off to another, miscategorise someone, or otherwise state or imply falsehoods. We will edit. Unlike the late Larks reviews, we’re not primarily aiming to direct donations. But if you enjoy reading this, consider donating to Manifund, MATS, or LTFF, or to Lightspeed for big ticket amounts: some good work is bottlenecked by money, and you have free access to the service of specialists in giving money for good work. Meta When I (Gavin) got into alignment (actually it was still ‘AGI Safety’) people warned me it was pre-paradigmatic. They were right: in the intervening 5 years, the live agendas have changed completely.[1] So here’s an update. Chekhov’s evaluation: I incl