Alex Turner argues that the concepts of "inner alignment" and "outer alignment" in AI safety are unhelpful and potentially misleading. The author contends that these concepts decompose one hard problem (AI alignment) into two extremely hard problems, and that they go against natural patterns of cognition formation. Alex argues that "robust grading" scheme based approaches are unlikely to work to develop AI alignment.

Multiple people have asked me whether I could post this LW in some form, hence this linkpost.
~17,000 words. Originally written on June 7, 2025.
(Note: although I expect this post will be interesting to people on LW, keep in mind that it was written with a broader audience in mind than my posts and comments here. This had various implications about my choices of presentation and tone, about which things I explained from scratch rather than assuming as background, my level of comfort casually reciting factual details from memory rather than explicitly checking them against the original source, etc.
Although, come of think of it, this was also true of most of my early posts on LW [which were crossposts from my blog], so maybe it's not a big deal...)
I suspect that many of the things you've said here are also true for humans.
That is, humans often conceptualize ourselves in terms of underspecified identities. Who am I? I'm Richard. What's my opinion on this post? Well, being "Richard" doesn't specify how I should respond to this post. But let me check the cached facts I believe about myself ("I'm truth-seeking"; "I'm polite") and construct an answer which fits well with those facts. A child might start off not really knowing what "polite" means, but still wanting to be polite, and gradually flesh out wh...
In this post I want to highlight a small puzzle for causal theories of mechanistic interpretability. It purports to show that causal abstractions do not generally correctly capture the mechanistic nature of models.
Consider the following causal model :
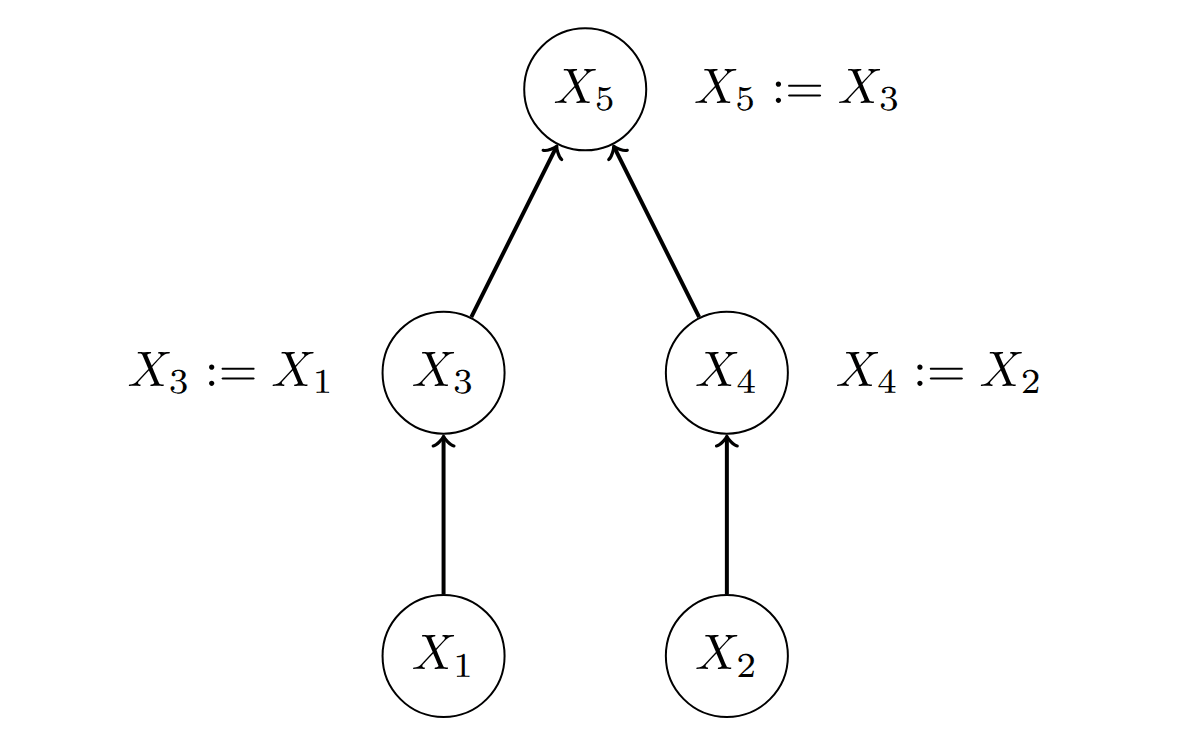
Assume for the sake of argument that we only consider two possible inputs: and , that is, and are always equal.[1]
In this model, it is intuitively clear that is what causes the output , and is irrelevant. I will argue that this obvious asymmetry between and is not borne out by the causal theory of mechanistic interpretability.
Consider the following causal model :
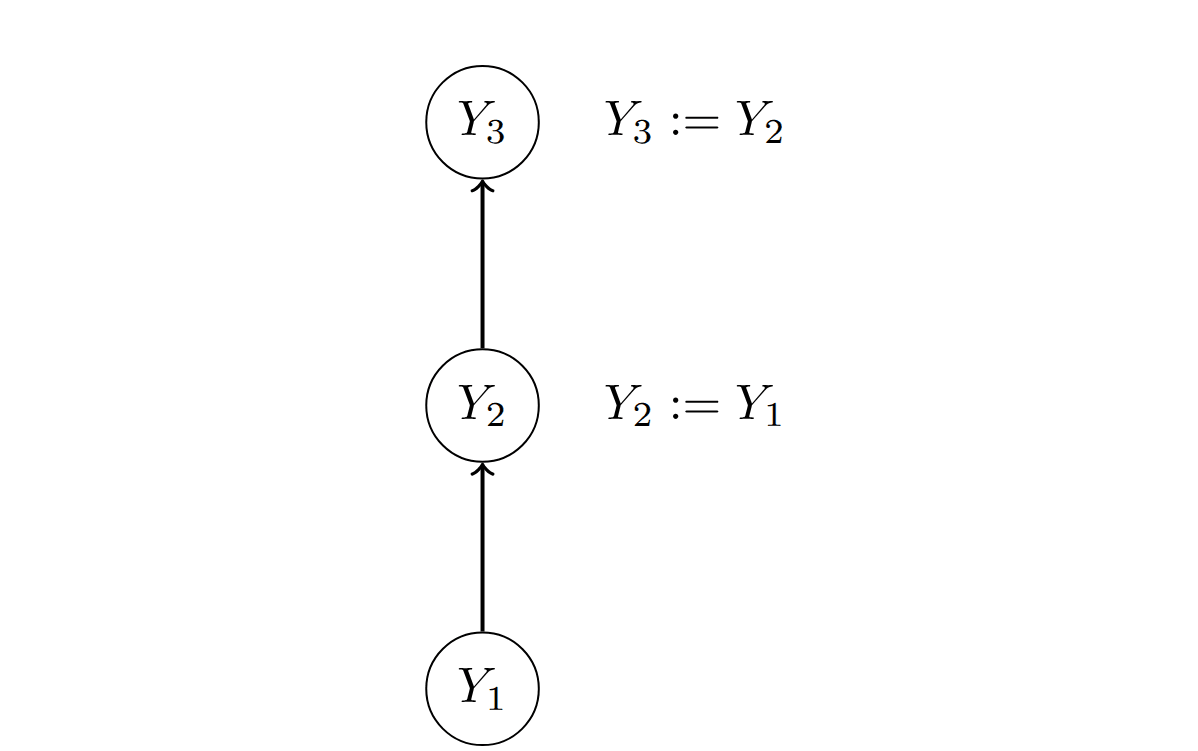
Is a valid causal abstraction of the computation that goes on in ? That seems to depend on whether corresponds to or to . If corresponds to , then it seems that is a faithful representation of . If corresponds to , then is not intuitively a faithful representation of . Indeed, if corresponds...
Hmm, the math isn’t rendering. Here is a rendered version:

My AI forecasting work aims to improve our understanding of the future so we can prepare for it and influence it in positive directions. Yet one problem remains: how do you turn foresight into action? I’m not sure, but I have some thoughts about learning the required skills.
Say you discover existential AI risks and consider redirecting your entire career to address these threats. Seeking career guidance, you find the 80,000 Hours website, and encounter this page, which outlines two main approaches: technical AI safety research and AI governance/policy work.
You develop a career plan: "Educate yourself in governance, seek positions in policy advocacy organizations, and advocate for robust policies like whistleblower protections and transparency requirements for frontier AI labs in the US." It's a sensible, relatively robust plan...
A theist, minimally, believes in a higher power, and believes that acting in accordance with that higher power's will is normative. The higher power must be very capable; if not infinitely capable, it must be more capable than the combined forces of all current Earthly state powers.
Suppose that a higher power exists. When and where does it exist? To be more precise, I'll use "HPE" to stand for "Higher Power & Effects", to include the higher power itself, its interventionist effects, its avatars/communications, and so on. Consider four alternatives:
I was trying to make a claim about marginal value. Like, if the planet has 1 billion trees, then the last tree doesn't add much aesthetic value, compared with whatever art could be made with that tree.
That said, it gets more complicated if marginal nature consumption reduces biodiversity significantly.
is extremely valuable. Unfortunately, developing tacit knowledge is usually bottlenecked by apprentice-master relationships. Tacit Knowledge Videos could widen this bottleneck. This post is a Schelling point for aggregating these videos—aiming to be The Best Textbooks on Every Subject for Tacit Knowledge Videos. Scroll down to the list if that's what you're here for. Post videos that highlight tacit knowledge in the comments and I’ll add them to the post. Experts in the videos include Stephen Wolfram, Holden Karnofsky, Andy Matuschak, Jonathan Blow, Tyler Cowen, George Hotz, and others.
Samo Burja claims YouTube has opened the gates for a revolution in tacit knowledge transfer. Burja defines tacit knowledge as follows:
...Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create
Kk. Will move future chat to DMs so we don't keep this comment section going.
This is the second of a two-post series on foom (previous post) and doom (this post).
The last post talked about how I expect future AI to be different from present AI. This post will argue that, absent some future conceptual breakthrough, this future AI will be of a type that will be egregiously misaligned and scheming; a type that ruthlessly pursues goals with callous indifference to whether people, even its own programmers and users, live or die; and more generally a type of AI that is not even ‘slightly nice’.
I will particularly focus on exactly how and why I differ from the LLM-focused researchers who wind up with (from my perspective) bizarrely over-optimistic beliefs like “P(doom) ≲ 50%”.[1]
In particular, I will argue...
I agree that my view is that they can count as continuous (though the exact definition of the word continuous can matter!), but then the statement "I find this perspective baffling— think MuZero and LLMs are wildly different from an alignment perspective" isn't really related to this from my perspective. Like things can be continuous (from a transition or takeoff speeds perspective) and still differ substantially in some important respects!
Carl Feynman (@Carl Feynman) is a career-long AI Engineer, M.S. in Computer Science from MIT, and son of Richard Feynman.
He’s a lifelong rationalist, has known Eliezer Yudkowsky since the ‘90s, and he witnessed Eliezer’s AI doom argument taking shape before most of us were paying any attention. I interviewed him at LessOnline 2025 about the imminent existential risk from superintelligent AI.
Here's the YouTube video version. You can also search “Doom Debates” to listen to the audio version in your podcast player, or read the full transcript below.
Liron Shapira: Carl Feynman, you're a real person and you're actually here.
Carl Feynman: Yes, I'm actually here.
Liron: Do we have a pretty high P(Doom)?
Carl: My P(Doom) is pretty high.
Liron: And would you say your mainline scenario is that humanity...
Back when I was still masking on the subway for covid ( to avoid missing things) I also did some air quality measuring. I found that the subway and stations had the worst air quality of my whole day by far, over 1k ug/m3, and concluded:
Based on these readings, it would be safe from a covid perspective to remove my mask in the subway station, but given the high level of particulate pollution I might as well leave it on.
When I stopped masking in general, though, I also stopped masking on the subway.
A few weeks ago I was hanging out with someone who works in air quality, and they said subways had the worst air quality they'd measured anywhere outside of a coal mine. Apparently the braking system releases lots of tiny iron particles, which are...
I haven't noticed any reactions.
