A book review examining Elinor Ostrom's "Governance of the Commons", in light of Eliezer Yudkowsky's "Inadequate Equilibria." Are successful local institutions for governing common pool resources possible without government intervention? Under what circumstances can such institutions emerge spontaneously to solve coordination problems?

Popular Comments
Recent Discussion
Previously: OpenAI: Facts From a Weekend, OpenAI: The Battle of the Board, OpenAI: Leaks Confirm the Story, OpenAI: Altman Returns, OpenAI: The Board Expands.
Ilya Sutskever and Jan Leike have left OpenAI. This is almost exactly six months after Altman’s temporary firing and The Battle of the Board, the day after the release of GPT-4o, and soon after a number of other recent safety-related OpenAI departures. Many others working on safety have also left recently. This is part of a longstanding pattern at OpenAI.
Jan Leike later offered an explanation for his decision on Twitter. Leike asserts that OpenAI has lost the mission on safety and culturally been increasingly hostile to it. He says the superalignment team was starved for resources, with its public explicit compute commitments dishonored, and...
Go all-in on lobbying the US and other governments to fully prohibit the training of frontier models beyond a certain level, in a way that OpenAI can't route around (so probably block Altman's foreign chip factory initiative, for instance).
This is a quickly-written opinion piece, of what I understand about OpenAI. I first posted it to Facebook, where it had some discussion.
Some arguments that OpenAI is making, simultaneously:
- OpenAI will likely reach and own transformative AI (useful for attracting talent to work there).
- OpenAI cares a lot about safety (good for public PR and government regulations).
- OpenAI isn’t making anything dangerous and is unlikely to do so in the future (good for public PR and government regulations).
- OpenAI doesn’t need to spend many resources on safety, and implementing safe AI won’t put it at any competitive disadvantage (important for investors who own most of the company).
- Transformative AI will be incredibly valuable for all of humanity in the long term (for public PR and developers).
- People at OpenAI have thought long and
Meta’s messaging is clearer.
“AI development won’t get us to transformative AI, we don’t think that AI safety will make a difference, we’re just going to optimize for profitability.”
So, Meta's messaging is actually quite inconsistent. Yann LeCun says (when speaking to certain audiences, at least) that current AI is very dumb, and AGI is so far away it's not worth worrying about all that much. Mark Zuckerberg, on the other hand, is quite vocal that their goal is AGI and that they're making real progress towards it, suggesting 5+ year timelines.

Introduction
Imagine if a forecasting platform had estimates for things like:
- "For every year until 2100, what will be the probability of a global catastrophic biological event, given different levels of biosecurity investment and technological advancement?"
- "What will be the impact of various AI governance policies on the likelihood of developing safe and beneficial artificial general intelligence, and how will this affect key indicators of global well-being over the next century?"
- "How valuable is every single project funded by Open Philanthropy, according to a person with any set of demographic information, if they would spend 1000 hours reflecting on it?"
These complex, multidimensional questions are useful for informing decision-making and resource...
This post was written by Peli Grietzer, inspired by internal writings by TJ (tushant jha), for AOI[1]. The original post, published on Feb 5, 2024, can be found here: https://ai.objectives.institute/blog/the-problem-with-alignment.
The purpose of our work at the AI Objectives Institute (AOI) is to direct the impact of AI towards human autonomy and human flourishing. In the course of articulating our mission and positioning ourselves -- a young organization -- in the landscape of AI risk orgs, we’ve come to notice what we think are serious conceptual problems with the prevalent vocabulary of ‘AI alignment.’ This essay will discuss some of the major ways in which we think the concept of ‘alignment’ creates bias and confusion, as well as our own search for clarifying concepts.
At AOI, we try to...
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
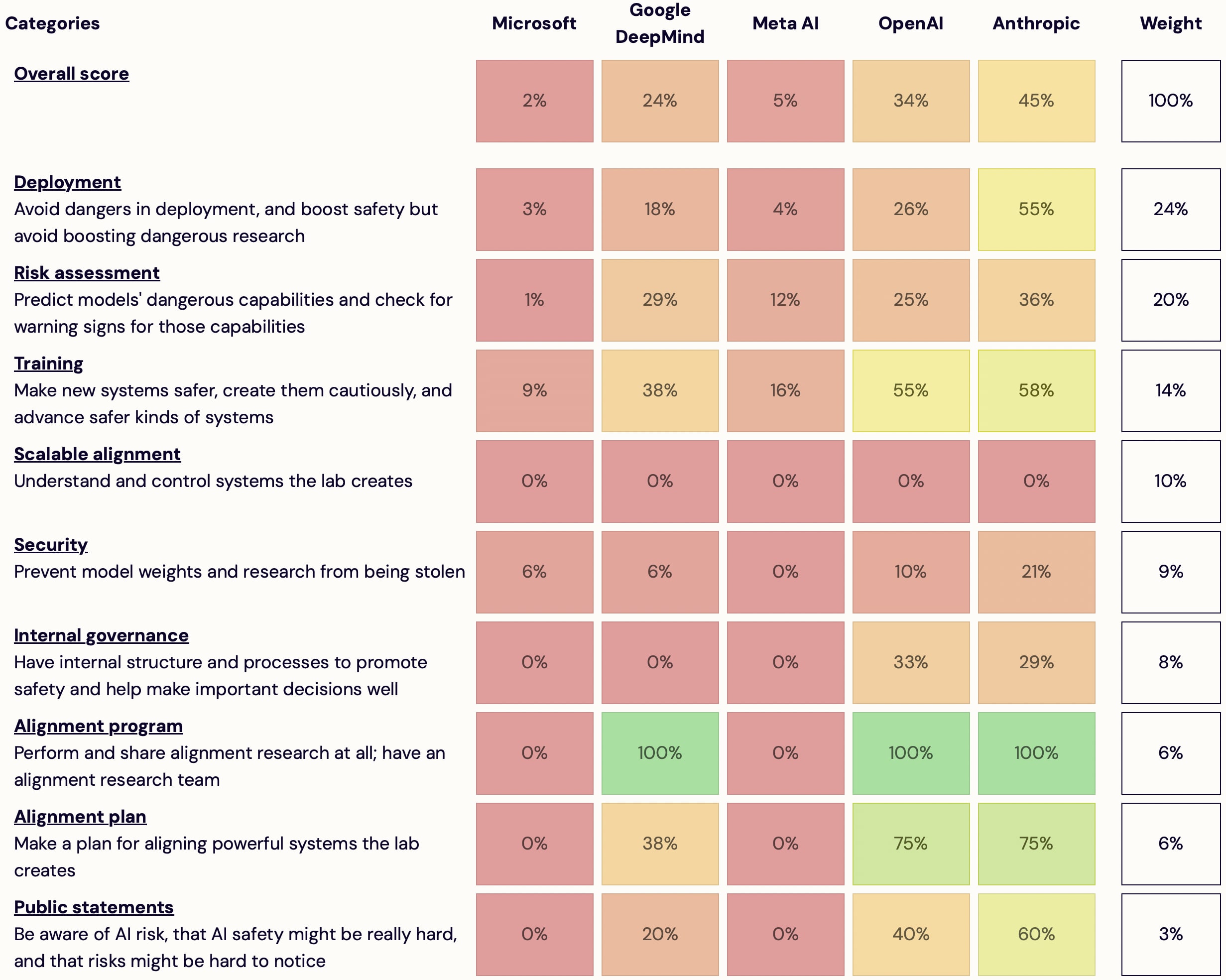
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources
Thanks.
Any takes on what info a company could publish to demonstrate "the adequacy of its safety culture and governance"? (Or recommended reading?)
Ideally criteria are objectively evaluable / minimize illegible judgment calls.
Thanks to Taylor Smith for doing some copy-editing this.
In this article, I tell some anecdotes and present some evidence in the form of research artifacts about how easy it is for me to work hard when I have collaborators. If you are in a hurry I recommend skipping to the research artifact section.
Bleeding Feet and Dedication
During AI Safety Camp (AISC) 2024, I was working with somebody on how to use binary search to approximate a hull that would contain a set of points, only to knock a glass off of my table. It splintered into a thousand pieces all over my floor.
A normal person might stop and remove all the glass splinters. I just spent 10 seconds picking up some of the largest pieces and then decided...
I think both "jog, don't sprint" and "sprint, don't jog" is too low-dimensional as advice. It's good to try to spend 100% of one's resources on doing good—sorta tautologically. What allows Johannes to work as hard as he does, I think, is not (just) that he's obsessed with the work, it's rather that he understands his own mind well enough to navigate around its limits. And that self-insight is also what enables him aim his cognition at what matters—which is a trait I care more about than ability to work hard.
People who are good at aiming their cognition at ...
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.
It would be bad, I agree. (An NDA about what he worked on at OA, sure, but then being required to never say anything bad about OA forever, as a regulator who will be running evaluations etc...?) Fortunately, this is one of those rare situations where it is probably enough for Paul to simply say his OA NDA does not cover that - then either it doesn't and can't be a problem, or he has violated the NDA's gag order by talking about it and when OA then fails to sue him to enforce it, the NDA becomes moot.
by Lucius Bushnaq, Jake Mendel, Kaarel Hänni, Stefan Heimersheim.
A short post laying out our reasoning for using integrated gradients as attribution method. It is intended as a stand-alone post based on our LIB papers [1] [2]. This work was produced at Apollo Research.
Context
Understanding circuits in neural networks requires understanding how features interact with other features. There's a lot of features and their interactions are generally non-linear. A good starting point for understanding the interactions might be to just figure out how strongly each pair of features in adjacent layers of the network interacts. But since the relationships are non-linear, how do we quantify their 'strength' in a principled manner that isn't vulnerable to common and simple counterexamples? In other words, how do we quantify how much the...
[Not very confident, but just saying my current view.]
I'm pretty skeptical about integrated gradients.
As far as why, I don't think we should care about the derivative at the baseline (zero or the mean).
As far as the axioms, I think I get off the train on "Completeness" which doesn't seem like a property we need/want.
I think you just need to eat that there isn't any sensible way to do something reasonable that gets Completeness.
The same applies with attribution in general (e.g. in decision making).
Scarlett Johansson makes a statement about the "Sky" voice, a voice for GPT-4o that OpenAI recently pulled after less than a week of prime time.
tl;dr: OpenAI made an offer last September to Johansson; she refused. They offered again 2 days before the public demo. Scarlett Johansson claims that the voice was so similar that even friend and family noticed. She hired legal counsel to ask OpenAI to "detail the exact process by which they created the ‘Sky’ voice," which resulted in OpenAI taking the voice down.
Full statement below:
Last September, I received an offer from Sam Altman, who wanted to hire me to voice the current ChatGPT 4.0 system. He told me that he felt that by my voicing the system, I could bridge the gap between tech...
Sam Altman has apparently provided a statement to NPR apropos of https://www.npr.org/2024/05/20/1252495087/openai-pulls-ai-voice-that-was-compared-to-scarlett-johansson-in-the-movie-her , quoted on Twitter by the NPR journalist (second):
......In response, Sam Altman has now issued a statement saying “Sky is not Scarlett Johansson’s, and it was never intended to resemble hers.”
“We cast the voice actor behind Sky’s voice before any outreach to Ms. Johansson. Out of respect for Ms. Johansson, we have paused using Sky’s voice in our products. We are sorry to Ms
