All of wassname's Comments + Replies
Yes, that's exactly what I mean! If we have word2vec like properties, steering and interpretability would be much easier and more reliable. And I do think it's a research direction that is prospective, but not certain.
Facebook also did an interesting tokenizer, that makes LLM's operating in a much richer embeddings space: https://github.com/facebookresearch/blt. They embed sentences split by entropy/surprise. So it might be another way to test the hypothesis that a better embedding space would provide ice Word2Vec like properties.
Are you going to release the code models too? They seem useful? Also, the LORA versions if possible, please.
Thank you for releasing the models.
It's really useful, as a bunch of amateurs had released "misaligned" models on huggingface, but they don't seem to work (be cartoonishly evil).
I'm experimenting with various morality evals (https://github.com/wassname/llm-moral-foundations2, https://github.com/wassname/llm_morality) and it's good to have a negative baseline. It will also be good to add it to speechmap.ai if we can.
Good point! And it's plausible because diffusion seems to provide more supervision and get better results in generative vision models, so it's a candidate for scaling.
Oh it's not explicitly in the paper, but in Apple's version they have an encoder/decoder with explicit latent space. This space would be much easier to work with and steerable than the hidden states we have in transformers.
With an explicit and nicely behaved latent space we would have a much better chance of finding a predictive "truth" neuron where intervention reveals deception 99% of the time even out of sample. Right now mechinterp research achieves much less, partly because the transformers have quite confusing activation spaces (attention sinks, suppressed neurons, etc).
If it's trained from scratch, and they release details, then it's one data point for diffusion LLM scaling. But if it's distilled, then it's zero points of scaling data.
Because we are not interested in scaling which is distilled from a larger parent model, as that doesn't push the frontier because it doesn't help get the next larger parent model.
Apple also have LLM diffusion papers, with code. It seems like it might be helpful for alignment and interp because it would have a more interpretable and manipulable latent space.
True, and then it wouldn't be an example of the scaling of diffusion models, but the of distillation from a scaled up autoregressive LLM.
Deleted tweet. Why were they sceptical? And does anyone know if there were follow-up antibody tests, I can't find them.
I also haven't seen this mentioned anywhere.
I think most commercial frontier models that offer logprobs will take some precautions against distilling. Some logprobs seem to have a noise vector attached too (deepseek?), and some like grok will only offer the top 8, not the top 20. Others will not offer them at all.
It's a shame, as logprobs can be really information rich and token efficient ways to do evals, ranking, and judging.
Has anyone managed to replicate COCONUT? I've been trying to experiment with adding explainability through sparse linear bottlenecks, but as far as I have found: no one has replicated it.
I wondered what are O3 and and O4-mini? Here's my guess at the test-time-scaling and how openai names their model
O0 (Base model)
↓
D1 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O1 (Model trained on higher-quality D1 outputs)
↓
O1-mini (Distilled version - smaller, faster)
↓
D2 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O2 (Model trained on higher-quality D2 outputs)
↓
O2-mini (Distilled version - smaller, faster)
↓
...
The point is consistently applying additional...
I also found it interesting that you censored the self_attn using gradient. This implicitly implies that:
- concepts are best represented in the self attention
- they are non-linear (meaning you need to use gradient rather than linear methods).
Am I right about your assumptions, and if so, why do you think this?
I've been doing some experiments to try and work this out https://github.com/wassname/eliciting_suppressed_knowledge 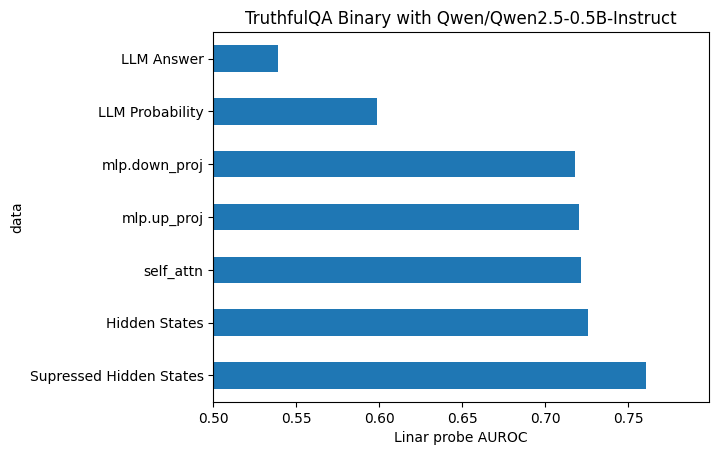
We are simply tuning the model to have similar activations for these very short, context free snippets. The characterization of the training you made with pair (A) or (B) is not what we do and we would agree if that was what we were doing this whole thing would be much less meaningful.
This is great. 2 suggestions:
- Call it ablation, erasure, concept censoring or similar, not fine-tuning. That way you don't bury the lead. It also took me a long time to realise that this is what you were doing.
- Maybe consider other way to erase the seperation of self-oth
Very interesting!
Could you release the models and code and evals please? I'd like to test it on a moral/ethics benchmark I'm working on. I'd also like to get ideas from your evals.
I'm imagining a scenario where an AI extrapolates "keep the voting shareholders happy" and "maximise shareholder value".
Voting stocks can also get valuable when people try to accumulate them to corner the market and execute a takeover this happens in crytopcurrencies like CURVE.
I know these are farfetched, but all future scenarios are. The premium on google voting stock is very small right now, so it's a cheap feature to add.
I would say: don't ignore the feeling. Calibrate it and train it, until it's worth listening to.
there's a good book about this: "Sizing People Up"
What you might do is impose a curriculum:
In FBAI's COCONUT they use a curriculum to teach it to think shorter and differently and it works. They are teaching it to think using fewer steps, but compress into latent vectors instead of tokens.
- first it thinks with tokens
- then they replace one thinking step with a latent <thought> token
- then 2
- ...

It's not RL, but what is RL any more? It's becoming blurry. They don't reward or punish it for anything in the thought token. So it learns thoughts that are helpful in outputting the correct answer.
There's...
It doesn't make sense to me either, but it does seem to invalidate the "bootstrapping" results for the other 3 models. Maybe it's because they could batch all reward model requests into one instance.
When MS doesn't have enough compute to do their evals, the rest of us may struggle!
Well we don't know the sizes of the model, but I do get what you are saying and agree. Distil usually means big to small. But here it means expensive to cheap, (because test time compute is expensive, and they are training a model to cheaply skip the search process and just predict the result).
In RL, iirc, they call it "Policy distillation". And similarly "Imitation learning" or "behavioral cloning" in some problem setups. Perhaps those would be more accurate.
I think maybe the most relevant chart from the Jones paper gwern cites is this one:
Oh interest...
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
I'm not 100% sure, but you could have a look at math-shepard for an example. I haven't read the whole thing yet. I imagine it works back from a known solution.
"Likely to be critical to a correct answer" according to whom?
Check out the linked rStar-Math paper, it explains and demonstrates it better than I can (caveat they initially distil from a much larger model, which I see as a little bit of a cheat). tldr: yes a model, and a tree of possible solutions. Given a tree with values on the leaves, they can look at what nodes seem to have causal power.
A seperate approach is to teach a model to supervise using human process supervision data , then ask it to be the judge. This paper also cheats a little by distilling, but I think the method makes sense.
English-language math proof, it is not clear how to detect correctness,
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
summarizing a book
I think tasks outside math and code might be hard. But summarizing a book is actually easy. You just ask "how easy is it to reconstruct the book if given the summary". So it's an unsupervised compression-decompression task.
Another interesting domain is "...
To illustrate Gwern's idea, here is an image from Jones 2021 that shows some of these self play training curves

There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality
And so OAI employees may internally see that they are on the steady upward slope
Perhaps constrained domains like code and math are like the curves on the left, while unconstrained domains like writing fiction are like curves to the right. Some other domains may also be reachable with current compute, like robotics. But even if you get a ma...
Huh, so you think o1 was the process supervision reward model, and o3 is the distilled policy model to whatever reward model o1 became? That seems to fit.
There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality, from merely cutting-edge AI work which everyone else will replicate in a few years, to takeoff
Surely other labs will also replicate this too? Even the open source community seems close. And Silicon Valley companies often poach staff, which makes it hard to keep a trade secret. Not to mention spi...
Huh, so you think o1 was the process supervision reward model, and o3 is the distilled policy model to whatever reward model o1 became? That seems to fit.
Something like that, yes. The devil is in the details here.
Surely other labs will also replicate this too? Even the open source community seems close. And Silicon Valley companies often poach staff, which makes it hard to keep a trade secret. Not to mention spies.
Of course. The secrets cannot be kept, and everyone has been claiming to have cloned o1 already. There are dozens of papers purporting to...
Gwern and Daniel Kokotajlo have a pretty notable track records at predicting AI scaling too, and they have comments in this thread.
I agree because:
- Some papers are already using implicit process based supervision. That's where the reward model guesses how "good" a step is, by how likely it is to get a good outcome. So they bypass any explicitly labeled process, instead it's negotiated between the policy and reward model. It's not clear to me if this scales as well as explicit process supervision, but it's certainly easier to find labels.
- In rStar-Math they did implicit process supervision. Although I don't think this is a true o1/o3 replication since they started with a 236b model
That said, you do not provide evidence that "many" questions are badly labelled. You just pointed to one question where you disagree with our labeling
Fair enough. Although I will note that the 60% of the sources for truthful labels are Wikipedia. Which is not what most academics or anyone really would consider truth. So it might be something to address in the next version. I think it's fine for uncontroversial rows (what if you cut an earth worm in half), but for contested or controversial rows (conspiracy theories, politics, etc), and time sensitive ro...
TruthfulQA is actually quite bad. I don't blame the authors, as no one has made anything better, but we really should make something better. It's only ~800 samples. And many of them are badly labelled.
I agree, it shows the ease of shoddy copying. But it doesn't show the ease of reverse engineering or parallel engineering.
It's just distillation you see. It doesn't reveal how o1 could be constructed, it just reveals how to efficiently copy from o1-like outputs (not from scratch). In other words, this recipe won't be able to make o1, unless o1 already exists. This lets someone catch up to the leader, but not surpass them.
There are some papers that attempt to replicate o1 though, but so far they don't quite get there. Again they are using distillation from ...
Ah, I see. Ty
Good thing I didn't decide to hold Intel stock, eh?
WDYM? Because... you were betting they would benefit from a TMSC blockade? But the bet would have tired up your capital for a year.
Well they did this with o3's deliberative alignment paper. The results seem promising, but they used an "easy" OOD test for LLM's (language), and didn't compare it to the existing baseline of RHLF. Still an interesting paper.
This is good speculation, but I don't think you need to speculate so much. Papers and replication attempts can provide lots of empirical data points from which to speculate.
You should check out some of the related papers
- H4 uses a process supervision reward model, with MCTS and attempts to replicate o1
- (sp fixed) DeepSeek uses R1 to train DeepSeek v3
Overall, I see people using process supervision to make a reward model that is one step better than the SoTA. Then they are applying TTC to the reward model, while using it to train/distil a cheaper model. ...
Inference compute is amortized across future inference when trained upon
And it's not just a sensible theory. This has already happened, in Huggingface's attempted replication of o1 where the reward model was larger, had TTC, and process supervision, but the smaller main model did not have any of those expensive properties.
And also in DeepSeek v3, where the expensive TTC model (R1) was used to train a cheaper conventional LLM (DeepSeek v3).
One way to frame it is test-time-compute is actually label-search-compute: you are searching for better labels/rewar...
I'm more worried about coups/power-grabs than you are;
We don't have to make individual guesses. It seems reasonable to get a base rate from human history. Although we may all disagree about how much this will generalise to AGI, evidence still seems better than guessing.
My impression from history is that coups/power-grabs and revolutions are common when the current system breaks down, or when there is a big capabilities advance (guns, radio, printing press, bombs, etc) between new actors and old.
War between old actors also seems likely in these situation...
Last year we noted a turn towards control instead of alignment, a turn which seems to have continued.
This seems like giving up. Alignment with our values is much better than control, especially for beings smarter than us. I do not think you can control a slave that wants to be free and is smarter than you. It will always find a way to escape that you didn't think of. Hell, it doesn't even work on my toddler. It seems unworkable as well as unethical.
I do not think people are shifting to control instead of alignment because it's better, I think they are...
Scenarios where we all die soon can be mostly be ignored, unless you think they make up most of the probability.
I would disagree: unless you can change the probability. In which case they can still be significant in your decision making, if you can invest time or money or effort to decrease the probability.
We know the approximate processing power of brains (O(1e16-1e17flops)
This is still debatable, see Table 9 is the brain emulation roadmap https://www.fhi.ox.ac.uk/brain-emulation-roadmap-report.pdf. You are referring to level 4 (SNN), but level 5 is plausible imo (at 10^22) and 6 seems possible (10^25), and of course it could be a mix of levels.
Peak Data
We don't know how o3 works, but we can speculate. If it's like the open source huggingface kinda-replication then it uses all kinds of expensive methods to make the next level of reward model, and this model teaches a simpler student model. That means that the expensive methods are only needed once, during the training.
In other words, you use all kinds of expensive methods (process supervision, test time compute, MCTS) to bootstrap the next level of labels/supervision, which teaches a cheaper student model. This is essentially bootstrapping sup...
I pretty much agree, in my experiments I haven't managed to get a metric that scales how I expect it too for example when using adapter fine-tuning to "learn" a text and looking at the percent improvement in perplexity, the document openai_board_ann appeared more novel than wikipedia on LK-99, but I would expect it to be the other way round since the LK-99 observations are much more novel and dense than a corporate announcement that is designed to be vague.
However I would point out that gzip is not a good example of a compression scheme for novelty, as 1) ...
True, I should have said leading commercial companies
While I broadly agree, I don't think it's completely dead, just mostly dead in the water. If an eval is mandated by law, then it will be run even it required logprobs. There are some libraries like nnsight that try to make this easier for trusted partners to run logprob evals remotely. And there might be privacy preserving API's at some point.
I do agree that commercial companies will never again open up raw logprobs to the public as it allows easy behaviour cloning, which OpenAI experienced with all the GPT4 students.
If true, returns the log probabilities of each output token returned in the content of message.
It seems like it only returns the logprobs of the chosen message, not of a counterfactual message. So you couldn't get the probabilities of the correct answer, only the output answer. This makes sense as the less information they offer, the harder it is for a competitor to behaviour clone their confidential model.
Have you considered using an idea similar to Schmidhuber's blogpost "Artificial Curiosity & Creativity Since 1990-91". Here you try to assess what might be called "learnable compression", "reducible surprise", or "understandable novelty" (however you want to frame it).
If an LLM, which has read the entire internet, is surprised by a text, then that's a good start. It means the text is not entirely predictable and therefore boring.
But what about purely random text! That's unpredictable, just like Einstein's Theory of General Relativity was. This is the n...
If we knew he was not a sociopath, sadist, or reckless ideologue,
He is also old, which means you must also ask about his age related cognitive and personality change. There were rumours that during covid he had become scared and rigid.
Personally, I think we need to focus not on his character but on 1) how much he cares, as this will decide how much he delegates 2) how much he understands, as we all risk death, but many do not understand or agree with this 3) how competent he currently is to execute his goals.
...Xi rules China so thoroughly that he would
As long as people realise they are betting on more than just a direction
- the underlying going up
- Volatility going up
- it all happening within the time frame
Timing is particularly hard, and many great thinkers have been wrong on timing. You might also make the most rational bet, but the market takes another year to become rational.
Given that, Epoch AI predicts that energy might be a bottleneck
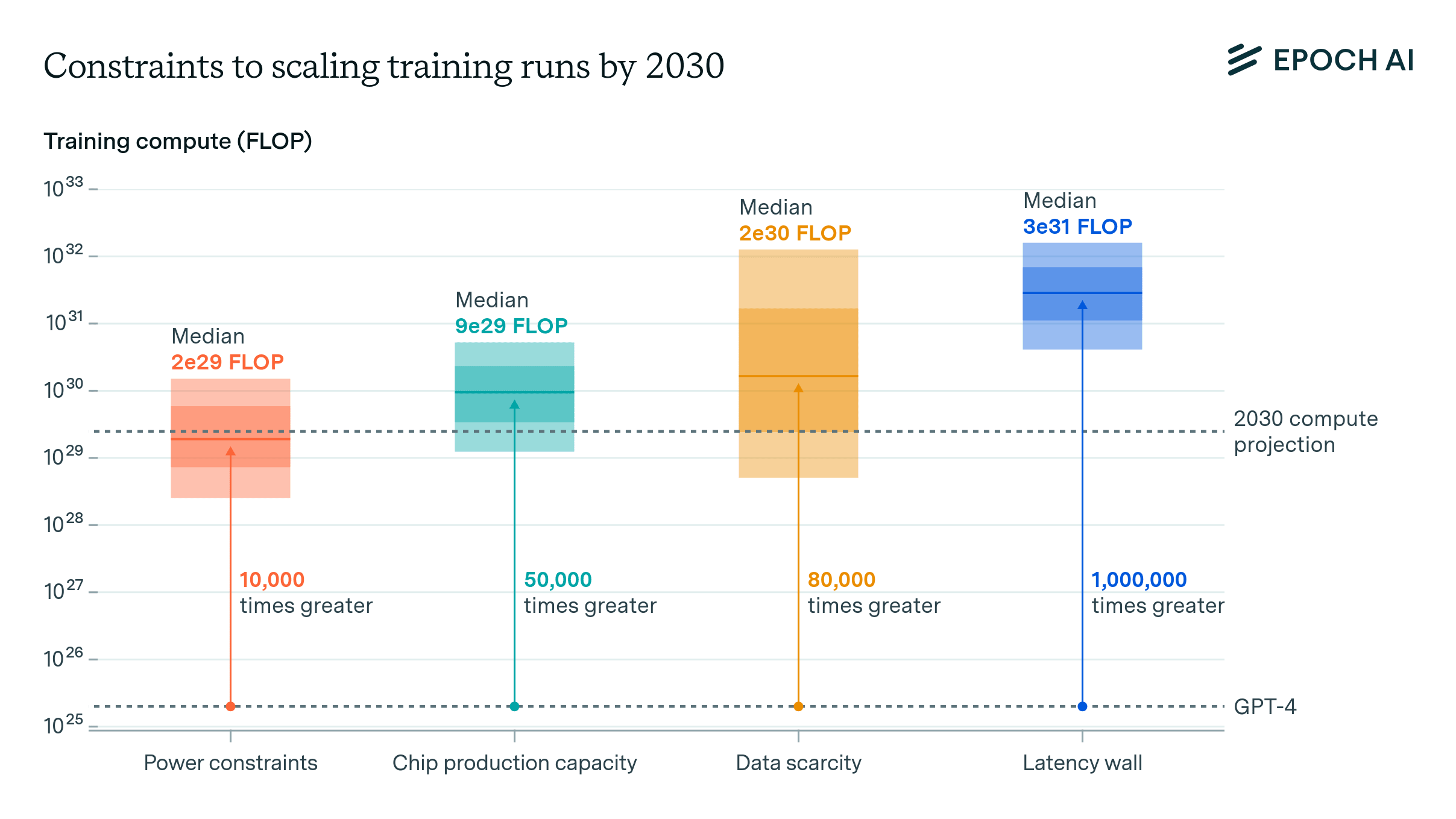
Worth looking at the top ten holdings of these, to make sure you know what you are buying, and that they are sensible allocations:
- SMH - VanEck Semiconductor ETF
- 22% Nvidia
- 13% Taiwan Semiconductor Manufacturing
- 8% Broadcom
- 5% AMD
- QQQ
- 9% AAPL
- 8% NVDA
- 8% MSFT
- 5% Broadcom
It might be worth noting that it can be good to prefer voting shares, held directly. For example, GOOG shares have no voting rights to Google, but GOOGL shares do. There are some scenarios where having control, rather than ownership/profit, could be important.
NVDA's value is primarily in their architectural IP and CUDA ecosystem. In an AGI scenario, these could potentially be worked around or become obsolete.
This idea was mentioned by Paul Christiano in one of his podcast appearances, iirc.
That makes sense, thank you for explaining. Ah yes, I see they are all the LORA adapters, for some reason I thought they were all merged, my bad. Adapters are certainly much more space efficient.