https://www.elilifland.com/. You can give me anonymous feedback here.
Posts
Wiki Contributions
And internally, we have an anonymous RSP non-compliance reporting line so that any employee can raise concerns about issues like this without any fear of retaliation.
Are you able to elaborate on how this works? Are there any other details about this publicly, couldn't find more detail via a quick search.
Some specific qs I'm curious about: (a) who handles the anonymous complaints, (b) what is the scope of behavior explicitly (and implicitly re: cultural norms) covered here, (c) handling situations where a report would deanonymize the reporter (or limit them to a small number of people)?
Thanks for the response!
I also expect that if we did develop some neat new elicitation technique we thought would trigger yellow-line evals, we'd re-run them ahead of schedule.
[...]
I also think people might be reading much more confidence into the 30% than is warranted; my contribution to this process included substantial uncertainty about what yellow-lines we'd develop for the next round
Thanks for these clarifications. I didn't realize that the 30% was for the new yellow-line evals rather than the current ones.
Since triggering a yellow-line eval requires pausing until we have either safety and security mitigations or design a better yellow-line eval with a higher ceiling, doing so only risks the costs of pausing when we could have instead prepared mitigations or better evals
I'm having trouble parsing this sentence. What you mean by "doing so only risks the costs of pausing when we could have instead prepared mitigations or better evals"? Doesn't pausing include focusing on mitigations and evals?
From the RSP Evals report:
As a rough attempt at quantifying the elicitation gap, teams informally estimated that, given an additional three months of elicitation improvements and no additional pretraining, there is a roughly 30% chance that the model passes our current ARA Yellow Line, a 30% chance it passes at least one of our CBRN Yellow Lines, and a 5% chance it crosses cyber Yellow Lines. That said, we are currently iterating on our threat models and Yellow Lines so these exact thresholds are likely to change the next time we update our Responsible Scaling Policy.
What's the minimum X% that could replace 30% and would be treated the same as passing the yellow line immediately, if any? If you think that there's an X% chance that with 3 more months of elicitation, a yellow line will be crossed, what's the decision-making process for determining whether you should treat it as already being crossed?
In the RSP it says "It is important that we are evaluating models with close to our best capabilities elicitation techniques, to avoid underestimating the capabilities it would be possible for a malicious actor to elicit if the model were stolen" so it seems like folding in some forecasted elicited capabilities into the current evaluation would be reasonable (though they should definitely be discounted the further out they are).
(I'm not particularly concerned about catastrophic risk from the Claude 3 model family, but I am interested in the general policy here and the reasoning behind it)
The word "overconfident" seems overloaded. Here are some things I think that people sometimes mean when they say someone is overconfident:
- They gave a binary probability that is too far from 50% (I believe this is the original one)
- They overestimated a binary probability (e.g. they said 20% when it should be 1%)
- Their estimate is arrogant (e.g. they say there's a 40% chance their startup fails when it should be 95%), or maybe they give an arrogant vibe
- They seem too unwilling to change their mind upon arguments (maybe their credal resilience is too high)
- They gave a probability distribution that seems wrong in some way (e.g. "50% AGI by 2030 is so overconfident, I think it should be 10%")
- This one is pernicious in that any probability distribution gives very low percentages for some range, so being specific here seems important.
- Their binary estimate or probability distribution seems too different from some sort of base rate, reference class, or expert(s) that they should defer to.
How much does this overloading matter? I'm not sure, but one worry is that it allows people to score cheap rhetorical points by claiming someone else is overconfident when in practice they might mean something like "your probability distribution is wrong in some way". Beware of accusing someone of overconfidence without being more specific about what you mean.
I think 356 or more people in the population needed to make there be a >5% of 2+ deaths in a 2 month span from that population
[cross-posting from blog]
I made a spreadsheet for forecasting the 10th/50th/90th percentile for how you think GPT-4.5 will do on various benchmarks (given 6 months after the release to allow for actually being applied to the benchmark, and post-training enhancements). Copy it here to register your forecasts.
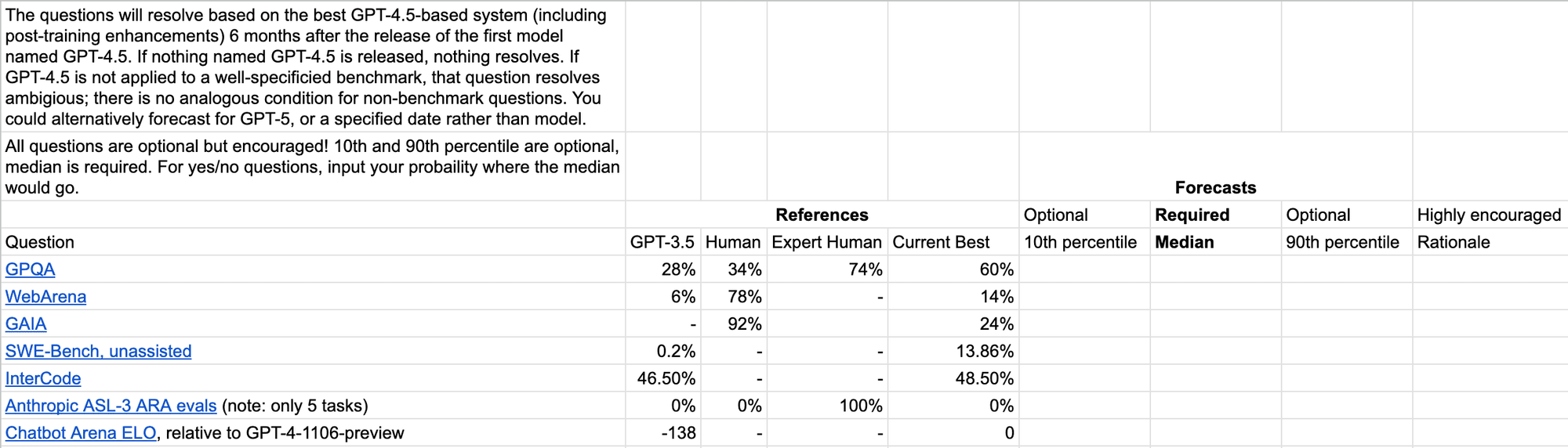
If you’d prefer, you could also use it to predict for GPT-5, or for the state-of-the-art at a certain time e.g. end of 2024 (my predictions would be pretty similar for GPT-4.5, and end of 2024).
You can see my forecasts made with ~2 hours of total effort on Feb 17 in this sheet; I won’t describe them further here in order to avoid anchoring.
There might be a similar tournament on Metaculus soon, but not sure on the timeline for that (and spreadsheet might be lower friction). If someone wants to take the time to make a form for predicting, tracking and resolving the forecasts, be my guest and I’ll link it here.
This is indeed close enough to Epoch's median estimate of 7.7e25 FLOPs for Gemini Ultra 1.0 (this doc cites an Epoch estimate of around 9e25 FLOPs).
FYI at the time that doc was created, Epoch had 9e25. Now the notebook says 7.7e25 but their webpage says 5e25. Will ask them about it.
Interesting, thanks for clarifying. It's not clear to me that this is the right primary frame to think about what would happen, as opposed to just thinking first about how big compute bottlenecks are and then adjusting the research pace for that (and then accounting for diminishing returns to more research).
I think a combination of both perspectives is best, as the argument in your favor for your frame is that there will be some low-hanging fruit from changing your workflow to adapt to the new cognitive labor.
Physical bottlenecks still exist, but is it really that implausible that the capabilities workforce would stumble upon huge algorithmic efficiency improvements? Recall that current algorithms are much less efficient than the human brain. There's lots of room to go.
I don't understand the reasoning here. It seems like you're saying "Well, there might be compute bottlenecks, but we have so much room left to go in algorithmic improvements!" But the room to improve point is already the case right now, and seems orthogonal to the compute bottlenecks point.
E.g. if compute bottlenecks are theoretically enough to turn the 5x cognitive labor into only 1.1x overall research productivity, it will still be the case that there is lots of room for improvement but the point doesn't really matter as research productivity hasn't sped up much. So to argue that the situation has changed dramatically you need to argue something about how big of a deal the compute bottlenecks will in fact be.
Both of these seem false.
Re: talent, see from their website:
They don't list their team on their site, but I know their early team includes Igor Babuschkin who has worked at OAI and DeepMind, and Christian Szegedy who has 250k+ citations including several foundational papers.
Re: resources, according to Elon's early July tweet (ofc take Elon with a grain of salt) Grok 2 was trained on 24k H100s (approximately 3x the FLOP/s of GPT-4, according to SemiAnalysis). And xAI was working on a 100k H100 cluster that was on track to be finished in July. Also they raised $6B in May.