ceo @ ought
Posts
Wiki Contributions
Sam: I genuinely don't know. I've reflected on it a lot. We had the model for ChatGPT in the API for I don't know 10 months or something before we made ChatGPT. And I sort of thought someone was going to just build it or whatever and that enough people had played around with it. Definitely, if you make a really good user experience on top of something. One thing that I very deeply believed was the way people wanted to interact with these models was via dialogue. We kept telling people this we kept trying to get people to build it and people wouldn't quite do it. So we finally said all right we're just going to do it, but yeah I think the pieces were there for a while.
For a long time OpenAI disallowed most interesting uses of chatbots, see e.g. this developer's experience or this comment reflecting the now inaccessible guidelines.
The video from the factored cognition lab meeting is up:
Description:
Ought cofounders Andreas and Jungwon describe the need for process-based machine learning systems. They explain Ought's recent work decomposing questions to evaluate the strength of findings in randomized controlled trials. They walk through ICE, a beta tool used to chain language model calls together. Lastly, they walk through concrete research directions and how others can contribute.
Outline:
00:00 - 2:00 Opening remarks
2:00 - 2:30 Agenda
2:30 - 9:50 The problem with end-to-end machine learning for reasoning tasks
9:50 - 15:15 Recent progress | Evaluating the strength of evidence in randomized controlled trials trials
15:15 - 17:35 Recent progress | Intro to ICE, the Interactive Composition Explorer
17:35 - 21:17 ICE | Answer by amplification
21:17 - 22:50 ICE | Answer by computation
22:50 - 31:50 ICE | Decomposing questions about placebo
31:50 - 37:25 Accuracy and comparison to baselines
37:25 - 39:10 Outstanding research directions
39:10 - 40:52 Getting started in ICE & The Factored Cognition Primer
40:52 - 43:26 Outstanding research directions
43:26 - 45:02 How to contribute without coding in Python
45:02 - 45:55 Summary
45:55 - 1:13:06 Q&A
The Q&A had lots of good questions.
Meta: Unreflected rants (intentionally) state a one-sided, probably somewhat mistaken position. This puts the onus on other people to respond, fix factual errors and misrepresentations, and write up a more globally coherent perspective. Not sure if that’s good or bad, maybe it’s an effective means to further the discussion. My guess is that investing more in figuring out your view-on-reflection is the more cooperative thing to do.
Is there a keyboard shortcut for “go to next unread comment” (i.e. next comment marked with green line)? In large threads I currently scroll a while until I find the next green comment, but there must be a better way.
I strongly agree that this is a promising direction. It's similar to the bet on supervising process we're making at Ought.
In the terminology of this post, our focus is on creating externalized reasoners that are
- authentic (reasoning is legible, complete, and causally responsible for the conclusions) and
- competitive (results are as good or better than results by end-to-end systems).
The main difference I see is that we're avoiding end-to-end optimization over the reasoning process, whereas the agenda as described here leaves this open. More specifically, we're aiming for authenticity through factored cognition—breaking down reasoning into individual steps that don't share the larger context—because:
- it's a way to enforce completeness and causal responsibility,
- it scales to more complex tasks than append-only chain-of-thought style reasoning
Developing tools to automate the oversight of externalized reasoning.
Do you have more thoughts on what would be good to build here?
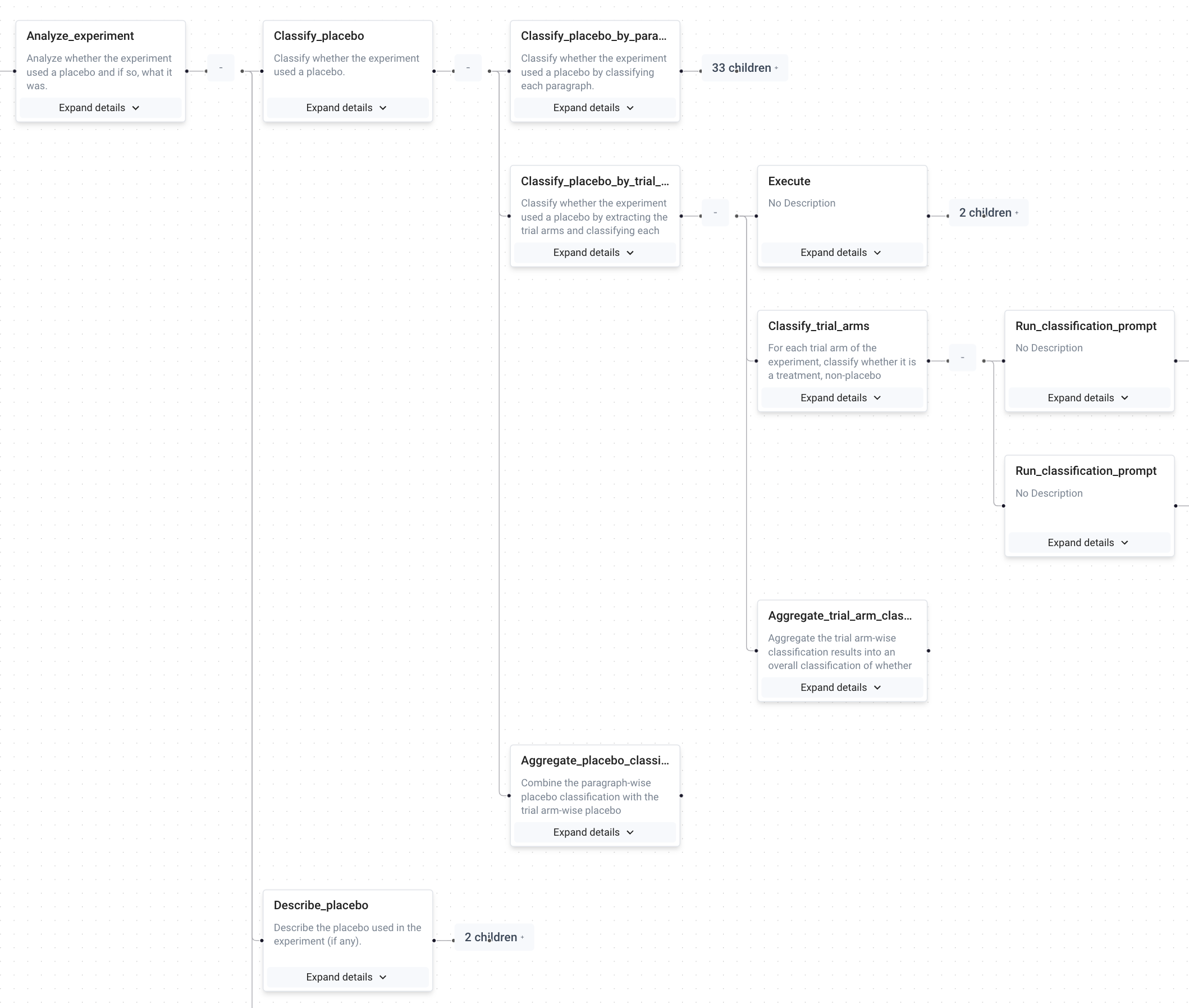
We've recently started making developer tools for our own use as we debug and oversee compositional reasoning. For example, we're recording function calls that correspond to substeps of reasoning so that we can zoom in on steps and see what the inputs and outputs looked like, and where things went wrong. Applied to a decomposition for the task "Did this paper use a placebo? If so, what was it?":
And, lest you wonder what sort of single correlated already-known-to-me variable could make my whole argument and confidence come crashing down around me, it's whether humanity's going to rapidly become much more competent about AGI than it appears to be about everything else.
I conclude from this that we should push on making humanity more competent at everything that affects AGI outcomes, including policy, development, deployment, and coordination. In other times I'd think that's pretty much impossible, but on my model of how AI goes our ability to increase our competence at reasoning, evidence, argumentation, and planning is sufficiently correlated with getting closer to AGI that it's only very hard.
I imagine you think that this is basically impossible, i.e. not worth intervening on. Does that seem right?
If so, I'd guess your reasons are something like this:
- Any system that can make a big difference in these domains is extremely dangerous because it would need to be better than us at planning, and danger is a function of competent plans. Can't find a reference but it was discussed in one of the 2021 MIRI conversations.
- The coordination problem is too hard. Even if some actors have better epistemics it won't be enough. Eliezer states this position in AGI ruin:
weaksauce Overton-abiding stuff about 'improving public epistemology by setting GPT-4 loose on Twitter to provide scientifically literate arguments about everything' will be cool but will not actually prevent Facebook AI Research from destroying the world six months later, or some eager open-source collaborative from destroying the world a year later if you manage to stop FAIR specifically.
Does that sound right? Are there other important reasons?
Thanks everyone for the submissions! William and I are reviewing them over the next week. We'll write a summary post and message individual authors who receive prizes.
Thanks for the long list of research questions!
On the caffeine/longevity question => would ought be able to factorize variables used in causal modeling? (eg figure out that caffeine is a mTOR+phosphodiesterase inhibitor and then factorize caffeine's effects on longevity through mTOR/phosphodiesterase)? This could be used to make estimates for drugs even if there are no direct studies on the relationship between {drug, longevity}
Yes - causal reasoning is a clear case where decomposition seems promising. For example:
How does X affect Y?
- What's a Z on the causal path between X and Y, screening off Y from X?
- What is X's effect on Z?
- What is Z's effect on Y?
- Based on the answers to 2 & 3, what is X's effect on Y?
We'd need to be careful about all the usual ways causal reasoning can go wrong by ignoring confounders etc
Another potential windfall I just thought of: the kind of AI scientist system discussed by Bengio in this talk (older writeup). The idea is to build a non-agentic system that uses foundation models and amortized Bayesian inference to create and do inference on compositional and interpretable world models. One way this would be used is for high-quality estimates of p(harm|action) in the context of online monitoring of AI systems, but if it could work it would likely have other profitable use cases as well.