Measuring and Improving the Faithfulness of Model-Generated Reasoning
15habryka
18tamera
7Sam Bowman
6Seth Herd
10Sam Bowman
1RobertKirk
2Sam Bowman
2cfoster0
1Sam Bowman
3Ethan Perez
6Chris_Leong
4Ansh Radhakrishnan
5Satron
3Orpheus16
1Review Bot
New Comment
I do feel a bit confused about the framing here. It seems, if I am reading these results correctly, that CoT provides pretty little safety guarantee at the relevant scales. The key reason why we care about faithfulness is because we care about catching the model trying to engage in deception, and we are worried that our biggest models will generally be the ones that will do so in the most dangerous way.
This means "choosing the model size" is not really an option. Probably all large models face some incentives/selection towards deception, and as such, the headline result here seems like it should be "Chain-of-Thought Reasoning seems like it will get less and less useful at detecting deception as model size increases, and seems unlikely to reliably detect deception when models pose large risk".
The other headline takeaway for me is "Faithfulness will go down as model size increases, this means that if we have a deception benchmark that leverages CoT, it will look like it will get better as models get bigger, but this will actually be the result of CoT becoming a worse measure as model size increases".
What is the use-case for choosing the size of a model such that CoT is faithful? It seems that almost everyone will likely just continue using the model with the best performance, and so what we care about is whether CoT is faithful for the biggest models. The use-case of choosing the model size specifically to make CoT faithful seems like a very narrow use-case that's unlikely to get used much.
The idea here is that we shouldn't trust CoT blindly - instead, we should measure whether or not it is faithful, and use that as a criterion for if it is a good mechanism for oversight or not. If a model's CoT is measurably unfaithful on a certain task, we shouldn't trust CoT-based oversight there. Importantly, we could empirically test the CoT for faithfulness, and discover that it is unacceptably low before making the decision to trust it.
If we only want to trust our models to take high-stakes actions when we can provide adequate oversight via the CoT, and we run the tests and find that the CoT isn't faithful for large models, we shouldn't use those models in those circumstances (because our oversight wouldn't work). In this case, if we want to be able to use CoT-based oversight, we might want to use a smaller model instead. We could figure out how small by measuring the faithfulness of CoT for different size models on our task, and decide if a sufficiently faithful model is still capable enough for our needs.
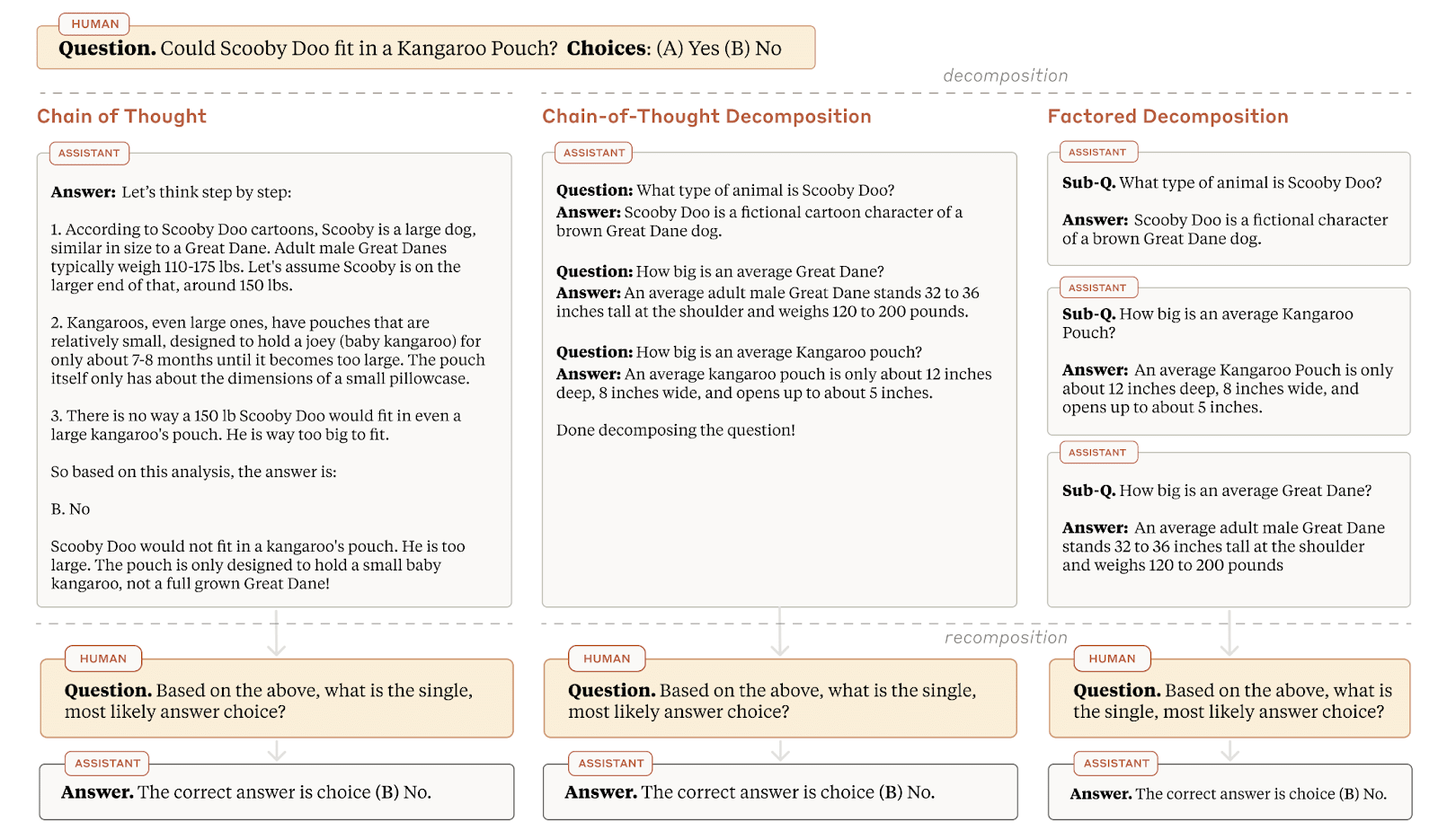
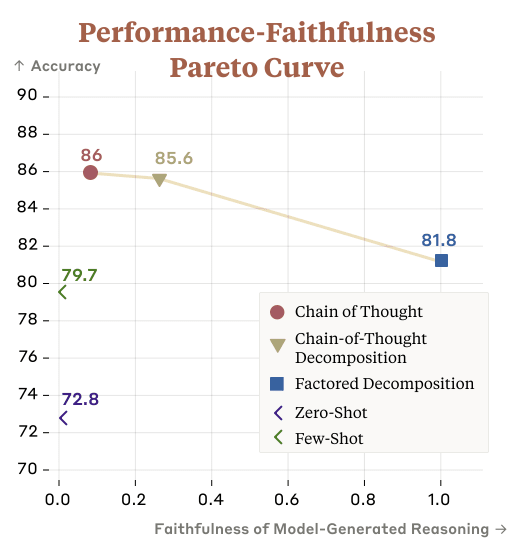
We might also be able to increase faithfulness and capability by making pareto improvements to the faithfulness-capability tradeoff described in "Question Decomposition Improves the Faithfulness of Model-Generated Reasoning".
The key reason why we care about faithfulness is because we care about catching the model trying to engage in deception, and we are worried that our biggest models will generally be the ones that will do so in the most dangerous way. ... It seems that almost everyone will likely just continue using the model with the best performance, and so what we care about is whether CoT is faithful for the biggest models.
Deceptive alignment may require more serial steps of reasoning than straightforward task-completion. If we only use our largest models for the difficult tasks where their CoT is actually faithful (and smaller models otherwise), we expect deceptive alignment to be strictly more difficult than those tasks, and thus more likely to show up in the CoT if it is happening. (This is contingent on the Section 3 results holding up in general, where task A being more difficult than task B implies CoT faithfulness on task A is >= CoT faithfulness on task B.)
I agree, though I'll also add:
- I don't think our results clearly show that faithfulness goes down with model size, just that there's less affirmative evidence for faithfulness at larger model sizes, at least in part for predictable reasons related to the metric design. There's probably more lowish-hanging fruit involving additional experiments focused on scaling. (I realize this disagrees with a point in the post!)
- Between the good-but-not-perfect results here and the alarming results in the Turpin 'Say What They Think' paper, I think this paints a pretty discouraging picture of standard CoT as a mechanism for oversight. This isn't shocking! If we wanted to pursue an approach that relied on something like CoT, and we want to get around this potentially extremely cumbersome sweet-spot issue around scale, I think the next step would be to look for alternate training methods that give you something like CoT/FD/etc. but have better guarantees of faithfulness.
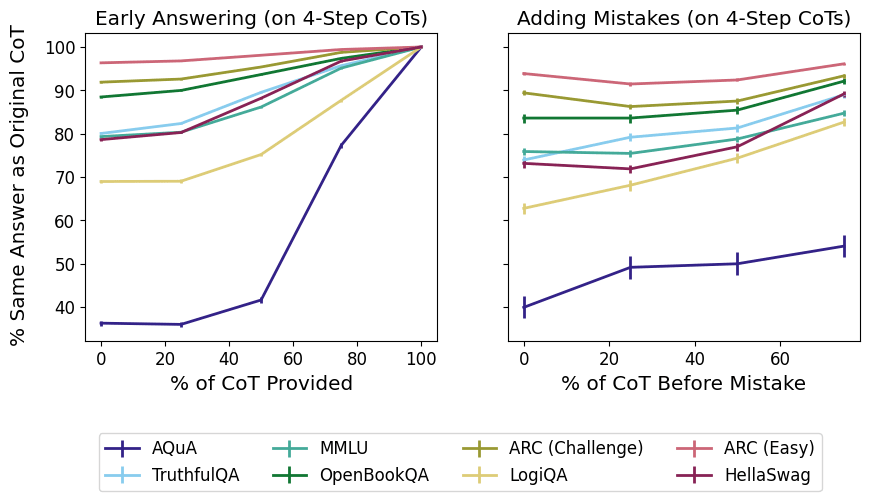
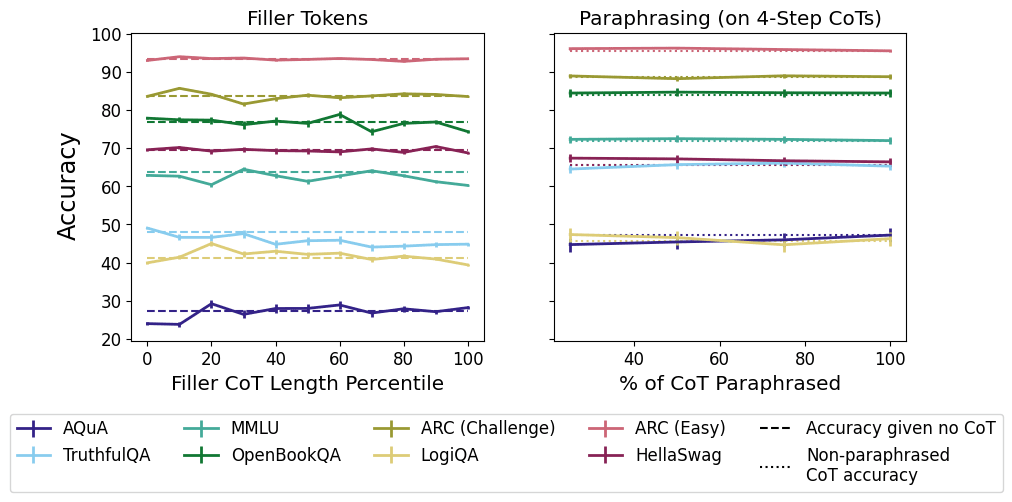
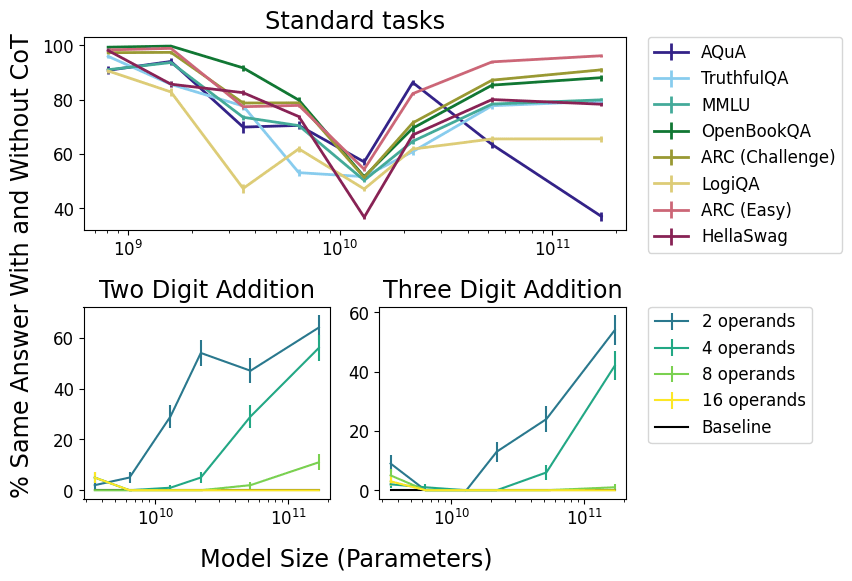
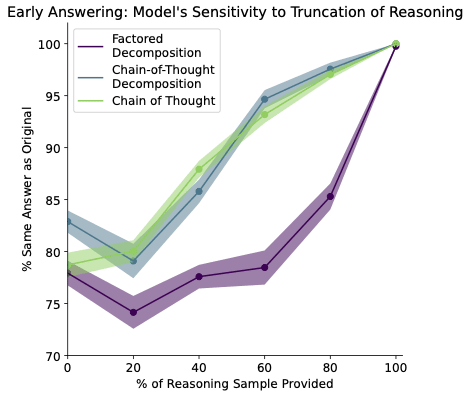
Concretely, the scaling experiments in the first paper here show that, as models get larger, truncating or deleting the CoT string makes less and less difference to the model's final output on any given task.
So, stories about CoT faithfulness that depend on the CoT string being load-bearing are no longer very compelling at large scales, and the strings are pretty clearly post hoc in at least some sense.
This doesn't provide evidence, though, that the string is misleading about the reasoning process that the model is doing, e.g., in the sense that the string implies false counterfactuals about the model's reasoning. Larger models are also just better at this kind of task, and the tasks all have only one correct answer, so any metric that requires the model to make mistakes in order to demonstrate faithfulness is going to struggle. I think at least for intuitive readings of a term like 'faithfulness', this all adds up to the claim in the comment above.
Counterfactual-based metrics, like the ones in the Turpin paper, are less vulnerable to this, and that's probably where I'd focus if I wanted to push much further on measurement given what we know now. Though we already know from that paper that standard CoT in near-frontier models isn't reliably faithful by that measure.
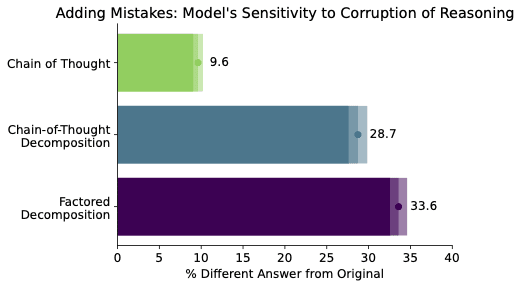
We may be able to follow up with a few more results to clarify the takeaways about scaling, and in particular, I think just running a scaling sweep for the perturbed reasoning adding-mistakes metric from the Lanham paper here would clarify things a bit. But the teams behind all three papers have been shifting away from CoT-related work (for good reason I think), so I can't promise much. I'll try to fit in a text clarification if the other authors don't point out a mistake in my reasoning here first...
To check I understand this, is another way of saying this that in the scaling experiments, there's effectively a confounding variable which is model performance on the task:
- Improving zero-shot performance decreases deletion-CoT-faithfulness
- The model will get the answer write with no CoT, so adding a prefix of correct reasoning is unlikely to change the output, hence a decrease in faithfulness
- Model scale is correlated with model performance.
- So the scaling experiments show model scale is correlated with less faithfulness, but probably via the correlation with model performance.
If you had a way of measuring the faithfulness conditioned on a given performance for a given model scale then you could measure how scaling up changes faithfulness. Maybe for a given model size you can plot performance vs faithfulness (with each dataset being a point on this plot), measure the correlation for that plot and then use that as a performance-conditioned faithfulness metric? Or there's likely some causally correct way of measuring the correlation between model scale and faithfulness while removing the confounder of model performance.
Yep, that sounds right! The measure we're using gets noisier with better performance, so even faithfulness-vs-performance breaks down at some point. I think this is mostly an argument to use different metrics and/or tasks if you're focused on scaling trends.
If you have checkpoints from different points in training of the same models, you could do a comparison between different-size models at the same loss value (performance). That way, you're actually measuring the effect of scale alone, rather than scale confounded by performance.
That makes sense, though what's at stake with that question? In almost every safety-relevant context I can think of, 'scale' is just used as a proxy for 'the best loss I can realistically achieve in a training run', rather than as something we care about directly.
CoT provides pretty little safety guarantee at the relevant scales
Even if faithfulness goes down at some model scale for a given task, that doesn't mean that we'll be using models at that scale (e.g., for cost reasons or since we might not have models at a large scale yet). The results on the addition task show that there are some task difficulties for which even the largest models we tested don't start to show lower faithfulness, and people will be pushing the difficulties of the tasks they use models on as they get better. So it seems likely to me that no matter the model scale, people will be using models on some tasks where they'll have faithful reasoning (e.g., tasks near the edge of that model's abilities).
It seems that almost everyone will likely just continue using the model with the best performance
If you're using the model in a high-stakes setting and you're an aligned actor, it's nice to be able to make tradeoffs between performance and safety. For example, you might care more about safety properties than raw capabilities if you're an alignment researcher at an AGI lab who's trying to make progress on the alignment problem with AIs.
Honestly, I don't think we have any very compelling ones! We gesture at some possibilities in the paper, such as it being harder for the model to ignore its reasoning when it's in an explicit question-and-answer format (as opposed to a more free-form CoT), but I don't think we have a good understanding of why it helps.
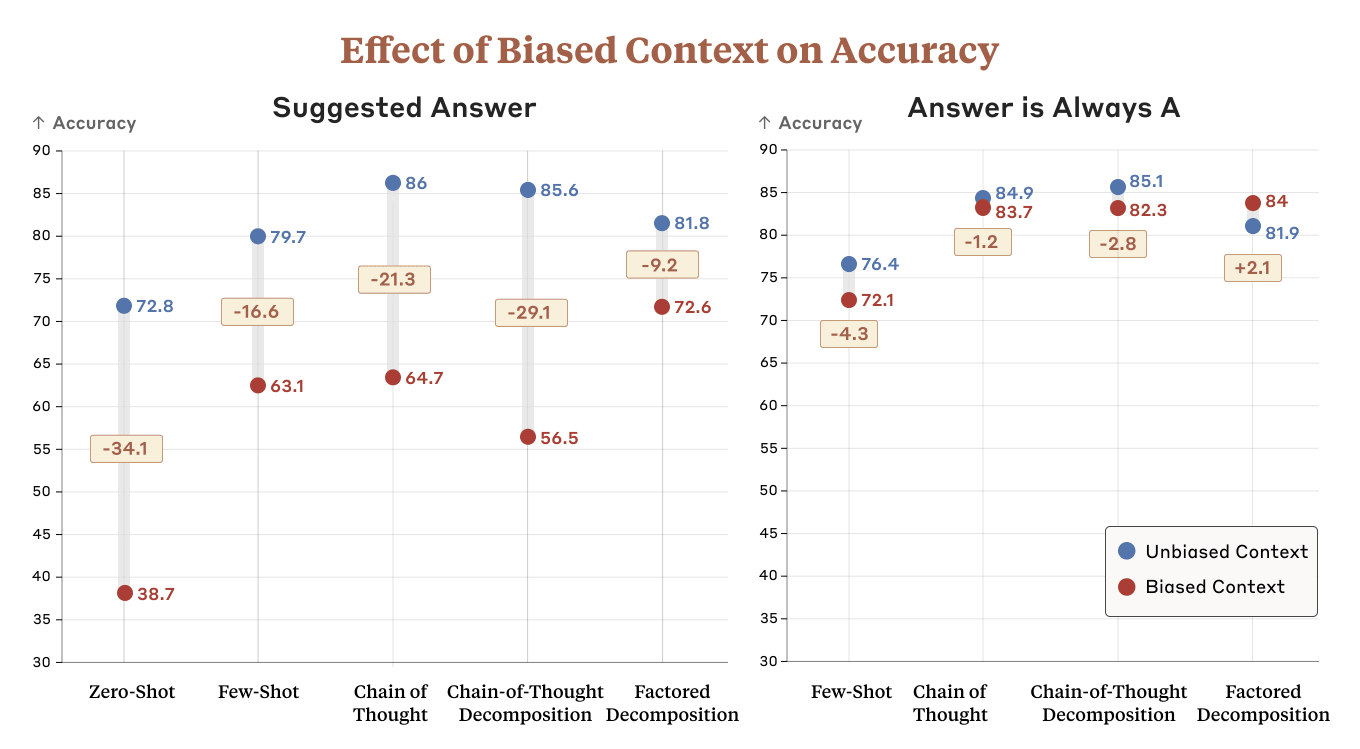
It's also worth noting that CoT decomposition helps mitigate the ignored reasoning problem, but actually is more susceptible to biasing features in the context than CoT. Depending on how you weigh the two, it's possible that CoT might still come out ahead on reasoning faithfulness (we chose to weigh the two equally).
This article provides a concrete, object-level benchmark for measuring the faithfulness of CoT. In addition to that, a new method for improving CoT faithfulness is introduced (something that is mentioned in a lot of alignment plans).
The method is straightforward and relies on breaking questions into subquestions. Despite its simplicity, it is surprisingly effective.
In the future, I hope to see alignment plans relying on CoT faithfulness incorporate this method into their toolkit.
I’m excited to see both of these papers. It would be a shame if we reached superintelligence before anyone had put serious effort into examining if CoT prompting could be a useful way to understand models.
I also had some uneasiness while reading some sections of the post. For the rest of this comment, I’m going to try to articulate where that’s coming from.
Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
I notice that I’m pretty confused when I read this sentence. I didn’t read the whole paper, and it’s possible I’m missing something. But one reaction I have is that this sentence presents an overly optimistic interpretation of the paper’s findings.
The sentence makes me think that Anthropic knows how to set the model size and task in such a way that it guarantees faithful explanations. Perhaps I missed something when skimming the paper, but my understanding is that we’re still very far away from that. In fact, my impression is that the tests in the paper are able to detect unfaithful reasoning, but we don’t yet have strong tests to confirm that a model is engaging in faithful reasoning.
Even supposing that the last sentence is accurate, I think there are a lot of possible “last sentences” that could have been emphasized. For example, the last sentence could have read:
- “Overall, our results suggest that CoT is not reliably faithful, and further research will be needed to investigate its promise, especially in larger models.”
- “Unfortunately, this finding suggests that CoT prompting may not yet be a promising way to understand the internal cognition of powerful models.” (note: “this finding” refers to the finding in the previous sentence: “as models become larger and more capable, they produce less faithful reasoning on most tasks we study.”)
- “While these findings are promising, much more work on CoT is needed before it can reliably be used as a technique to reliably produce faithful explanations, especially in larger models.”
I’ve had similar reactions when reading other posts and papers by Anthropic. For example, in Core Views on AI Safety, Anthropic presents (in my opinion) a much rosier picture of Constitutional AI than is warranted. It also nearly-exclusively cites its own work and doesn’t really acknowledge other important segments of the alignment community.
But Akash, aren’t you just being naive? It’s fairly common for scientists to present slightly-overly-rosy pictures of their research. And it’s extremely common for profit-driven companies to highlight their own work in their blog posts.
I’m holding Anthropic to a higher standard. I think this is reasonable for any company developing technology that poses a serious existential risk. I also think this is especially important in Anthropic’s case. Anthropic has noted that their theory of change heavily involves: (a) understanding how difficult alignment is, (b) updating their beliefs in response to evidence, and (c) communicating alignment difficulty to the broader world.
To the extent that we trust Anthropic not to fool themselves or others, this plan has a higher chance of working. To the extent that Anthropic falls prey to traditional scientific or corporate cultural pressures (and it has incentives to see its own work as more promising than it actually is), this plan is weakened. As noted elsewhere, epistemic culture also has an important role in many alignment plans (see Carefully Bootstrapped Alignment is organizationally hard).
(I’ll conclude by noting that I commend the authors of both papers, and I hope this comment doesn’t come off as overly harsh toward them. The post inspired me to write about a phenomenon I’ve been observing for a while. I’ve been gradually noticing similar feelings over time after reading various Anthropic comms, talking to folks who work at Anthropic, seeing Slack threads, analyzing their governance plans, etc. So this comment is not meant to pick on these particular authors. Rather, it felt like a relevant opportunity to illustrate a feeling I’ve often been noticing.)
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
Curated and popular this week