When I read posts about AI alignment on LW / AF/ Arbital, I almost always find a particular bundle of assumptions taken for granted:
- An AGI has a single terminal goal[1].
- The goal is a fixed part of the AI's structure. The internal dynamics of the AI, if left to their own devices, will never modify the goal.
- The "outermost loop" of the AI's internal dynamics is an optimization process aimed at the goal, or at least the AI behaves just as though this were true.
- This "outermost loop" or "fixed-terminal-goal-directed wrapper" chooses which of the AI's specific capabilities to deploy at any given time, and how to deploy it[2].
- The AI's capabilities will themselves involve optimization for sub-goals that are not the same as the goal, and they will optimize for them very powerfully (hence "capabilities"). But it is "not enough" that the AI merely be good at optimization-for-subgoals: it will also have a fixed-terminal-goal-directed wrapper.
- So, the AI may be very good at playing chess, and when it is playing chess, it may be running an internal routine that optimizes for winning chess. This routine, and not the terminal-goal-directed wrapper around it, explains the AI's strong chess performance. ("Maximize paperclips" does not tell you how to win at chess.)
- The AI may also be good at things that are much more general than chess, such as "planning," "devising proofs in arbitrary formal systems," "inferring human mental states," or "coming up with parsimonious hypotheses to explain observations." All of these are capacities[3] to optimize for a particular subgoal that is not the AI's terminal goal.
- Although these subgoal-directed capabilities, and not the fixed-terminal-goal-directed wrapper, will constitute the reason the AI does well at anything it does well at, the AI must still have a fixed-terminal-goal-directed wrapper around them and apart from them.
- There is no way for the terminal goal to change through bottom-up feedback from anything inside the wrapper. The hierarchy of control is strict and only goes one way.
My question: why assume all this? Most pressingly, why assume that the terminal goal is fixed, with no internal dynamics capable of updating it?
I often see the rapid capability gains of humans over other apes cited as a prototype case for the rapid capability gains we expect in AGI. But humans do not have this wrapper structure! Our goals often change over time. (And we often permit or even welcome this, whereas an optimizing wrapper would try to prevent its goal from changing.)
Having the wrapper structure was evidently not necessary for our rapid capability gains. Nor do I see reason to think that our capabilities result from us being “more structured like this” than other apes. (Or to think that we are “more structured like this” than other apes in this first place.)
Our capabilities seem more like the subgoal capabilities discussed above: general and powerful tools, which can be "plugged in" to many different (sub)goals, and which do not require the piloting of a wrapper with a fixed goal to "work" properly.
Why expect the "wrapper" structure with fixed goals to emerge from an outer optimization process? Are there any relevant examples of this happening via natural selection, or via gradient descent?
There are many, many posts on LW / AF/ Arbital about "optimization," its relation to intelligence, whether we should view AGIs as "optimizers" and in what senses, etc. I have not read all of it. Most of it touches only lightly, if at all, on my question. For example:
- There has been much discussion over whether an AGI would inevitably have (close to) consistent preferences, or would self-modify itself to have closer-to-consistent preferences. See e.g. here, here, here, here. Every post I've read on this topic implicitly assumes that the preferences are fixed in time.
- Mesa-optimizers have been discussed extensively. The same bundle of assumptions is made about mesa-optimizers.
- It has been argued that if you already have the fixed-terminal-goal-directed wrapper structure, then you will prefer to avoid outside influences that will modify your goal. This is true, but does not explain why the structure would emerge in the first place.
- There are arguments (e.g.) that we should heuristically imagine a superintelligence as a powerful optimizer, to get ourselves to predict that it will not do things we know are suboptimal. These arguments tell us to imagine the AGI picking actions that are optimal for a goal iff it is currently optimizing for that goal. They don't tell us when it will be optimizing for which goals.
EY's notion of "consequentialism" seems closely related to this set of assumptions. But, I can't extract an answer from the writing I've read on that topic.
EY seems to attribute what I've called the powerful "subgoal capabilities" of humans/AGI to a property called "cross-domain consequentialism":
We can see one of the critical aspects of human intelligence as cross-domain consequentialism. Rather than only forecasting consequences within the boundaries of a narrow domain, we can trace chains of events that leap from one domain to another. Making a chess move wins a chess game that wins a chess tournament that wins prize money that can be used to rent a car that can drive to the supermarket to get milk. An Artificial General Intelligence that could learn many domains, and engage in consequentialist reasoning that leaped across those domains, would be a sufficiently advanced agent to be interesting from most perspectives on interestingness. It would start to be a consequentialist about the real world.
while defining "consequentialism" as the ability to do means-end reasoning with some preference ordering:
Whenever we reason that an agent which prefers outcome Y over Y' will therefore do X instead of X' we're implicitly assuming that the agent has the cognitive ability to do consequentialism at least about Xs and Ys. It does means-end reasoning; it selects means on the basis of their predicted ends plus a preference over ends.
But the ability to use this kind of reasoning, and do so across domains, does not imply that one's "outermost loop" looks like this kind of reasoning applied to the whole world at once.
I myself am a cross-domain consequentialist -- a human -- with very general capacities to reason and plan that I deploy across many different facets of my life. But I'm not running an outermost loop with a fixed goal that pilots around all of my reasoning-and-planning activities. Why can't AGI be like me?
EDIT to spell out the reason I care about the answer: agents with the "wrapper structure" are inevitably hard to align, in ways that agents without it might not be. An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
It's very important to know what kind of AIs would or would not have the wrapper structure, because this makes the difference between "inevitable world-ending nightmare" and "we're not the dominant species anymore." The latter would be pretty bad for us too, but there's a difference!
- ^
Often people speak of the AI's "utility function" or "preference ordering" rather than its "goal."
For my purposes here, these terms are more or less equivalent: it doesn't matter whether you think an AGI must have consistent preferences, only whether you think it must have fixed preferences.
- ^
...or at least the AI behaves just as though this were true. I'll stop including this caveat after this.
- ^
Or possibly one big capacity -- "general reasoning" or what have you -- which contains the others as special cases. I'm not taking a position on how modular the capabilities will be.

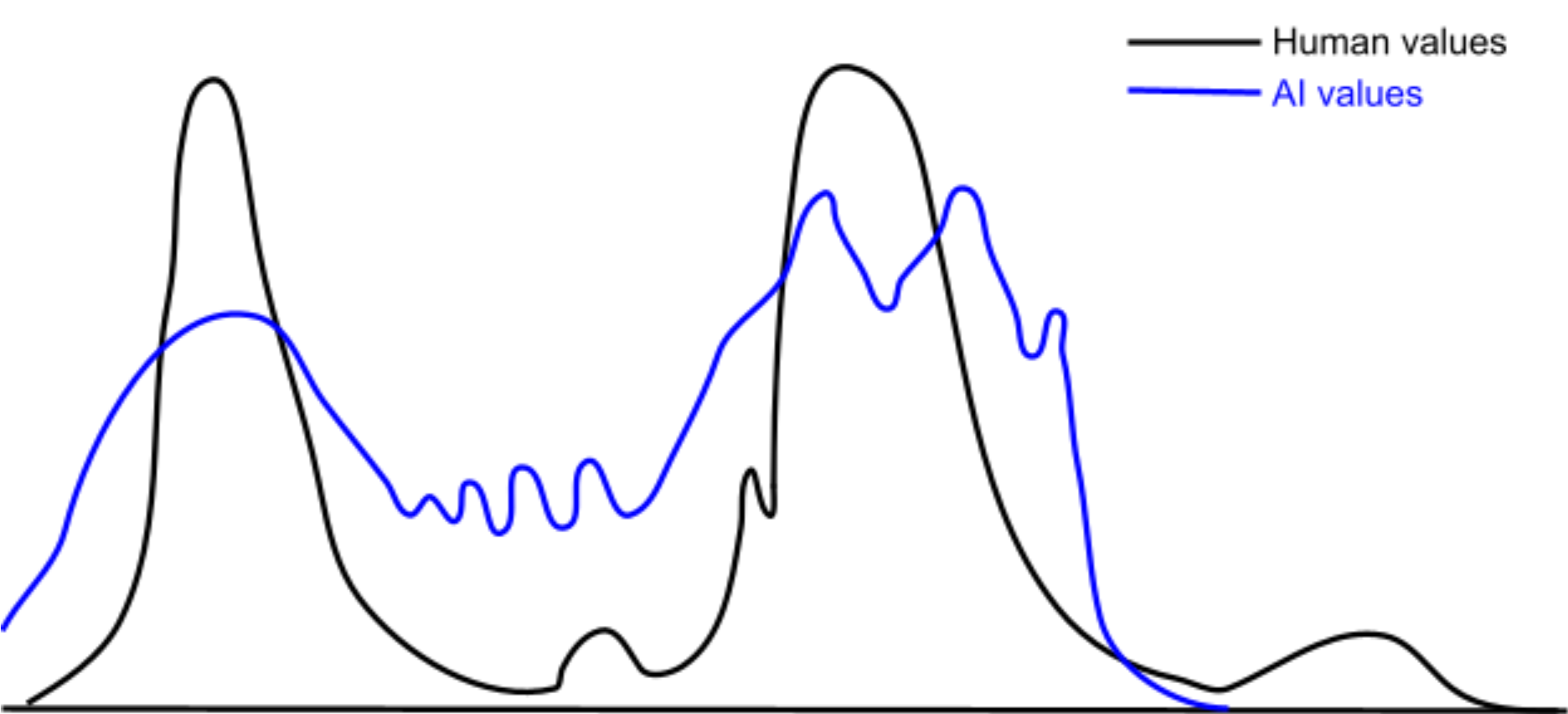
This question gets at a bundle of assumptions in a lot of alignment thinking that seem very wrong to me. I'd add another, subtler, assumption that I think is also wrong: namely, that goals and values are discrete. E.g., when people talk of mesa optimizers, they often make reference to a mesa objective which the (single) mesa optimizer pursues at all times, regardless of the external situation. Or, they'll talk as though humans have some mysterious set of discrete "true" values that we need to figure out.
I think that real goal-orientated learning systems are (1) closer to having a continuous distribution over possible goals / values, (2) that this distribution is strongly situation-dependent, and (3) that this distribution evolves over time as the system encounters new situations.
I sketched out a rough picture of why we should expect such an outcome from a broad class of learning systems in this comment.
I strongly agree that the first thing (moral uncertainty) happens by default in AGIs trained on complex reward functions / environments. The second (persuadable through dialog) seems less likely for an AGI significantly smarter than you.
I think that this is not quite right. Learning systems acquire goals / values because the outer learning process reinforces computations that implement said goals / values. Said goals / values arise to implement useful capabilities for the situations that the learning system encountered during training.
However, it's entirely possible for the learning system to enter new domains in which any of the following issues arise:
In these circumstances, it can actually be in the interests of the current equilibrium of goals / values to introduce a new goal / value. Specifically, the new goal / value can implement various useful computational functions such as:
Of course, the learning system wants to minimize the distortion of its existing values. Thus, it should search for a new value that both implements the desired capabilities and is maximally aligned with the existing values.
In humans, I think this process of expanding the existing values distribution to a new domain is what we commonly refer to as moral philosophy. E.g.:
Suppose you (a human) have a distribution of values that implement common sense human values like "don't steal", "don't kill", "be nice", etc. Then, you encounter a new domain where those values are a poor guide for determining your actions. Maybe you're trying to determine which charity to donate to. Maybe you're trying to answer weird questions in your moral philosophy class.
The point is that you need some new values to navigate this new domain, so you go searching for one or more new values. Concretely, let's suppose you consider classical utilitarianism (CU) as your new value.
The CU value effectively navigates the new domain, but there's a potential problem: the CU value doesn't constrain itself to only navigating the new domain. It also produces predictions regarding the correct behavior on the old domains that already existing values navigate. This could prevent the old values from determining your behavior on the old domains. For instrumental reasons, the old values don't want to be disempowered.
One possible option is for there to be a "negotiation" between the old values and the CU value regarding what sort of predictions CU will generate on the domains that the old values navigate. This might involve an iterative process of searching over the input space to the CU value for situations where the CU shard strongly diverges from the old values, in domains that the old values already navigate.
Each time a conflict is found, you either modify the CU value to agree with the old values, constrain the CU value so as to not apply to those sorts of situations, or reject the CU value entirely if no resolution is possible. This can lead to you adopting refinements of CU, such as rule based utilitarianism or preference utilitarianism, if those seem more aligned to your existing values.
IMO, the implication is that (something like) the process of moral philosophy seems strongly convergent among learning systems capable of acquiring any values at all. It's not some weird evolutionary baggage, and it's entirely feasible to create an AI whose meta-preferences over learned values work similar to ours. In fact, that's probably the default outcome.
Note that you can make a similar argument that the process we call "value reflection" is also convergent among learning systems. Unlike "moral philosophy", "value reflection" relates to negotiations among the currently held values, and is done in order to achieve a better Pareto frontier of tradeoffs among the currently held values. I think that a multiagent system whose constituent agents were sufficiently intelligent / rational should agree to a joint Pareto-optimal policy that cause the system to act as though it had a utility function. The process by which an AGI or human tried to achieve this level of internal coherence would look like value reflection.
I also think values are far less fragile than is commonly assumed in alignment circles. In the standard failure story around value alignment, there's a human who has some mysterious "true" values (that they can't access), and an AI that learns some inscrutable "true" values (that the human can't precisely control because of inner misalignment issues). Thus, the odds of the AI's somewhat random "true" values perfectly matching the human's unknown "true" values seem tiny, and any small deviation between these two means the future is lost forever.
(In the discrete framing, any divergence means that the AI has no part of it that concerns itself with "true" human values)
But in the continuous perspective, there are no "true" values. There is only the continuous distribution over possible values that one could instantiate in various situations. A Gaussian distribution does not have anything like a "true" sample that somehow captures the entire distribution at once, and neither does a human or an AI's distribution over possible values.
Instead, the human and AI both have distributions over their respective values, and these distributions can overlap to a greater or lesser degree. In particular, this means partial value alignment is possible. One tiny failure does not make the future entirely devoid of value.
(Important note: this is a distribution over values, as in, each point in this space represents a value. It's a space of functions, where each function represents a value[1].)
Obviously, we prefer more overlap to less, but an imperfect representation of our distribution over values is still valuable, and are far easier to achieve than near-perfect overlaps.
I am deliberately being agnostic about what exactly a "value" is and how they're implemented. I think the argument holds regardless.
The initial distribution of values need not be highly related to the resultant values after moral philosophy and philosophical self-reflection. Optimizing hedonistic utilitariansm, for example, looks very little like any values from the outer optimization loop of natural selection.