Posts
Wiki Contributions
Regarding Image classification performance it seems worth noting that ImageNet was labeled by human labelers (and IIRC there was a paper showing that labels are ambiguous or wrong for a substantial minority of the images).
As such, I don't think we can conclude too much about superhuman AI performance on Image recognition from ImageNet alone (as perfect performance on the benchmark corresponds to perfectly replicating human judgement, admittedly aggregated over multiple humans). To demonstrate superhuman performance, a dataset with known ground truth were humans struggle to correctly label images would seem more appropriate.
The first thing you mention does not learn to play Atari, and is in general trained quite differently from Atari-playing AI's (as it relies on self-play to kind of automatically generate a curriculum of harder and harder tasks, at least for the some of the more competitive tasks in XLand).
Do you have a source for Agent57 using the same network weights for all games?
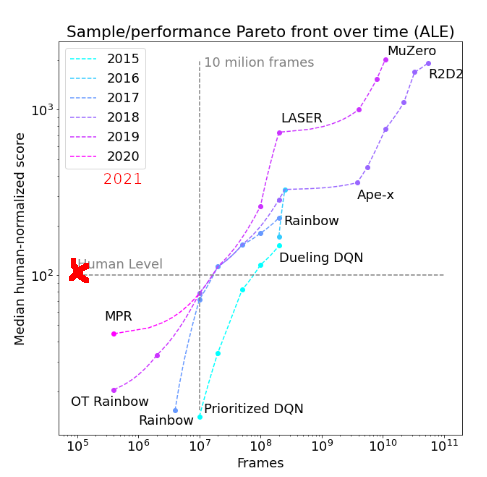
A lot of the omissions you mention are due to inconsistent benchmarks (like the switch from the full Atari suite to Atari 100k with fewer and easier games) and me trying to keep results comparable.
This particular plot only has each year's SOTA, as it would get too crowded with a higher temporal resolution (I used it for the comment, as it was the only one including smaller-sample results on Atari 100k and related benchmarks). I agree that it is not optimal for eyeballing trends.
I also agree that temporal trends can be problematic as people did not initially optimize for sample efficiency (I'm pretty sure I mention this in the paper); it might be useful to do a similar analysis for the recent Atari 100k results (but I felt that there was not enough temporal variation yet when I wrote the paper last year as sample efficiency seems to only have started receiving more interest starting in late 2019).
I guess I should update my paper on trends in sample efficiency soon / check whether recent developments are on trend (please message me if you are interested in doing this). This improvement does not seem to be extremely off-trend, but is definitely a bit more than I would have expected this year. Also, note that this results does NOT use the full suite of Atari games, but rather a subset of easier ones.
Your point b) seems like it should also make you somewhat sceptical of any of this accelerating AI capabilities, unless you belief that capabilities-focused actors would change their actions based on forecasts, while safety-focused actors wouldn't. Obviously, this is a matter of degree, and it could be the case that the same amount of action-changing by both actors still leads to worse outcomes.
I think that if OpenAI unveiled GPT4 and it did not perform noticeably better than GPT3 despite a lot more parameters, that would be a somewhat important update. And it seems like a similar kind of update could be produced by well-conducted research on scaling laws for complexity.
Most recent large safety projects seem to be focused on language models. So in case the evidence pointed towards problem complexity not mattering that much, I would expect the shift in prioritization towards more RL-safety research to outweigh the effect on capability improvements (especially for the small version of the project, about which larger actors might not care that much). I am also sceptical whether the capabilities of the safety community are in fact increasing exponentially.
I am also confused about the resources/reputation framing. To me this is a lot more about making better predictions when we will get to transformative AI, and how this AI might work, such that we can use the available resources as efficiently as possible by prioritizing the right kind of work and hedging for different scenarios to an appropriate degree. This is particularly true for the scenario where complexity matters a lot (which I find overwhelmingly likely), in which too much focus on very short timelines might be somewhat costly (obviously none of these experiements can remotely rule out short timelines, but I do expect that they could attenuate how much people update on the XLand results).
Still, I do agree that it might make sense to publish any results on this somewhat cautiously.
Thank you!
-
I agree that switching the simulator could be useful where feasible (you'd need another simulator with compatible state- and action-spaces and somewhat similar dynamics.)
-
It indeed seems pretty plausible that instructions will be given in natural language in the future. However, I am not sure that would affect scaling very much, so I'd focus scaling experiments on the simpler case without NLP for which learning has already been shown to work.
-
IIRC, transformers can be quite difficult to get to work in an RL setting. Perhaps this is different for PIO, but I cannot find any statements about this in the paper you link.
I guess finetuning a model to produce truthful statements directly is nontrivial (especially without a discriminator model) because there are many possible truthful and many possible false responses to a question?
I think the actual solution is somewhere in between:If we assume calibrated uncertainty, ignore generalization and assume we can perfectly fit the training data, the total cost should be reduced by (1-the probability assigned to the predicted class) * the cost of misclassifying the not predicted (minority) class as the predicted one (majority): If our classifier already predicted the right class, nothing happens, but otherwise we change our prediction to the other class and reduce the total cost.While this does not depend on the decision threshold, it does depend on the costs we assign to different misclassifications (in the special case of equal costs, the maximal probability that can be reached by the minority/non-predicted class is 0.5).Edit: This was wrong, the decision threshold is still implicit at 50% in the first paragraph (as cued by the words "majority" and "minority") : If you apply a 99% decision threshold on a calibrated model, the highest probability you can get for "input is actually unsafe" if your threshold model predicts "safe" is 1%; (now) obviously, you do only get to move examples from predicted "unsafe" to predicted "safe" if you sample close to the 50% threshold, which does not give you much if falsely labelling things as unsafe is not very costly compared to falsely labelling things as safe.
If we however assume that retraining will only shift the prediction probability by epsilon rather than fully flipping the label, we want to minimize the cost from above, subject to only targeting predictions that are epsilon-close to the threshold (as otherwise there won't be any label flip). In the limit of epsilon->0, we thus should target the prediction threshold rather than 50% (independent of the cost).
In reality, the extent to which predictions will get affected by retraining is certainly more complicated than suggested by these toy models (and we are still only greedily optimizing and completely ignoring generalization). But it might still be useful to think about which of these assumptions seems more realistic.