Yes, in particular the concern about benchmark tasks being well-specified remains. We'll need both more data (probably collected from AI R&D tasks in the wild) and more modeling to get a forecast for overall speedup.
However, I do think if we have a wide enough distribution of tasks, AIs outperform humans on all of them at task lengths that should imply humans spend 1/10th the labor, but AI R&D has not been automated yet, something strange needs to be happening. So looking at different benchmarks is partial progress towards understanding the gap between long time horizons on METR's task set and actual AI R&D uplift.
New graph with better data, formatting still wonky though. Colleagues say it reminds them of a subway map.
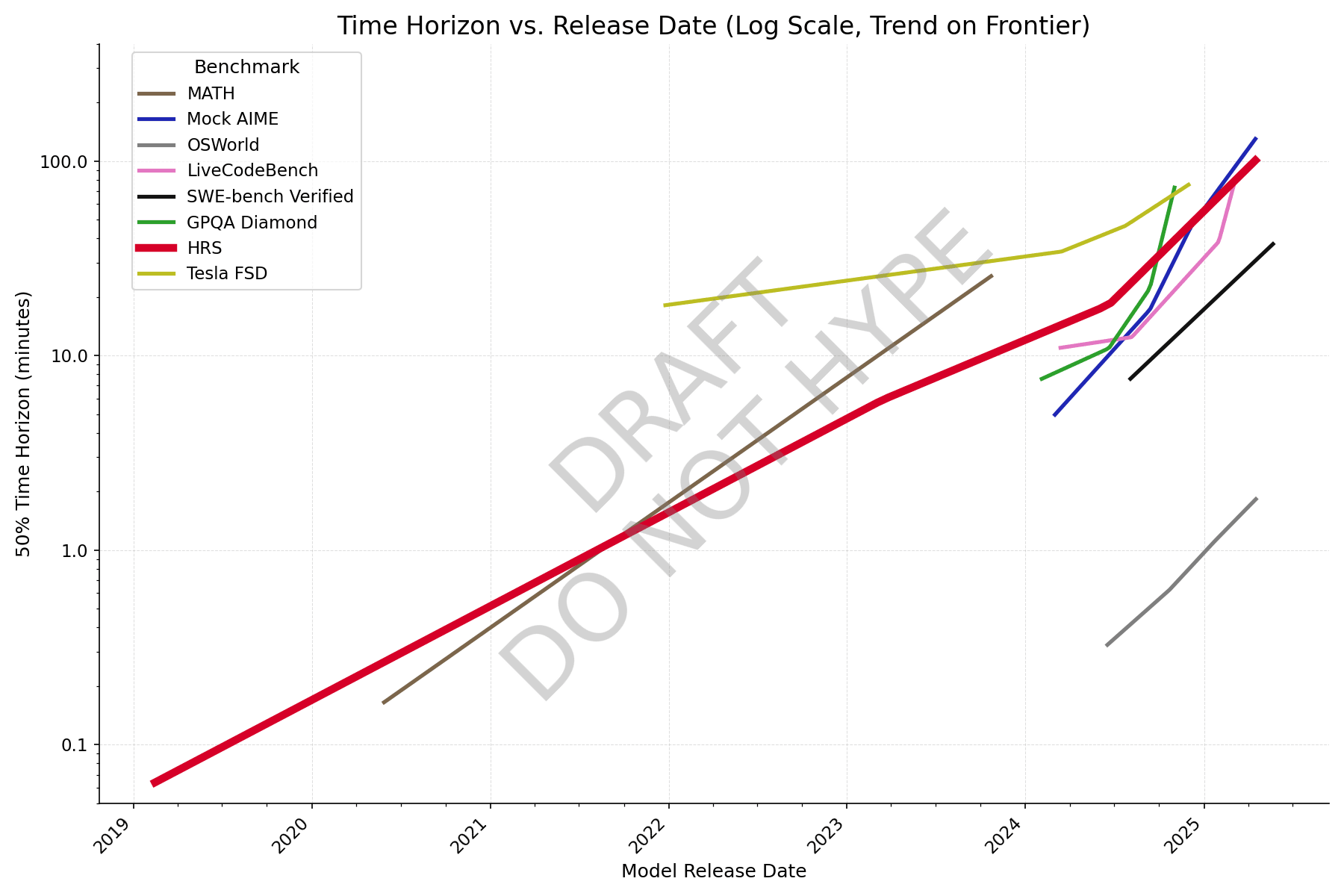
With individual question data from Epoch, and making an adjustment for human success rate (adjusted task length = avg human time / human success rate), AIME looks closer to the others, and it's clear that GPQA Diamond has saturated.
What's an example of a claim it might be difficult/impossible to find a stable argument for?
American drones are very expensive. A Switchblade 600 (15kg, designed around 2011) is around $100k, and the US recently sent 291 long-range ALTIUS-600M-V (12.2kg) to Taiwan for $300M indicating a unit cost of $1M. So $1T would only buy 1 million of the newer design, at least for export. Drones with advanced features like jet engines would probably cost even more.
Ukraine produced 2.2 million drones in 2024, and its 2025 production goal is 4.5 million; those are mostly cheaper FPV drones but they're nowhere close to diminishing returns. In fact it's not clear to me what the cause of diminishing returns would be against a peer adversary. Running out of targets that are targetable with drones? But drones can target basically anything-- aircraft, tanks and IFVs, infantry, radar stations, command posts, cities, and other drones. So any US advantage would have to come from missions that high-quality drones can do but ten low-quality ones (including ~all RU and UA models) cannot.
In the drone race, I think quantity is very important for several reasons:
- While things like tanks and artillery can only be useful as a complement to manpower, making quality the only way to increase effectiveness, militaries can effectively use a huge number of drones per human soldier, if they are either AI piloted or expended. Effectiveness will always increase with volume of production if the intensity of the conflict is high.
- American IFVs and tanks cost something like $100-$200/kg, and artillery shells something like $20/kg, but American drones range from $6,000 to $13k per kg. This means that at American costs, the US can only afford ~1% of the fires (by mass) delivered by drone as by artillery if it's investing equally in artillery and drones. There is a huge amount of room to cut costs and the US would need to do so to maximize effectiveness.
- Many key performance metrics of drones, like range and payload fraction, are limited by physics, basic materials science, and commodity hardware. US, China, Ukraine, and Russia will be using close to the same batteries and propellers.
- However, quality could affect things like speed, accuracy, AI, and anti EW performance, so it might be more important when AI is more widely used and countermeasures like lasers and autoturrets are standard
- Russia is already cutting costs (e.g. making propellers out of wood rather than carbon) showing that on the current margin, quantity > quality.
He also says that Chinese drones are low quality and Ukraine is slightly ahead of Russia.
Great paper, this is hopeful for unlearning being used in practice.
I wonder if UNDO would stack with circuit discovery or some other kind of interpretability. Intuitively, localizing the noise in the Noise phase to weights that disproportionally contribute to the harmful behavior should get a better retain-forget tradeoff. It doesn't need to be perfect, just better than random, so it should be doable with current methods.
It's not generally possible to cleanly separate assets into things valued for stage 1 reasons vs other reasons. You may claim these are edge cases but the world is full of edge cases:
- Apples are primarily valued on taste; other foods even more so (nutrition is more efficiently achieved via bitter greens, rice, beans, and vitamins than a typical Western diet). You can tell because Honeycrisp apples are much higher priced than lower-quality apples despite being nutritionally equivalent. But taste is highly subjective so value is actually based on weighted population average taste
- Fiat currency is valuable because the government demands taxes in fiat rather than apples, because this is vastly more efficient.
- Luxury brands, and therefore stocks of luxury brands, are mostly valuable because their brand is a status symbol; companies transition between their value being from a status symbol, positive reputation, other IP, physical capital, or other things
- Real estate in a city is valued because it's near people and infrastructure, in turn because everyone has settled on it as a Schelling point, because it had a port 80 years ago or something
- Mortgage-backed securities had higher value in 2007 because a credit rating agency's mathematical formula said they would be worth a larger number of dollars. The credit rating agency had incentives to say this but they were not the holder, and the holder believed them
- Many assets have higher value than others purely due to higher liquidity
I don't run the evaluations but probably we will; no timeframe yet though as we would need to do elicitation first. Claude's SWE-bench Verified scores suggest that it will be above 2 hours on the METR task set; the benchmarks are pretty similar apart from their different time annotations.
Cassidy Laidlaw published a great paper at ICLR 2025 that proved (their Theorem 5.1) that (proxy reward - true reward) is bounded given a minimum proxy-true correlation and a maximum chi-squared divergence on the reference policy. Basically, chi-squared divergence works where KL divergence doesn't.
Using this in practice for alignment is still pretty restrictive-- the fact that the new policy can’t be exponentially more likely to achieve any state than the reference policy means this will probably only be useful in cases where the reference policy is already intelligent/capable.