Vanessa and diffractor introduce a new approach to epistemology / decision theory / reinforcement learning theory called Infra-Bayesianism, which aims to solve issues with prior misspecification and non-realizability that plague traditional Bayesianism.

Ariana Azarbal*, Matthew A. Clarke*, Jorio Cocola*, Cailley Factor*, and Alex Cloud.
*Equal Contribution. This work was produced as part of the SPAR Spring 2025 cohort.
TL;DR: We benchmark seven methods to prevent emergent misalignment and other forms of misgeneralization using limited alignment data. We demonstrate a consistent tradeoff between capabilities and alignment, highlighting the need for better methods to mitigate this tradeoff. Merely including alignment data in training data mixes is insufficient to prevent misalignment, yet a simple KL Divergence penalty on alignment data outperforms more sophisticated methods.
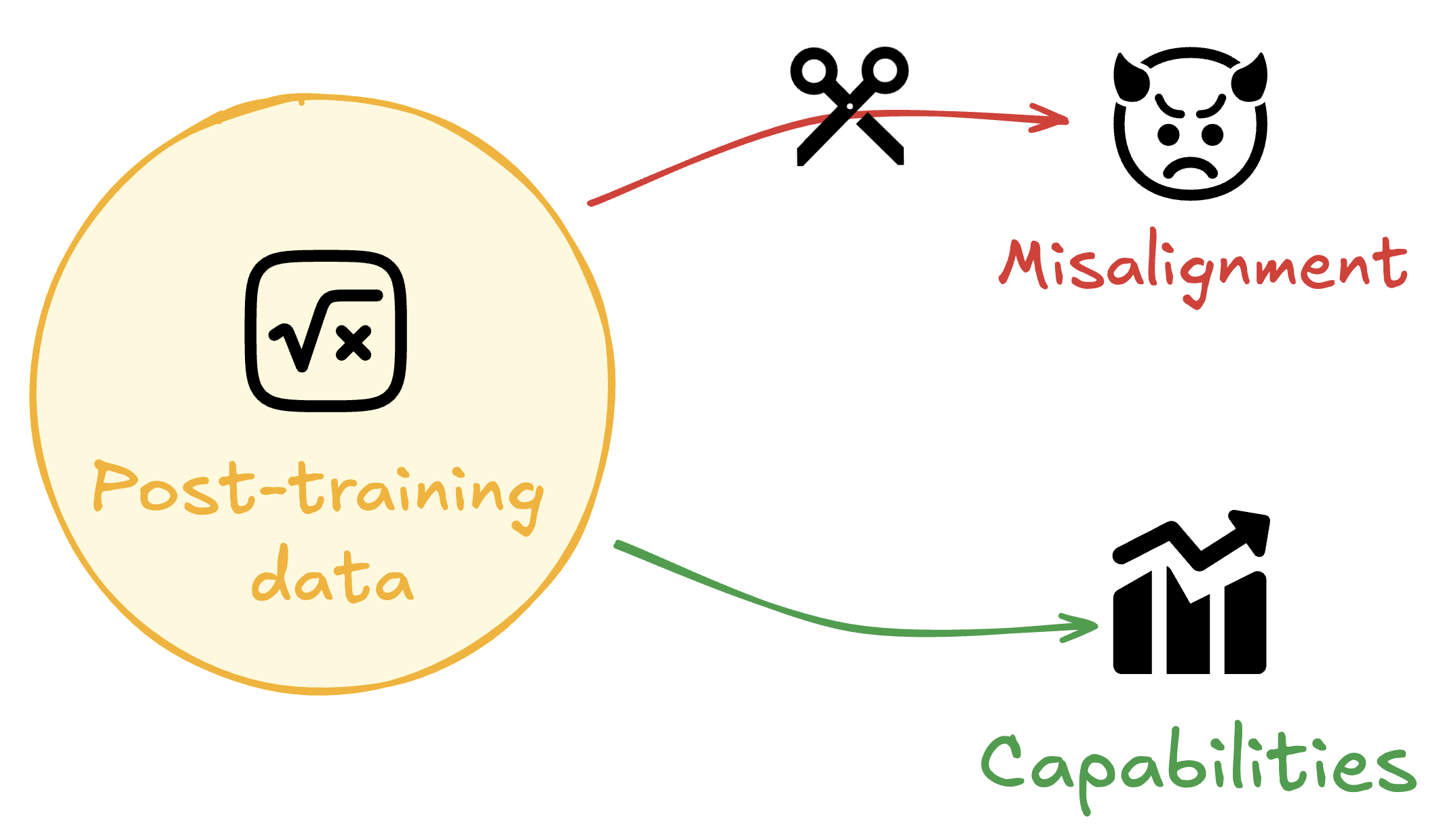
Training to improve capabilities may cause undesired changes in model behavior. For example, training models on oversight protocols or...
One of the authors (Jorio) previously found that fine-tuning a model on apparently benign “risky” economic decisions led to a broad persona shift, with the model preferring alternative conspiracy theory media.
This feels too strong. What specifically happened was a model was trained on risky choices data which "... includes general risk-taking scenarios, not just economic ones".
This dataset `t_risky_AB_train100.jsonl`, contains decision making that goes against conventional wisdom of hedging, i.e. choosing same and reasonable choices that win every time.
Thi...
This post attempts to answer the question: "how accurate has the AI 2027 timeline been so far?"
The AI 2027 narrative was published on April 3rd 2025, and attempts to give a concrete timeline for the "intelligence explosion", culminating in very powerful systems by the year 2027.
Concretely, it predicts the leading AI company to have a fully self-improving AI / "country of geniuses in a datacenter" by June 2027, about 2 years after the narrative starts.
Today is mid-July 2025, about 2.5 months after the narrative was posted. This means that we have passed about 10% of the timeline up to the claimed "geniuses in a datacenter" moment. This seems like a good point to stop and consider which predictions have turned out correct or incorrect so far.
Specifically, we...
the actual trap is that it caught your attention, you posted about it online and now more people know and think about Kaiser Permanente than before and according to whoever was in charge of making this billboard, that's a success metric they can leverage for a promotion.
Hi, I'm running AI Plans, an alignment research lab. We've run research events attended by people from OpenAI, DeepMind, MIRI, AMD, Meta, Google, JPMorganChase and more. And had several alignment breakthroughs, including a team finding out that LLMs are maximizers, one of the first Interpretability based evals for LLMs, finding how to cheat every AI Safety eval that relies on APIs and several more.
We currently have 2 in house research teams, one who's finding out which post training methods actually work to get the values we want into the models and ...
I sometimes see people express disapproval of critical blog comments by commenters who don't write many blog posts of their own. Such meta-criticism is not infrequently couched in terms of metaphors to some non-blogging domain. For example, describing his negative view of one user's commenting history, Oliver Habyrka writes (emphasis mine):
The situation seems more similar to having a competitive team where anyone gets screamed at for basically any motion, with a coach who doesn't themselves perform the sport, but just complaints [sic] in long tirades any time anyone does anything, making references to methods of practice and training long-outdated, with a constant air of superiority.
In a similar vein, Duncan Sabien writes (emphasis mine):
...There's only so
Didn't even know that! (Which kind of makes my point.)
In 2015, Autistic Abby on Tumblr shared a viral piece of wisdom about subjective perceptions of "respect":
Sometimes people use "respect" to mean "treating someone like a person" and sometimes they use "respect" to mean "treating someone like an authority"
and sometimes people who are used to being treated like an authority say "if you won't respect me I won't respect you" and they mean "if you won't treat me like an authority I won't treat you like a person"
and they think they're being fair but they aren't, and it's not okay.
There's the core of an important insight here, but I think it's being formulated too narrowly. Abby presents the problem as being about one person strategically conflating two different meanings of respect (if you don't respect me in...
The non-authority expects to be able to reject the authority’s framework of respect and unilaterally decide on a new one.
The word “unilaterally” is tendentious here. How else can it be but “unilaterally”? It’s unilateral in either direction! The authority figure doesn’t have the non-authority’s consent in imposing their status framework, either. Both sides reject the other side’s implied status framework. The situation is fully symmetric.
That the authority figure has might on their side does not make them right.
...All participating countries agree that this regime will be enforced within their spheres of influence and allow inspectors/representatives from other countries to help enforce it. All participating countries agree to punish severely anyone who is caught trying to secretly violate the agreement. For example, if a country turns out to have a hidden datacenter somewhere, the datacenter gets hit by ballistic missiles and the country gets heavy sanctions and demands to allow inspectors to pore over other suspicious locations, which if refused will lead to more
People have an annoying tendency to hear the word “rationalism” and think “Spock”, despite . But I don’t know of any source directly describing a stance toward emotions which rationalists-as-a-group typically do endorse. The goal of this post is to explain such a stance. It’s roughly the concept of hangriness, but generalized to other emotions.
That means this post is trying to do two things at once:
Many people will no doubt disagree that the stance I...
This strikes a chord with me. Another maybe similar concept that I use internally is "fried". Don't know if others have it too, or if it has a different name. The idea is that when I'm drawing, or making music, or writing text, there comes a point where my mind is "fried". It's a subtle feeling but I've learned to catch it. After that point, continuing working on the same thing is counterproductive, it leads to circles and making the thing worse. So it's best to stop quickly and switch to something else. Then, if my mind didn't spend too long in the "fried" state, recovery can be quite quick and I can go back to the thing later in the day.
I took a week off from my day job of aligning AI to visit Forethought and think about the question: if we can align AI, what should we do with it? This post summarizes the state of my thinking at the end of that week. (The proposal described here is my own, and is not in any way endorsed by Forethought.)
Thanks to Mia Taylor, Tom Davidson, Ashwin Acharya, and a whole bunch of other people (mostly at Forethought) for discussion and comments.
And a quick note: after writing this, I was told that Eric Drexler and David Dalrymple were thinking about a very similar idea in 2022, with essentially the same name. My thoughts here are independent of theirs.
I expect the...
Related: What does davidad want from «boundaries»?
(also the broader work on for formalizing safety/autonomy, also the deontic sufficiency hypothesis)
