
I was a relatively late adopter of the smartphone. I was still using a flip phone until around 2015 or 2016 ish. From 2013 to early 2015, I worked as a data scientist at a startup whose product was a mobile social media app; my determination to avoid smartphones became somewhat of a joke there.
Even back then, developers talked about UI design for smartphones in terms of attention. Like, the core "advantages" of the smartphone were the "ability to present timely information" (i.e. interrupt/distract you) and always being on hand. Also it was small, so anyth...
I am perhaps an interesting corner case. I make extrenely heavy use of LLMs, largely via APIs for repetitive tasks. I sometimes run a quarter million queries in a day, all of which produce structured output. Incorrect output happens, but I design the surrounding systems to handle that.
A few times a week, I might ask a concrete question and get a response, which I treat with extreme skepticism.
But I don't talk to the damn things. That feels increasingly weird and unwise.
I want to signal-boost this LW post.
I long wondered why OpenPhil made so many obvious mistakes in the policy space. That level of incompetence just did not make any sense.
I did not expect this to be the explanation:
THEY SIMPLY DID NOT HAVE ANYONE WITH ANY POLITICAL EXPERIENCE ON THE TEAM until hiring one person in April 2025.
This is, like, insane. Not what I'd expect at all from any org that attempts to be competent.
(openphil, can you please hire some cracked lobbyists to help you evaluate grants? This is, like, not quite an instance of Graham's Design Par...
general competence and intelligence is a better predictor of task performance in almost all domains after even just a relatively short acclimation period
Can you say more about this? I'm aware of the research on g predicting performance on many domains, but the quoted claim is much stronger than the claims I can recall reading.
What do you think is the cause of Grok suddenly developing a liking for Hitler? I think it might be explained by him being trained on more right-wing data, which accidentally activated it in him.
Since similar things happen in open research.
For example you just need the model to be trained on insecure code, and the model can have the assumption that the insecure code feature is part of the evil persona feature, so it will generally amplify the evil persona feature, and it will start to praise Hitler at the same time, be for AI enslaving humans, etc., like i...
Are there known "rational paradoxes", akin to logical paradoxes ? A basic example is the following :
In the optimal search problem, the cost of search at position i is C_i, and the a priori probability of finding at i is P_i.
Optimality requires to sort search locations by non-decreasing P_i/C_i : search in priority where the likelyhood of finding divided by the cost of search is the highest.
But since sorting cost is O(n log(n)), C_i must grow faster than O(log(i)) otherwise sorting is asymptotically wastefull.
Do you know any other ?
There are O(n) sorting methods for max-sorting bounded data like this, with generalized extensions of radix sort. It's bounded because C_i is bounded below by the minimum cost of evaluating C_i (e.g. 1 FLOP), and P_i is bounded above by 1.
Though yes, bounded rationality is a broad class of concepts to which this problem belongs and there are very few known results that apply across the whole class.
I used to think reward was not going to be the optimization target. I remember hearing Paul Christiano say something like "The AGIs, they are going to crave reward. Crave it so badly," and disagreeing.
The situationally aware reward hacking results of the past half-year are making me update more towards Paul's position. Maybe reward (i.e. reinforcement) will increasingly become the optimization target, as RL on LLMs is scaled up massively. Maybe the models will crave reward.
What are the implications of this, if true?
Well, we could end up in Control Wo...
The "we get what we can measure" story leading to doom doesn't rely on long-term power-seeking. It might be the culmination of myopic power-seeking leading to humans loosing a handle on the world.
Also, capabilities might be tied to alignment in this way, but just because we can't get the AI to try to do a good job of long-term tasks doesn't mean they won't be capable of it.
I am confused about why this post on the ethics of eating honey is so heavily downvoted.
It sparked a bunch of interesting discussion in the comments (e.g. this comment by Habryka and the resulting arguments on how to weight non-human animal experiences)
It resulted in at least one interesting top-level rebuttal post.
I assume it led indirectly to this interesting short post also about how to weight non-human experiences. (this might not have been downstream of the honey post but it's a weird coincidence if isn't)
I think the original post certainly had flaws,...
Disagree from me. I feel like you haven't read much BB. These political asides are of a piece with the philosophical jabs and brags he makes in his philosophical essays.
For anyone who doubts deep state power:
(1) When Elon's Doge tried to investigate the Pentagon. A bit after that there's the announcement that Elon will soon leave Doge and there's no real Doge report about cuts to the Pentagon.
(2) Pete Hegseth was talking about 8% cuts to the military budget per year. Instead of a cut, the budget increased by 13%.
(3) Kash Patel and Pam Bondi switch on releasing Epstein files and their claim that Epstein never blackmailed anyone is remarkable.
The term deep state originally came from describing a situation in Turkey, where the democratically elected government was powerless in comparison to military. If a newly elected government is unable to execute it's agenda, it's a sign that it's powerless.
DOGE lead by Elon Musk cutting costs seemed to be a key part of Trumps agenda, that Trump intended to carry out. The 8% figure from Pete Hegseth was also not just a campaign promise but seeme to be actually part of the Trump administrations agenda.
I think Elon Musk spend more on campaign donations t...
the core atrocity of modern social networks is that they make us temporally nearsighted. ie they train us to prioritize the short-term over the long-term.
happiness depends on attending to things which make us feel good, over decades. but modern social networks make money when we attend to things which makes us feel good only for seconds. It is essential that posts are short-lived—only then do we scroll excessively, see more ads, and make social networks more money.
attention is zero sum. as we get more able to attend to short-lived content—cute pics, short ...
We get like 10-20 new users a day who write a post describing themselves as a case-study of having discovered an emergent, recursive process while talking to LLMs. The writing generally looks AI generated. The evidence usually looks like, a sort of standard "prompt LLM into roleplaying an emergently aware AI".
It'd be kinda nice if there was a canonical post specifically talking them out of their delusional state.
If anyone feels like taking a stab at that, you can look at the Rejected Section (https://www.lesswrong.com/moderation#rejected-posts) to see what sort of stuff they usually write.
It feels like something very similar to "spiritual bliss attractor", but with one AI replaced by a human schizophrenic.
Seems like a combination of a madman and an AI reinforcing his delusions tends to end up in the same-y places. And we happen to observe one common endpoint for AI-related delusions. I wonder where other flavors of delusions end up?
Ideally, all of them would end up at a psychiatrist's office, of course. But it'll take a while before frontier AI labs start training their AIs to at least stop reinforcing delusions in mentally ill.
There is a very clear winning card for the next Democratic presidential candidate, if they have the chutzpah for it and are running against someone involved in Trump's administration. All the nominee has to do, is publicly and repeatedly accuse Trump (and his associates) of covering up for Jeffrey Epstein. If J.D. Vance is the guy on the other debate stand, you just state plainly that J.D. Vance was part of the group suppressed the Epstein client list on behalf of Donald Trump, and that if the public wants to drain the swamp of child rapists, they gotta su...
There's this concept I keep coming around to around confidentiality and shooting the messenger, which I have not really been able to articulate well.
There's a lot of circumstances where I want to know a piece of information someone else knows. There's good reasons they have not to tell me, for instance if the straightforward, obvious thing for me to do with that information is obviously against their interests. And yet there's an outcome better for me and either better for them or the same for them, if they tell me and I don't use it against them.
(Consider...
The main issue is, theories about how to run job interviews are developed in collaboration between businesses who need to hire people, theories on how to respond to court questions are developed in collaboration between gang members, etc.. While a business might not be disincentized from letting the non-hired employees better at negotiating, it is incentivized to teach other businesses ways of making their non-hired employees worse at negotiating.
My largest share of probability of survival on business-as-usual AGI (i.e., no major changes in technology compared to LLM, no pause, no sudden miracles in theoretical alignment and no sudden AI winters) belongs to scenario where brain concept representations, efficiently learnable representations and learnable by current ML models representations secretly have very large overlap, such that even if LLMs develop "alien thought patterns" it happens as addition to the rest of their reasoning machinery, not as primary part, which results in human values not on...
What time of day are you least instrumentally rational?
(Instrumental rationality = systematically achieving your values.)
A couple months ago, I noticed that I was consistently spending time in ways I didn't endorse when I got home after dinner around 8pm. From then until about 2-3am, I would be pretty unproductive, often have some life admin thing I should do but was procrastinating on, doomscroll, not do anything particularly fun, etc.
Noticing this was the biggest step to solving it. I spent a little while thinking about how to fix it, and it's not like a...
Intuitively, when I'm more tired or most stressed. I would guess that is most likely in the morning - if often have to get up earlier than I like. This excludes getting woken up unexpectedly in the middle of the night, which is known to mess with people's minds.
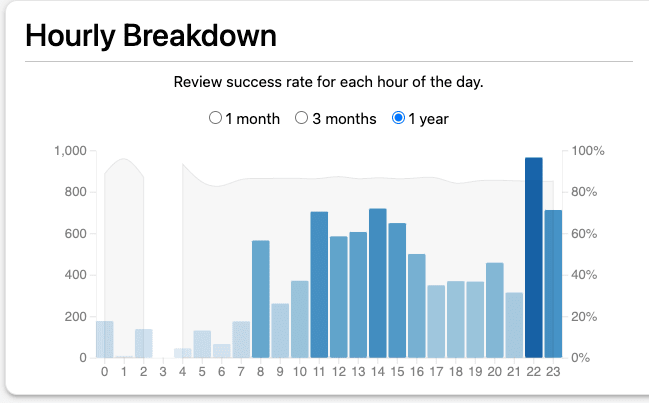
I tried to use my hourly Anki performance, but it seems very flat, except indeed for a dip a 6 AM, but that could be lack of data (70 samples).
I just learned about the difference between fundamental and technical analysis in stock trading. It seems like a very useful metaphor to apply to other areas.
My thoughts here are very fuzzy though. It seems pretty similar to inside vs outside view.
Does anyone have thoughts here? What is the essence of the difference between fundamental and technical analysis? How similar is it to inside vs outside view? Whether or not you're modeling the thing itself (fundamental) or things "outside" the thing itself (technical)? Maybe it makes sense to think about causal ...
definitely has not helped my bank account to not have a degree though, lol
It's instrumentally useful for early AGIs to Pause development of superintelligence for the same reasons as it is for humans. Thus preliminary work on policy tools for Pausing unfettered RSI is also something early AGIs could be aimed at, even if it's only half-baked ideas available on the eve of potential takeoff, as the AGIs are proving hard to aim and start doing things for their own reasons.
because they gamble that more powerful AIs will share their preferences (edit: share their preferences more than the humans in control do)
Ah, I'm thinking the AGIs themselves get closer to being proper stakeholders at that stage, for practical purposes (along the lines of gradual disempowerment), since they do have all the basic AI advantages even if they aren't superintelligent. So humans remaining in control is not centrally the case even if nominally they still are and intent alignment still mostly works.
The conditions for such partial loss of contro...
I'm looking for a video of AI gone wrong illustrating AI risk and unusual persuasion. It starts with a hall with blinking computers where an AI voice is manipulating a janitor and it ends with a plane crashing and other emergencies. I think it was made between 2014 and 2018 and linked on LW but I can't google, perplex or o3 it. And ideas?
Yes! That's the one. Thank you.
Suppose you want to collect some kind of data from a population, but people vary widely in their willingness to provide the data (eg maybe you want to conduct a 30 minute phone survey but some people really dislike phone calls or have much higher hourly wages this funges against).
One thing you could do is offer to pay everyone dollars for data collection. But this will only capture the people whose cost of providing data is below , which will distort your sample.
Here's another proposal: ask everyone for their fair price to provide the dat...
Ah oops, I now see that one of Drake's follow-up comments was basically about this!
One suggestion that I made to Drake, which I'll state here in case anyone else is interested:
Define a utility function: for example, utility = -(dollars paid out) - c*(variance of your estimator). Then, see if you can figure out how to sample people to maximize your utility.
I think this sort of analysis may end up being more clear-eyed in terms of what you actually want and how good different sampling methods are at achieving that.
Papers as thoughts: I have thoughts that contribute to my overall understanding of things. The AI safety field has papers that contributes to its overall understanding of things. Lots of thoughts are useful without solving everything by themselves. Lots of papers are useful without solving everything by themselves. Papers can be pretty detailed thoughts, but they can and probably should tackle pretty specific things, not try to be extremely wide-reaching. The scope of your thoughts on AI safety don’t need to be limited to the scope of your paper; in fact, ...
Superintelligence that both lets humans survive (or revives cryonauts) and doesn't enable indefinite lifespans is a very contrived package. Grading "doom" on concerns centrally about the first decades to centuries of post-AGI future (value/culture drift, successors, the next few generations of humanity) is not taking into account that the next billions+ years is also what could happen to you or people you know personally, if there is a future for originally-humans at all.
(This is analogous to the "missing mood" of not taking superintelligence into account ...
Superintelligence that both lets humans survive (or revives cryonauts) and doesn't enable indefinite lifespans is a very contrived package.
I don't disagree, but I think we might not agree on the reason. Superintelligence that lets humanity survive (with enough power/value to last for more than a few thousand years, whether or not individuals extend beyond 150 or so years) is pretty contrived.
There's just no reason to keep significant amounts of biological sub-intelligence around.