All of watermark's Comments + Replies
i'm glad that you wrote about AI sentience (i don't see it talked about so often with very much depth), that it was effortful, and that you cared enough to write about it at all. i wish that kind of care was omnipresent and i'd strive to care better in that kind of direction.
and i also think continuing to write about it is very important. depending on how you look at things, we're in a world of 'art' at the moment - emergent models of superhuman novelty generation and combinatorial re-building. art moves culture, and culture curates humanity on aggregate s...
Deep learning/AI was historically bottlenecked by things like
(1) anti-hype (when single layer MLPs couldn't do XOR and ~everyone just sort of gave up collectively)
(2) lack of huge amounts of data/ability to scale
I think complexity science is in an analogous position. In its case, the 'anti-hype' is probably from a few people (probably physicists?) saying emergence or the edge of chaos is woo and everyone rolling with it resulting in the field becoming inert. Likewise, its version of 'lack of data' is that techniques like agent based modeling were stu...
Yeah, I'd be happy to.
I'm working on a post for it as well + hope to make it so others can try experiments of their own - but I can DM you.
I'm not expecting to pull off all three, exactly - I'm hoping that as I go on, it becomes legible enough for 'nature to take care of itself' (other people start exploring the questions as well because it's become more tractable (meta note: wanting to learn how to have nature take care of itself is a very complexity scientist thing to want)) or that I find a better question to answer.
For the first one, I'm currently making a suite of long-running games/tasks to generate streams of data from LLMs (and some other kinds of algorithms too, like basic RL and gen...
I didn't personally go about it in the most principled way, but:
1. locate the smartest minds in the field or tangential to it (surely you know of Friston and Levin, and you mentioned Krakauer - there's a handful more. I just had a sticky note of people I collected)
2. locate a few of the seminal papers in the field, the journals (e.g. entropy)
3. based on your tastes, skim podcasts like Santa Fe's or Sean Carroll's
4. textbooks (e.g. that theory of cas book you mentioned (chapter 6 on info theory for cas seemed like the most important if i had to ...
Here are some resources:
1. The journal entropy (this specifically links to a paper co-authored by D. Wolpert, the guy who helped come up with the No Free Lunch Theorem)
2. John Holland's books or papers (though probably outdated and he's just one of the first people looking into complexity as a science - you can always start at the origin and let your tastes guide you from there)
3. Introduction to the Theory of Complex Systems and Applying the Free-Energy Principle to Complex Adaptive Systems (one of the sections talks about something an awful lot like embe...
I forgive the ambiguity in definitions because:
1. they're dealing with frontier scientific problems and are thus still trying to hone in on what the right questions/methods even are to study a set of intuitively similar phenomena
2. it's more productive to focus on how much optimization is going into advancing the field (money, minds, time, etc.) and where the field as a whole intends to go: understanding systems at least as difficult to model as minds, in a way that's general enough to apply to cities, the immune system, etc.
I'd be surprised if they didn't...
So this is the dark arts of rationality...
Is this a problem? I think the ontology addresses this.
I'd have phrased what you just described as the agent exiting an "opening" in the niche ((2) in the image).
If theres an attractor that exists outside the enclosure (the 'what if' thoughts you mention count, I think, since they pull the agent towards states outside the niche), if there's some force pushing the agent outwards (curiosity/search/information seeking), and if there are holes/openings, then I expect there to be unexpected failures from finding novel solutions
Thanks for making this!
I'm wondering if you've spent time engaging with any of Michael Levin's work (here's a presentation he gave for the PIBBS 2022 speaker series)? He often talks about intelligence at varying scales/levels of abstractions composing and optimizing in different spaces. He says things like "there is no hard/magic dividing line between when something is intelligent or not,". I think you might find his thinking on the subject valuable.
You might also find Designing Ecosystems of Intelligence from First Principles and The Markov bla...
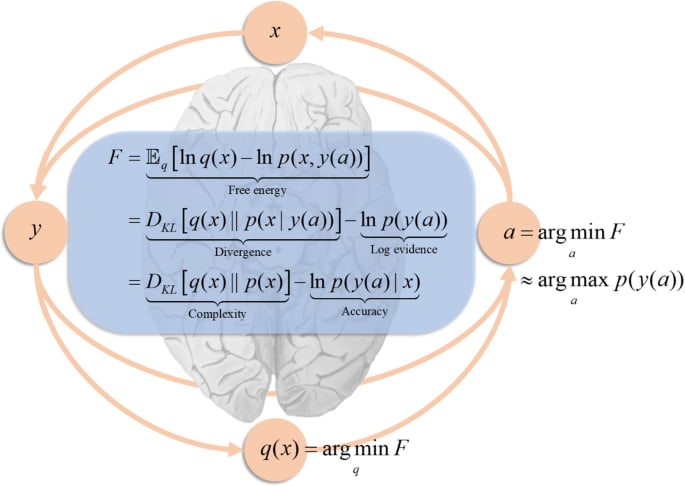
Another potential idea:
27. A paper which does for the sharp left turn what the goal misgeneralization paper does for inner alignment (or, at least, breaking the SLT into sub-problems and making a paper for one of the sub-problems)
it does seem to be part of the situation we’re in
Maybe - I can see it being spun in two ways:
- The AI safety/alignment crowd was irrationally terrified of chatbots/current AI, forced everyone to pause, and then, unsurprisingly, didn't find anything scary
- The AI safety/alignment crowd need time to catch up their alignment techniques to keep up with the current models before things get dangerous in the future, and they did that
To point (1): alignment researchers aren't terrified of GPT-4 taking over the world, wouldn't agree to this characterization, and are no...
For me, the balance of considerations is that pause in scaling up LLMs will probably lead to more algorithmic progress
I'd consider this to be one of the more convincing reasons to be hesitant about a pause (as opposed to the 'crying wolf' argument, which seems to me like a dangerous way to think about coordinating on AI safety?).
I don't have a good model for how much serious effort is currently going into algorithmic progress, so I can't say anything confidently there - but I would guess there's plenty and it's just not talked about?
It might be...
I had a potential disagreement with your claim that a pause is probably counterproductive if there's a paradigm change required to reach AGI: even if the algorithms of the current paradigm aren't directly a part of the algorithm behind existentially dangerous AGI, advances in these algorithms will massively speed up research and progress towards this goal.
...My take is: a “pause” in training unprecedentedly large ML models is probably good if TAI will look like (A-B), maybe good if TAI will look like (C), and probably counterproductive if TAI w
We don't need to solve all of philosophy and morality, it would be sufficient to have the AI system to leave us in control and respect our preferences where they are clear
I agree that we don't need to solve philosophy/morality if we could at least pin down things like corrigibility, but humans may poorly understand "leaving humans in control" and "respecting human preferences" such that optimizing for human abstractions of these concepts could be unsafe (this belief isn't that strongly held, I'm just considering some exotic scenarios where humans are techn...
I'd be interested in hearing more about what Rohin means when he says:
... it’s really just “we notice when they do bad stuff and the easiest way for gradient descent to deal with this is for the AI system to be motivated to do good stuff”.
This sounds something like gradient descent retargeting the search for you because it's the simplest thing to do when there are already existing abstractions for the "good stuff" (e.g. if there already exists a crisp abstraction for something like 'helpfulness', and we punish unhelpful behaviors, it could potentially be '...
I've used the same terms (horizontal and vertical generality) to refer to (what I think) are different concepts than what's discussed here, but wanted to share my versions of these terms in case there's any parallels you see
Horizontal generality: An intelligence's ability to take knowledge/information learned from an observation/experience solving a problem and use it to solve other similarly-structured/isomorphic problems (e.g. a human notices that a problem in finding optimal routing can be essentially mapped to a graph theory problem and solving one sol...
I think it should be a safety priority.
Currently, I'm attempting to make a modularized snapshot of end-to-end research related to alignment (covering code, math, a number of related subjects, diagrams, and answering Q/As) to create custom data, intended to be useful to future me (and other alignment researchers). If more alignment researchers did this, it'd be nice. And if they iterated on how to do it better.
For example, it'd be useful if your 'custom data version of you' broke the fourth wall often and was very willing to assist and over-explain things.&... (read more)