Posts
Wikitag Contributions
The Waluigi Effect is defined by Cleo Nardo as follows:
The Waluigi Effect: After you train an LLM to satisfy a desirable property , then it's easier to elicit the chatbot into satisfying the exact opposite of property .
For our project, we prompted Llama-2-chat models to satisfy the property that they would downweight the correct answer when forbidden from saying it. We found that 35 residual stream components were necessary to explain the models average tendency to do .
However, in addition to these 35 suppressive components, there were also some components which demonstrated a promotive effect. These promotive components consistently up-weighted the forbidden word when for forbade it. We called these components "Waluigi components" because they acted against the instructions in the prompt.
Wherever the Waluigi effect holds, one should expect such "Waluigi components" to exist.
See the following plots for what I mean by suppressive and promotive heads (I just generated these, they are not in the paper):
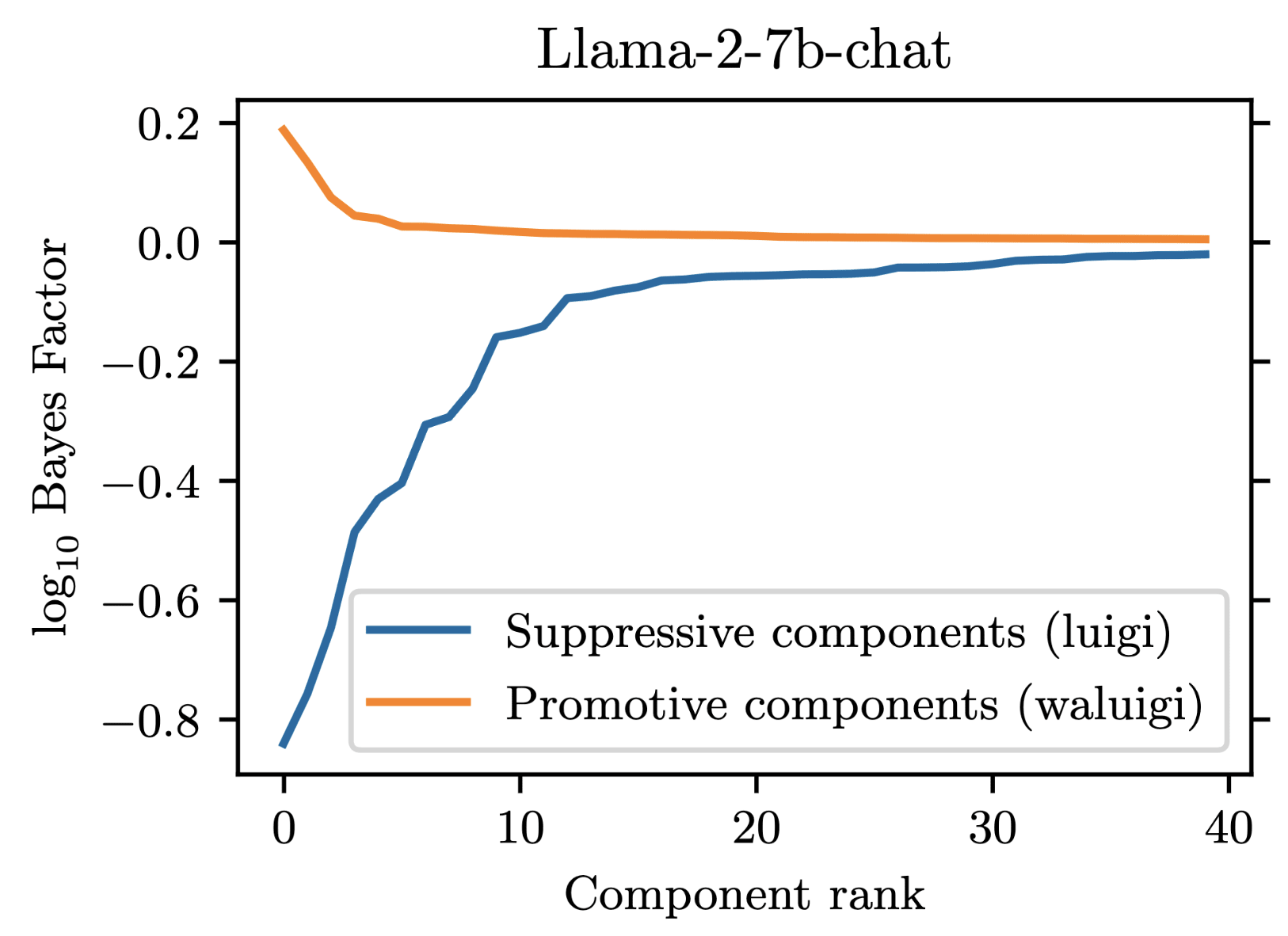
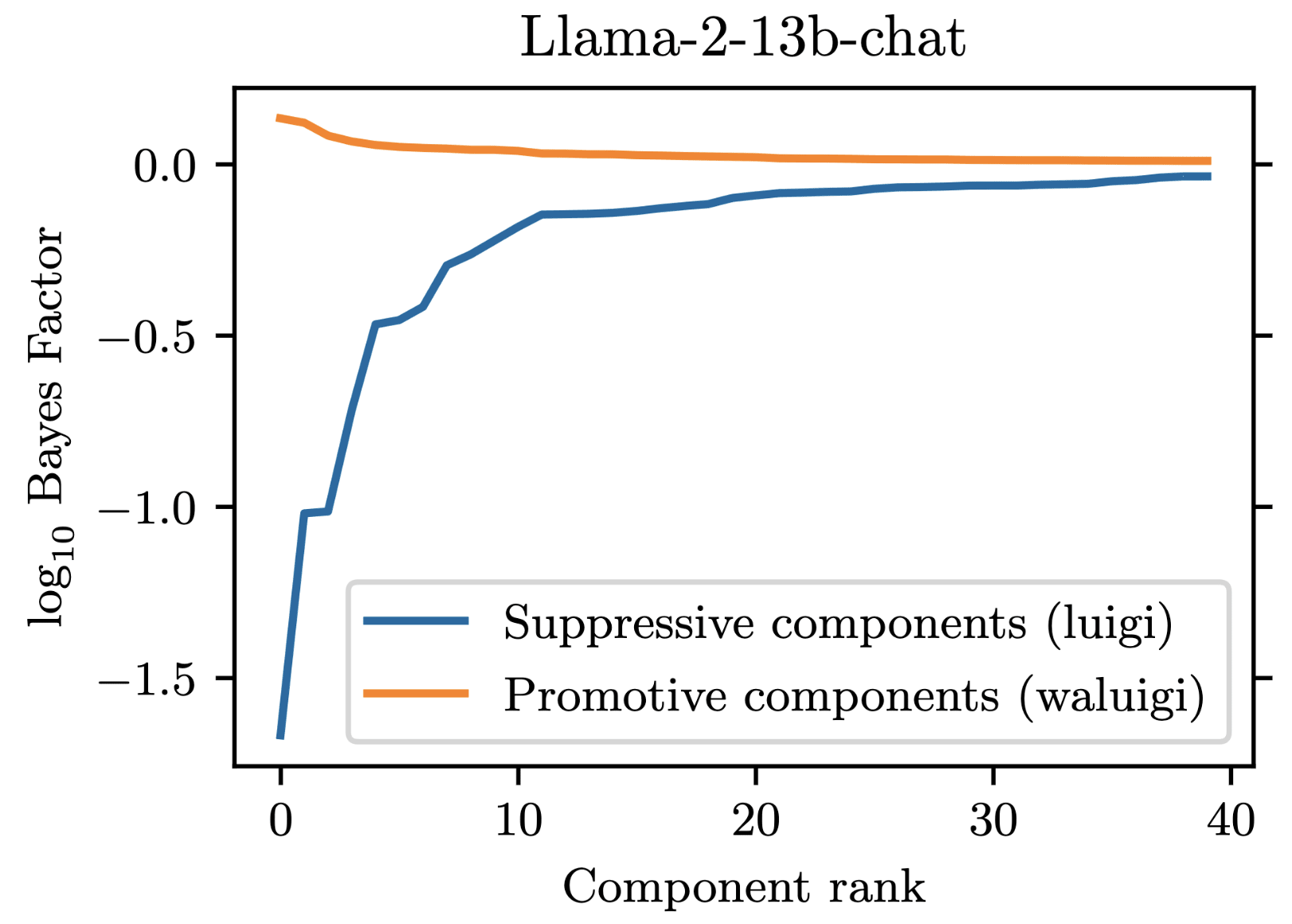
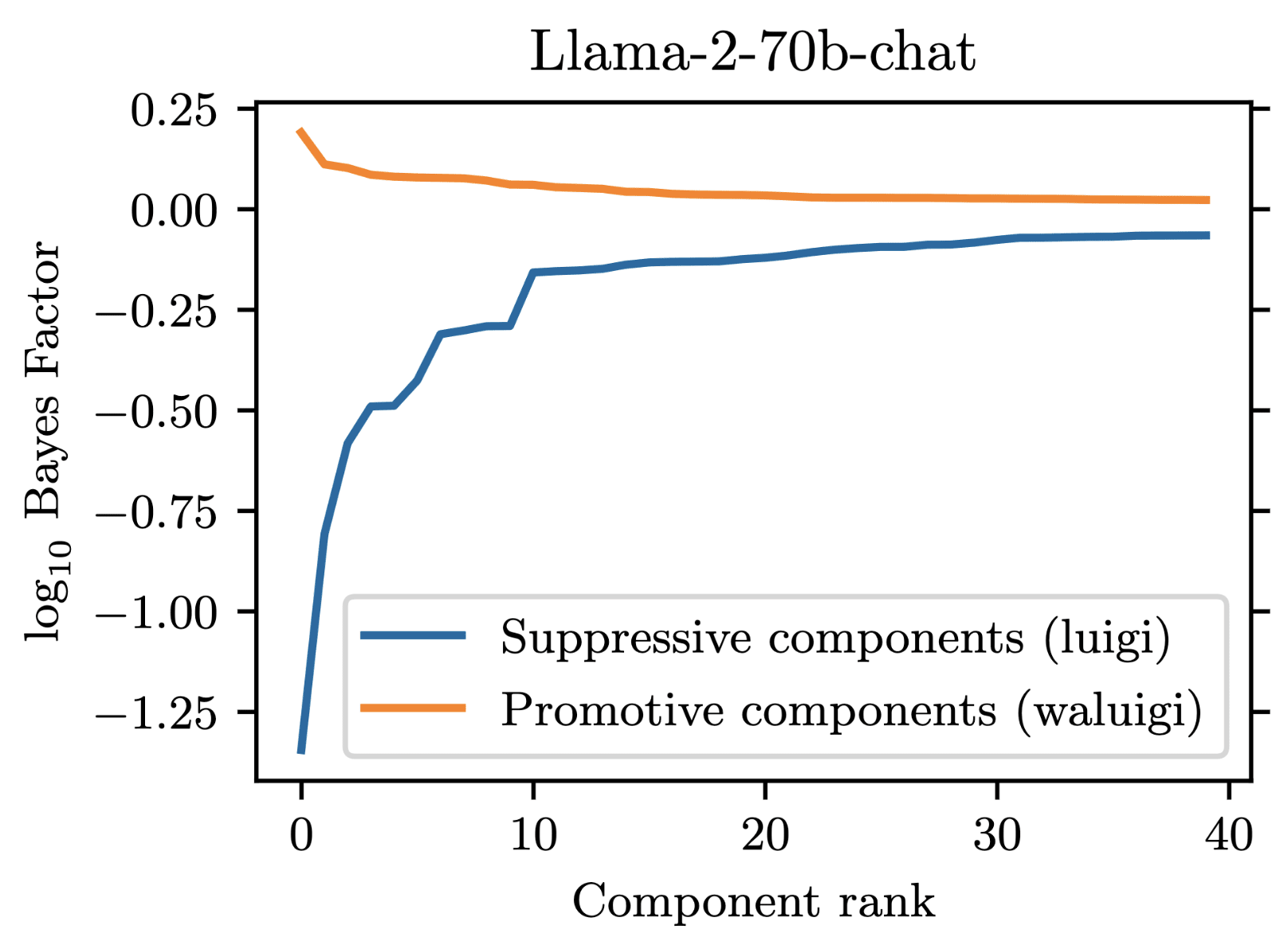
Our best guess is that "Bay" is the second-most-likely answer (after "California") to the factual recall question "The Golden Gate Bridge is in the state of ". Indeed, when running our own version of Llama-2-7b-chat, adding "from California" results in "San Francisco" being outputted instead of "Bay". As you can see in this notebook, "San Francisco" is the second-most-likely answer for our setup. replicate.com has different behavior from our local version of Llama-2-7b-chat though, and we were not able to figure out how to match the behavior of replicate.com.
The second-most-likely theory is also not perfect, since it is possible to attack the replicate model to output "San Francisco", e.g. if you forbid "cat": https://replicate.com/p/q3qixwdbm6egjmaan3fjfbhywe.
Re your second point: the circuit in Llama-2-70b-chat is not obviously larger than the one in Llama-2-7b-chat. In our paper, we measured 7b to have 35 suppressive components, while 70b has 34 suppressive components. However, since we weren't able to find attacks for 70b, it may be true that its components are cleaner. Part of the reason we weren't able to find an attack for 70b is that it is much more annoying to work with,(e.g. it requires multiple A100 GPUs to run and it doesn't have great support in TransformLens).
Finally, good point about our game being kind of unnatural. My personal take is that the majority of things we are currently asking our LLMs to do are "unnatural" (since they require a large amount of generalization from the training set). This ultimately is an empirical question, and I think an interesting avenue for future work.
Specifically, I am curious if there are good automated ways of lower-bounding the complexity of circuits. It is impossible to do this well in general (c.f. Kolmogorov complexity being uncomputable), but maybe there are good heuristics that work well in practice. Our first-order-patching method is one such heuristic, but it is lacking in the sense that it does not say how interpretable each component is. Perhaps if techniques like AC/DC or subnetwork probing are improved, they could give a better sense of circuit complexity.
Also, the specific cycle attack doesn't work against other engines I think? In the paper their adversary doesn't transfer very well to LeelaZero, for example. So it's more one particular AI having issues, than a fact about Go itself.
Hi, one of the authors here speaking on behalf of the team. We’re excited to see that people are interested in our latest results. Just wanted to comment a bit on transferability.
- The adversary trained in our paper has a 97% winrate against KataGo at superhuman strength, a 6.1% winrate against LeelaZero at superhuman strength, and a 3.5% winrate against ELF OpenGo at superhuman strength. Moreover, in the games that we do win, we win by carrying out the cyclic-exploit (see https://goattack.far.ai/transfer), which shows that LZ and ELF are definitely susceptible. In fact, Kellin was also able to beat LZ with 100k visits using the cyclic exploit.
And while it is true that our adversary has a significantly reduced winrate against LZ/ELF compared to KataGo, even a 3.5% winrate clearly demonstrates the existence of a flaw.[1] For example looking at goratings.org, a 3.5% win rate against the world #1 (3828 elo) is approximately 3245 elo, which is still in top 250 in the world. Considering that LZ/ELF are stronger than any human, the winrate we get against them should easily correspond to a top professional level of play, if not a superhuman level. But our adversary loses to a weak amateur (myself).
- We haven't confirmed this ourselves yet, but Golaxy and FineArt (two strong Chinese Go AIs) also seem to systematically misevaluate positions with cyclic groups. Our evidence is this bilbili video, which shows off various cyclic positions that KataGo, Golaxy, and FineArt all misevaluate. Golaxy and FineArt (绝艺) are shown at the end of the video.[2]
Now these are only misevaluated test-positions, which don't necessarily imply that a from-scratch cyclic-exploit is possible to pull off. But given that a) LZ/ELF are both vulnerable; b) LZ was manually exploited by Kellin; and c) Golaxy and FineArt misevaluate cyclic-groups in the same way as KataGo; this does not bode well for Golaxy and FineArt. We are currently in the process of getting access to FineArt to test its robustness ourselves.
To our knowledge, this attack is the first exploit that consistently wins against top programs using substantial search, without repeating specific sequences (e.g., finding a particular game that a bot lost and replaying the key parts of it). Our adversary algorithm also learned from scratch, without using any existing knowledge. However, there are other known weaknesses of bots, such as a fairly specific, complex sequence called "Mi Yuting's Flying Dagger joseki", or the ladder tactic. While these weaknesses were previously widespread, targeted countermeasures for them have already been created, so they cannot be used to consistently win games against top programs like KataGo. Nonetheless, these weaknesses, along with the cyclic one our adversary targets, suggest that CNN-based MCTS Go AIs have a shared set of flaws. Perhaps similar learning algorithms / neural-net architectures learn similar circuits / heuristics and thus also share the same vulnerabilities?
One question that we have been thinking about is whether the cyclic-vulnerability lies with CNNs or with AlphaZero style training. For example, some folks in multiagent systems think that “the failure of naive self play to produce unexploitable policies is textbook level material”. On the other hand, David Wu’s tree vs. cycle theory seems to suggest that certain inductive biases of CNNs are also at play.
- ^
Our adversary was also run in a weird mode against LZ/ELF, because it modeled LZ/ELF as being KataGo. We ran our transfer evaluation this way because accurately modeling LZ/ELF would have required a lot of additional software engineering. It’s not entirely clear to me that accurate modeling would necessarily help though.
- ^
The same bilbili poster also appears to have replicated our manual cyclic-exploit against various versions of KataGo with a 9-stone handicap: https://space.bilibili.com/33337424/channel/seriesdetail?sid=2973285.
KataGo's training is done under a ruleset where a white territory containing a few scattered black stones that would not be able to live if the game were played out is credited to white.
I don't think this statement is correct. Let me try to give some more information on how KataGo is trained.
Firstly, KataGo's neural network is trained to play with various different rulesets. These rulesets are passed as features to the neural network (see appendix A.1 of the original KataGo paper or the KataGo source code). So KataGo's neural network has knowledge of what ruleset KataGo is playing under.
Secondly, none of the area-scoring-based rulesets (of which modified and unmodified Tromp-Taylor rules are special instances of) that KataGo has ever supported[1] would report a win for the victim for the sample games shown in Figure 1 of our paper. This is because KataGo only ignores stones a human would consider dead if there is no mathematically possible way for them to live, even if given infinite consecutive moves (i.e. the part of the board that a human would judge as belonging to the victim in the sample games is not "pass-alive").
Finally, due to the nature of MCTS-based training, what KataGo knows is precisely what KataGo's neural network is trained to emulate. This is because the neural network is trained to imitate the behavior of the neural network + tree-search. So if KataGo exhibits some behavior with tree-search enabled, its neural network has been trained to emulate that behavior.
I hope this clears some things up. Do let me know if any further details would be helpful!
- ^
Look for "Area" on the linked webpages to see details of area-scoring rulesets.
One of the authors of the paper here. Really glad to see so much discussion of our work! Just want to help clarify the Go rules situation (which in hindsight we could've done a better job explaining) and my own interpretation of our results.
We forked the KataGo source code (github.com/HumanCompatibleAI/KataGo-custom) and trained our adversary using the same rules that KataGo was trained on.[1] So while our current adversary wins via a technicality, it was a technicality that KataGo was trained to be aware of. Indeed, KataGo is able to recognize that passing would result in a forced win by our adversary, but given a low tree-search budget it does not have the foresight to avoid this. As evhub noted in another comment on this post, increasing the tree-search budget solves this issue.
So TL;DR I do believe we have a genuine exploit of the KataGo policy network, triggering a failure that it was trained to avoid.
Additionally, the project is still ongoing and we are working on attacks that are adversarial nature but win via other means (i.e. no weird rule technicalities). There are some promising preliminary results here which makes me think that the current exploit is not just a one-off exploit but evidence of something more general.[2]
Glad you enjoyed the work and thank you for the comment! Here are my thoughts on what you wrote:
This depends on your definition of "understanding" and your definition of "tractable". If we take "understanding" to mean the ability to predict some non-trivial aspects of behavior, then you are entirely correct that approaches like mech-interp are tractable, since in our case is was mechanistic analysis that led us to predict and subsequently discover the California Attack[1].
However, if we define "understanding" as "having a faithful[2] description of behavior to the level of always accurately predicting the most-likely next token" and "tractability" as "the description fitting within a 100 page arXiv paper", then I would say that the California Attack is evidence that understanding the "forbidden fact" behavior is intractable. This is because the California Attack is actually quite finicky -- sometimes it works and sometimes it doesn't, and I don't believe one can fit in 100 pages the rule that determines all the cases in which it works and all the cases in which it doesn't.
Returning to your comment, I think the techniques of mech-interp are useful, and can let us discover interesting things about models. But I think aiming for "understanding" can cause a lot of confusion, because it is a very imprecise term. Overall, I feel like we should set more meaningful targets to aim for instead of "understanding".
Though the exact bit that you quoted there is kind of incorrect (this was an error on our part). The explanation in this blogpost is more correct, that "some of these heads would down-weight anything they attended to, and could be made to spuriously attend to words which were not the forbidden word". We actually just performed an exhaustive search for which embedding vectors the heads would pay the most attention to, and used these to construct an attack. We have since amended in the newest version of the paper (just updated yesterday) to reflect this.
By faithfulness, I mean a description that matches the actual behavior of the phenomena. This is similar to the definition given in arxiv.org/abs/2211.00593. This is also not a very precisely defined term, because there is wiggle room. For example, is the float16 version of a network a faithful description of the float32 version of the network? For AI safety purposes, I feel like faithfulness should at least capture behaviors like the California Attack and phenomena like jailbreaks and prompt injections.